| Databázové systémy |

| Kategorie : Počítačové sítě | Podkategorie : | Tutoriálů: 1 |
| POPIS:
Systém řízení báze dat je softwarové vybavení, které zajišťuje práci s databází, tzn. tvoří rozhraní mezi aplikačními programy a uloženými daty. Občas se pojem zaměňuje s pojmem databázový systém. Termín Databázový systém jako celek je považován DBMS dohromady s bází dat. |
DATABÁZOVÉ SYSTÉMY
Základní pojmy
Klíčová slova: Data, informace, databáze, datový model, SŘBD, databázové jazyky, architektura.
Potřebný čas: 4 hodiny.
Při studiu databázových systémů narazíme často na problematiku, kterou systematicky zpracovávají jiné předměty informatiky, ale většinou se jedná o specifické rozšíření a integrující pohled. Jsou to například oblasti a předměty jako teoretická informatika a algoritmizace, operační a distribuované systémy, programovací jazyky, projektování a vývoj softwaru, matematické disciplíny – algebra, logika, práce s mnoţinami. V textu se předpokládá alespoň orientační přehled mimo jiné o organizaci dat, metodách přístupu k datům, datové a funkční analýze, HW (disky, paměti) počítače a jeho řízení atd..
Průvodce studiem
Studium databázových systémů (DBS) můžeme členit do tří širokých oblastí podle úhlu uživatelského nebo vývojářského pohledu a hloubce a rozsahu řešených problémů.
1.Návrh databáze – Řeší problém, jak navrhnout strukturu informací, jaký model pro popis vztahů, typů, jaké hodnoty ukládat.
2.Programování databáze - Řeší problém, jak konkrétně, jakým programovacím jazykem, manipulovat s daty a získávat informace, pracovat s transakcemi, atd. v aplikacích i v návaznosti na konvenční programovací jazyky.
3.Implementace databáze - Řeší problém, jak navrhnout program, který efektivně řeší všechny důležité databázové procesy a operace, jako je fyzická struktura uložení dat, rychlý přístup k datům, efektivní zpracování dotazu, transakcí, atd..
Abychom poznali specifiku databázové technologie, seznámíme se s vybranými pojmy.
Úvod do databázové technologie
Pojem databáze
Moderní pojem informační technologie představuje unifikovaný soubor metod a nástrojů pro vývoj software informačních systémů, které zpracovávají data (realizují sběr, uloţení a uchování, zpracování, vyhledávání) a většinou ve své architektuře pouţívají databázovou technologii. Od historicky prvních síťových a hierarchických databázových systémů se přešlo na relační systémy. Na relačních komerčních systémech v průběhu několika desetiletí vývoje a vyuţití došlo k odstranění hlavních problémů, většina postupů byla správně definována i úspěšně a efektivně implementována. Tím se tato klasická technologie stala nesmírně robustní a pro jistou třídu aplikací i do budoucna perspektivní. Další vývoj pokračuje paralelně ve formě čistě objektových systémů, které se prosazují hlavně ve speciálních aplikacích (CAD, grafické systémy) a největší perspektiva se dává evolučnímu pokračování relačních systémů - relačně-objektovým systémům. I klasická relační technologie se dále rozvíjí – příkladem jsou paralelní architektury pro zvýšení výkonu SŘBD, deduktivní databáze a expertní systémy.
S rozvojem technologie krystalizují za klasickými IS s databázovými aplikacemi (katalogy, bankovnictví, knihovny, sklady, doprava, …) další aplikace se sloţitě strukturovanými daty :
Multimediální databáze – informace ve formě ( i kombinované ) dokumentů - textů, obrázků, zvuků, videa
Geografické informační systémy – data ve formě map
Podnikové systémy pro podporu analýzy, řízení a rozhodování, vyuţívající technologii datových skladů a OLAP s moţností dolování dat (data minig)
Komerční obchodování na internetu , práce s XML daty
Řízení podnikových procesů – workflow
Rozvoj databázové technologie je reakcí na potřebu efektivně, za pomoci počítačů, zpracovávat různé rozsáhlé agendy, se zaměřením na vyhledávání a aktualizaci dat. Vyhledávání představuje nalezení takových informací - záznamů, které vyhovují podmínkám na poţadovaná data. Podmínky jsou formulovány ve formě dotazu ve vhodném dotazovacím jazyce a odpovědí je typicky podmnoţina z uloţených záznamů (případně ještě zpracovaných – výpočtem z uloţených dat získáme odvozené informace). Výsledné údaje můţeme třídit dle různých kritérií, prezentovat ve formě tištěných výstupních sestav. Aktualizace zajišťuje změnu hodnot vlastností objektů nebo zrušení či přidání nového objektu ( záznamu) tak, aby informace korespondovaly s realitou. Aby popsané operace byly efektivní, musí být data vhodně uspořádaná a organizovaná na vhodném médiu.
Existuje mnoho způsobů, jak definovat pojem databáze, například: Databáze je úloţiště informací, udrţované v čase, v počítačově zpracovatelné formě.
Průvodce studiem
Databáze – sdílená kolekce logicky souvisejících dat i s popisem své datové struktury, organizovaná pro optimální manipulaci s perzistentními daty a získávání informací pro potřeby informačního systému.
Pro základní představu porovnejme zjednodušené analogie klasické a elektronické verze na příkladu kartotéky části knihovny ( je pouţit relační model dat, který data uchovává ve formě tabulek):
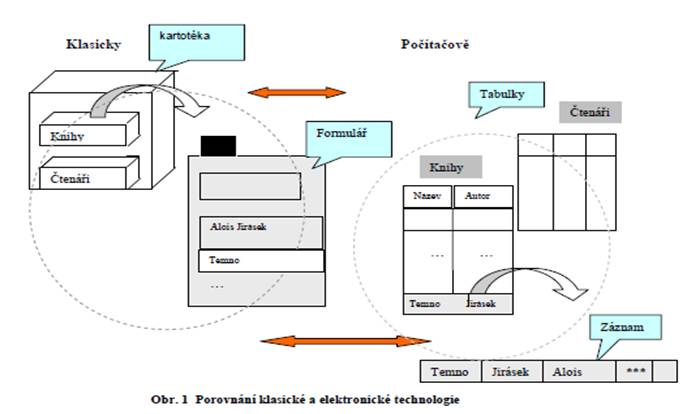
Výše uvedený příklad je typický svou „plochou“ datovou strukturou, přirozeně transformující data aplikace do dvourozměrných tabulek. Takto pojatá data – tabulky- jsou častou základní logickou datovou strukturou počítačem podporovaných informačních technologií. Programové vybavení, zajišťující perzistentní uloţení a bezchybnou údrţbu dat na médiích, programové rozhraní pro bezpečný přístup více uţivatelů nebo aplikací k manipulacím s daty, získávání informací z kolekcí dat vhodným dotazovacím jazykem, správu transakcí a další funkce, se nazývá systém řízení báze dat – SŘBD. Vše podstatné se v databázové technologii točí kolem dat.
Data v databázi si můţeme představit jako známá fakta, která nás zajímají, s poměrně pevnou strukturou, uloţená trvale v počítači. Mezi nejdůleţitější charakteristiky dat v databázích patří
Perzistence – data přetrvávají dlouhodobě od jedné operace ke druhé, nezávisle na pouţitých programech
Velké mnoţství – operace typicky nevystačí s vnitřní pamětí, proto pouţití sofistikovaných algoritmů při manipulaci s daty
Správnost, nerozpornost – snaha odhalením nejrůznějších chyb v datech při vkládání nebo úpravě databáze zachovat korespondenci s realitou, vztaţenou ke konkrétnímu času, ne nutně k nejaktuálnějšímu (realizováno pomocí integritních omezení)
Spolehlivost – data je moţné po poruše počítače zrekonstruovat
Sdílení – s daty pracuje typicky více uţivatelů
Bezpečnost – moţnost omezit přístup k datům a operacím s nimi
Integrace – spojení několika poţadovaných pohledů do komplexní datové struktury
Konzistence – identická data mohou být dočasně nebo trvale uloţena na více místech, ale musí mít stejnou hodnotu
S efektivitou – rychlostí operací – je spojena organizace dat. Klasicky je základem zpracování na fyzické úrovni soubor, kaţdý objekt reality je popsán záznamem souboru, vlastnost objektu je poloţkou záznamu, která je uloţená ve formátu vybraného předdefinovaného typu. Mnoţinu datových souborů, uchovávajících data o nějakém vymezeném úseku reality, nazýváme databází. Instance databáze je kolekce informací uloţených v databázi, nerozporná v konkrétním čase, definuje stav.
Schéma konkrétní databáze – informace o metadatech (data o datech, uloţena odděleně v katalogu dat), popisuje strukturu dat v databázi - je definováno prostředky pouţitého datového modelu, se kterým pracuje SŘBD.
Datový model je soubor prostředků a konceptů, popisujících data (sémantiku, strukturu, vztahy, integritní omezení) na určité úrovni abstrakce. Obvykle rozlišujeme tři komponenty – strukturální, operační a specifikace integritních omezení. Konkrétní datový model souvisí s úrovní abstrakce, s pohledem na data v procesu vývoje aplikace – od vymezení poţadované části reality ze zadání aţ po fyzické uloţení v počítači. V průběhu vývoje IS se prakticky můţe pouţít mnoho různých modelů v závislosti na metodologiích, informačních technologiích, architektuře IS, atd., typická je potřeba přechodů z jednoho typu modelů do druhého v průběhu vývoje softwaru IS s pouţitím vhodných transformačních pravidel. Moţné rozdělení databázových modelů :
konceptuální ( data na úrovni pohledů a konceptů ) - zaloţené na objektech (ER model, sémantický model, OO model, funkcionální datový model), na vysoké úrovni abstrakce, bez bliţší specifikace budoucí implementace. Je výsledkem datové analýzy, prostředníkem mezi zadavatelem a analytikem v procesu formulace a zpřesňování zadání. Spolu s funkčními závislostmi mezi atributy rozhodujícím způsobem určují interpretaci dat v databázi – jejich sémantiku

logické - zaloţené na záznamech ( znalosti seznamů vlastností - atributů <a1, a2, …, an >), které tvoří logický celek (n-tici) jako obraz vlastností abstraktního objektu, prostředky a formu určuje typ datového modelu pouţitého SŘBD. Mezi historicky první řadíme modely
hierarchický, síťový – vztah mezi záznamy je v implementaci definován pomocí ukazatelů a data tvoří skupiny záznamů s topologií příslušných grafů – stromu, nebo obecnější sítě.
Stále nejrozšířenější je následující model
relační – Záznamy stejného entitního typu jsou logicky organizovány ve formě dvoudimenzionálních tabulek, vztah mezi záznamy je definován hodnotami vazebních atributů (cizích klíčů), obecně v samostatných tabulkách. Relační databázi tvoří jedna, nebo několik tabulek. Tabulka uchovává informace o skupině podobných objektů reálného světa, např. o knihách. Informace o jednom objektu je na jednom řádku tabulky. Pořadí řádků v tabulce není důleţité, nenese ţádnou informaci. Sloupec tabulky uchovává informace o jedné nestrukturované vlastnosti objektu.
Př. Definice relací – tabulek ( představuje databázové relační schéma, vzniklé transformací z předchozího ER diagramu )
Kniha (IDk : int, autor : char(20), název : char(20))
Půjčena (IDk : int, IDč : int, datum : date)
Čtenář (IDč : int, jméno : char(20), adresa_ulice : char(20), adresa_číslo_pop : char(20))

Základní operace v databázi, manipulující s daty, jsou například:
- vloţení informací o nové knize (INSERT INTO Kniha VALUES (6, ‘Čapek’, ‘Matka’)
- odstranění informací o vyřazené knize (DELETE FROM Kniha WHERE IDk = 5)
- oprava, aktualizace údaje existující poloţky (UPDATE Kniha SET stav = ‘zapůjčen’ WHERE IDk = 63)
- dotaz na výběr knih s jistou vlastností – např. rok vydání (SELECT * FROM Kniha WHERE vydání = 1992)
fyzické (data na fyzické úrovni, struktura uloţení v paměti – na disku, pomocné podpůrné vyhledávací struktury – indexy, …)
Průvodce studiem
Databázové systémy můžeme rozdělit na klasické, souborově orientované s navigací pomocí ukazatelů – hierarchické a síťové, pracující s tabulkami – relační a na nové směry a přístupy v databázové technologii, což mohou reprezentovat rozšířené relační systémy ( relačně- objektové), čistě objektově orientované, XML databáze, deduktivní databáze ( Datalog ) a distribuované databáze
Databázový systém (DBS) zahrnuje:
technické prostředky – spolu s dalšími faktory a poţadavky uţivatele limitují moţnou sloţitost architektury IS nebo častěji je HW návrhem určen. Komerční DBS pokrývají širokou škálu moţností s různým stupněm úplnosti a efektivity splnění poţadavků, kladených na SŘBD, výkonem, cenou, charakterem aplikace, atd.. Setkáváme se s jednoduššími souborovými systémy ( např. dBASE, FoxPro, Microsoft Access) na jedné straně aţ po komplexní ( a nákladné) systémy (DB2, Oracle, Microsoft SQL server)
programové vybavení (SŘBD, vývojové nástroje)
data uloţená v databázi (DB)
uţivatele – ty můţeme klasifikovat podle různých kritérií (oprávnění k operacím, znalost a úroveň řízení DBS i aplikace, … ) do typových skupin např.
1. administrátor, správce dat - koordinuje všechny aktivity v databázovém systému, zakládá, modifikuje uţivatele, rozhoduje o tom, která data a jak budou v bázi uloţena – definuje schéma databáze a integritní omezení, určuje
schéma uloţení dat a metody přístupu k datům, pokud je to nutné, realizuje poţadované změny, modifikuje struktury dat, přiděluje přístupová práva k datům i operacím, sleduje výkon a chování DB serveru, zálohuje, rekonstruuje databáze v případě jejího poškození, …
2. aplikační programátor (tvůrce aplikací) - programuje aplikační programy nad definovanými datovými strukturami, sloţitější dotazy a transakce pouţitím DML v hostitelském jazyku nebo jazyky 4. generace.
3. příleţitostný uţivatel - umí prostřednictvím dotazovacího jazyka formulovat vlastní specifický dotaz nebo jinak manipuluje s daty
4. naivní uţivatel - (obvykle neprogramátor), který prostřednictvím aplikačních programů pracuje s databází a pouţívá databázi jako informační systém pro ukládání, zpracování a vyhledávání informací
Pro úplnost - jedno z dalších kritérií dělení DBS je na jedno-uţivatelské (hlavně dříve na PC) a více-uţivatelské.
Schematicky zkracujeme definici jako spojení SŘBD a dat uloţených v databázi
databázový systém = systém řízení bází dat + databáze
Základní paradigma – existence dat v databázi je nezávislá na aplikačních programech. To umoţňuje na aplikaci nezávislý popis dat v datovém slovníku ( např. v systémových tabulkách relačních systémů)
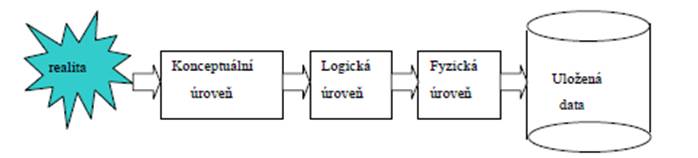
1.1.2 Úrovně abstrakce
Při vývoji softwaru IS modelujeme datové struktury způsobem, který nejlépe vyhovuje příslušné fázi ţivotního cyklu programu a míře abstraktnosti. Nejvyšší úroveň abstrakce tvoří reálný svět, ze kterého vyčleňujeme takové typy objektů a údaje o objektech, které souvisí s fakty, jeţ chceme zahrnout do informačního systému. Tuto úroveň definuje zadavatel na základě integrace dílčích uţivatelských pohledů a upřesňuje se v procesu analýzy iterací s vývojem funkční analýzy IS. Pohledy jednotlivých uţivatelů tvoří externí schémata Výsledkem datové analýzy a pouţitím konceptuálního modelu vznikne informační struktura zvaná konceptuální schéma databáze, jeţ je nezávislé na pozdějším logickém databázovém schématu. Databázové schéma je realizací, výsledkem transformace konceptuálního schématu prostřednictvím konstruktů příslušného datového modelu a představuje logickou – databázovou úroveň abstrakce. Popisuje definice datových struktur a jejich vazeb pomocí prostředků pouţitého SŘBD. Externí schémata se na databázové úrovni mohou realizovat ve formě virtuálních pohledů - většinou majících podporu SŘBD v jazycích definujících data (např. databázový objekt view v SQL relačních systémů) ve formě datových struktur, optimálně navrţených pro typovou skupinu uţivatelů, vyuţívajících IS podobným způsobem.
Interní schéma databáze popisuje nejniţší fyzickou úroveň abstrakce - uloţení dat na médiu počítače. Definuje fyzické záznamy, fyzickou reprezentaci jejich poloţek, sdruţování záznamů do souborů, charakteristiky těchto souborů. Souvisí bezprostředně s pouţitým SŘBD a moţností explicitně určovat fyzické uloţení nastavením jeho parametrů nebo pouţitím příslušných příkazů. Schematicky :
Průvodce studiem
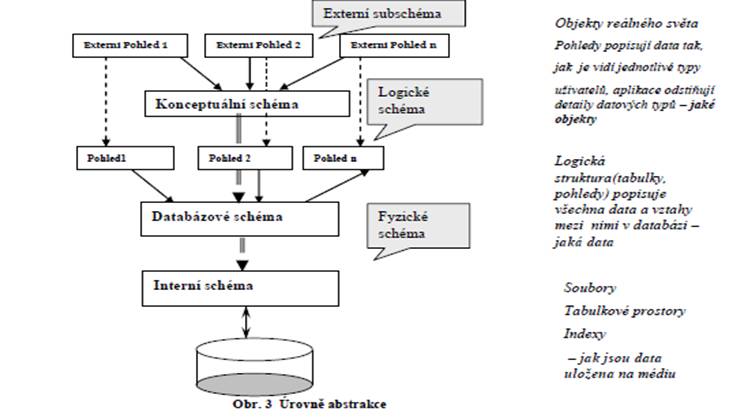
ANSI/SPARC architektura definuje tři úrovně: 1.externí úroveň nabízí uživatelský pohled do databáze a popisuje části reality z pohledu každého uživatele zvlášť(mnoho pohledů). 2.konceptuální úroveň integruje data do společného pohledu, určuje jaká data jsou uložena v databázi a jaké jsou mezi nimi vztahy ( jedno konceptuální schéma) 3.interní úroveň popisuje fyzickou reprezentaci dat v počítači ( jedno fyzické schéma)
- Původně vychází z ANSI/SPARC architektury (1976), definuje
tři úrovně pohledu na data
Historický vývoj zpracování dat
Ilustrativní z pohledu funkce a vývoje programové vrstvy SŘBD je historický přehled pouţívaných metod, který také úzce souvisí se stupněm rozvoje hardwaru a architektury výpočetních systémů.
Průvodce studiem
Souborový systém – kolekce aplikačních programů, které zajišťují služby pro uživatele. Každý program definuje a udržuje svá vlastní data.
50. léta :
Počátečním etapám programového řešení úloh tohoto typu se říká agendové zpracování dat. Vybrané charakteristiky tohoto přístupu:
aplikační programy řeší jednotlivé úlohy - uloţení dat na médium, zpracování dat, tisk sestav, …
soubor programů tvoří ucelenou agendu
plná závislost dat a programů ( kaţdý program řeší nejen vlastní aplikační problém, ale i otázky fyzického uloţení dat na médiu; navazující úlohy musí respektovat jiţ vytvořené fyzické struktury dat)
nízká efektivnost datových struktur i programů
zpracování v dávkách : - data se ručně zapisují do formulářů
- z formulářů se zaznamenávají na vstupní médium pro počítač
- formou primárního zpracování se data načtou do počítače
- řadou sekundárních zpracování se pak nad daty provádějí výpočty, výběry, tisky sestav …
řešení ucelených problémových oblastí v jedné agendě ( data se sbírají speciálně pro tuto agendu)
mezi různými agendami nejsou ţádné nebo jen minimální vazby
typická architektura aplikace ( vše v programu)
Pouţití specializovaných jazyků (Pl /1, COBOL)
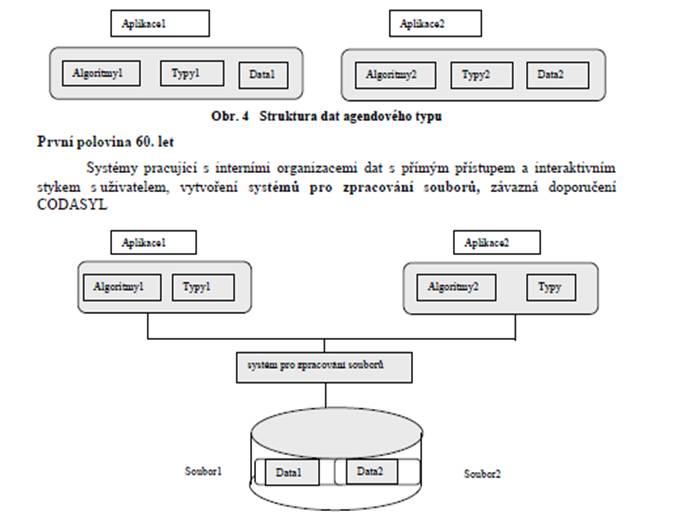
Obr. 5 Struktura dat systémů pro zpracování souborů
Nevýhody dosavadních řešení:
Soubory navrţeny podle potřeb konkrétních programů – malá flexibilita, nízká úroveň abstrakce při pohledu na data – jednoduché datové modely
Velká redundance dat (aplikační programy vytvářené různými programátory způsobí opakování informací ve více souborech )
Nekonzistence dat ( při změnách hodnot se oprava poloţky neprovede na všech místech, kde je opakující se informace zapsána)
Problémy se zabezpečením integrity dat (uloţená data musí být většinou aktuální, vyjadřovat skutečnost z reálného světa, vztaţenou k jistému časovému okamţiku, implementace integritních omezení)
Špatná dosaţitelnost dat – izolovanost dat ( data rozptýlena v různých agendách , různé formáty ekvivalentních dat, problémy s neplánovanými dotazy …)
Problémy se specifikací a zajištěním ochrany dat (proti získání informací z vnějšku systému, ale i mezi uţivateli), souběţného přístupu více uţivatelů
Reakcí ve vývoji je základní princip - tendence oddělení dat a jejich definic od aplikačních programů.
Druhá polovina 60. let a 70. léta
vytvoření prvních systémů pro řízení baze dat – SŘBD, vývojem ze souborových systémů. DBS podporovaly různé datové modely - síťový a hierarchický, později relační model dat (Edgar Codd )
data centralizovaná
jednotný přístup k informacím, rozvoj speciálních jazyků a rozhraní
popis dat oddělen od aplikačních programů
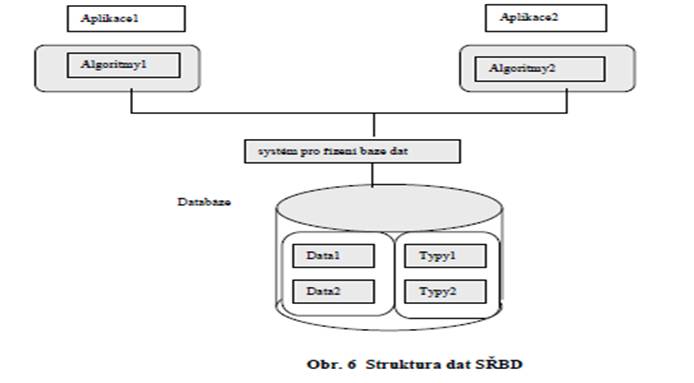
1.1.4 Systém Řízení Báze Dat – SŘBD
SŘBD je kolekce programů, které tvoří rozhraní mezi aplikačními programy a uloţenými daty.
Základní funkce:
na základě pouţitého datového modelu:
- umoţňuje vytvořit novou databázi a definuje její schéma a data (popis souborů, záznamů, poloţek, typů, velikostí, vztahů mezi záznamy, indexů ),
- provádí validaci dat (kontrola typu, rozsahu, konzistence, nerozpornosti ),
- případně modifikuje schéma, strukturu dat (vytváří, modifikuje slovník dat)
určuje strukturu uloţení (i pro velké mnoţství) dat
manipuluje s daty, hlavně umoţňuje dotazování, volí metody přístupu (optimalizace), zajišťuje výkonnost
zajišťuje autorizaci a bezpečnost
souběţný přístup
zajišťuje zotavení po poruše
kontroluje integritu dat
zajišťuje správu transakcí
Průvodce studiem
SŘBD – softwarový systém, umožňující definovat, vytvořit, udržovat a řídit přístup do databáze.
Hlavní výhody a poţadavky na SŘBD
1. Vyšší datová abstrakce – manipulace s formalizovanými strukturami na vyšší, logické úrovni abstrakce
2. Nezávislost dat – schopnost modifikovat definici schématu bez vlivu na schéma vyšší úrovně abstrakce. Analogie s abstraktními datovými typy, detaily implementace jsou skryty.
Průvodce studiem
Nezávislost dat: Fyzická nezávislost dat - změna fyzického schématu neovlivní aplikační programy
( sem patří rovněž např. přidání a zrušení indexů, změna klastrů)
Logická nezávislost dat - změna logického schématu neovlivní aplikační programy
( sem patří rovněž např. přidání, modifikace a zrušení entitních typů nebo vazeb)
3. Centralizovaná administrace dat a popis struktury.
4. Moţnost formulovat ad hoc dotazy mimo aplikační programy.
Většina SŘBD má vlastní speciální databázové jazyky, které zajišťují funkčnost prostřednictvím příkazů a předdefinovaných standardních funkcí. V relačních systémech je prakticky standardem jazyk SQL. Moţné dělení jazyků (případně příkazů komplexního jazyka) do kategorií :
1. jazyk pro definici dat (JDD) - definice, modifikace a rušení entitního typu, vazby mezi entitními typy a atributů, s pouţitím logických jmen a datových typů nebo domén (předdefinovaných nebo uţivatelských), definuje některá systémová integritní omezení
2. jazyky pro manipulaci dat (JMD) - manipulace s atributy, entitami a jejich vazbami, mnoţinami entit, realizují operace typu INSERT, UPDATE, DELETE na logické úrovni. Výběr dat z databáze (operace SELECT) zajišťuje dotazovací jazyk, který je buď součástí JMD, nebo funguje samostatně. Je většinou neprocedurální (formulujeme jen poţadavky dotazu, ne postup, algoritmus získání informací )
3. jazyk pro řízení přístupu k datům – prostředky pro realizaci změn schématu a dat databáze se zaměřením na definici oprávnění operací pro kaţdého uţivatele
4. jazyk pro řízení transakcí
5. jazyky pro zápis algoritmu
v hostitelském jazyce (Cobol, C, Java, ...), pak jsou výše uvedené JDD a JDM vytvořeny jako procedury v hostitelském jazyce a celý SŘBD tvoří nadstavbu tohoto jazyka;
vlastní speciální jazyk SŘBD, obsahující příkazy JDD a JMD a navíc programové struktury pro provádění algoritmů - příkazy pro větvení a cykly, někdy podporující i vývoj prezentační vrstvy aplikace.
6. jazyky čtvrté generace ( 4GLs ) – se stávají pravidelnou součástí hlavně aplikačních vývojových prostředků. Patří sem generátory celých aplikací, formulářů, dotazů, výstupních sestav, grafických výstupů, ale i datových tabulek.
Původně byly SŘBD velké a drahé programové systémy na rozsáhlých a vybavených počítačích. Vývoj sekundárních pamětí a jejich cena dovoluje nasazení vhodných SŘBD na všechny třídy počítačů – od nejmenších systémů, většinou nad jednoduchými datovými soubory, aţ po nejvýkonnější paralelní architektury, zpracovávající TB informací.
Průvodce studiem
Proč použít databáze?
- pro datovou nezávislost a efektivní přístup
- urychlují a standardizují návrh aplikací
- integrují data a zajišťují bezpečnost
- zajišťují snadnou administraci a minimální redundanci
- umožňují souběžný přístup a zotavení po poruše
1.1.5 Architektura DBS
Pojem architektura DBS, případně IS zahrnuje mnoho moţných úhlů pohledu v závislosti na kontextu a etapě návrhu. Tradiční je některá varianta centralizovaného modulárního funkčního schématu relačního databázového stroje, ve které můţeme rozlišit vrstvy - pro optimalizaci a provedení dotazu, relační operace, metody přístupu k souborům, správce vyrovnávací paměti a správce disku.
Například:

Obr. 7 Funkční architektura DBS
Překladač JDD zpracovává definici a změny schématu databáze a ukládá je do katalogu dat. Run-time procesor pracuje s databází při běhu programu. Manaţer dat spolupracuje s operačním systémem případně podsystémy vnitřní a vyrovnávací paměti a řízení disků na přenosu dat. Procesor dotazu interpretuje nebo překládá dotaz do optimalizované podoby a předá ho na vyhodnocení. Nejniţší úroveň tvoří subsystém pro ovládání souborů. Zahrnuje fyzickou organizaci datových souborů, vlastní uloţení dat na vnějším médiu a realizaci přenosů dat s pamětí prostřednictvím příslušných manaţerů. Na disku jsou uloţeny informace čtyř kategorií
1. Data – obsah vlastní databáze
2. metadata ve slovníku dat – popis schématu databáze a integritních omezení
3. statistiky – informace o vlastnostech uloţených dat, jako je velikost, charakter hodnot, vzájemné vazby
4. indexy – podpora efektivního přístupu k datům
Mezi nejdůleţitější patří architektura z hlediska topologie rozdělení základních typů sluţeb ve vrstvách programového vybavení IS. Sluţby můţeme rozdělit na :
1. prezentační – vstup / výstupní zařízení zobrazuje informace( určuje co a jak uţivatel vidí), reakce myši, klávesnice, …
2. prezentační logika – interakce uţivatele s aplikací (reprezentuje hierarchii formulářů a menu, logiku jejich vztahů)
3. logika aplikace – realizuje aplikační operace a funkce(výpočty, rozhodování) , „prostředky (jazykem) aplikace“
4. logika dat – podpora logiky aplikace operacemi, které mají být prováděny s databází, vyjádřená jazykem SŘBD(SQL – SELECT, INSERT, UPDATE, DELETE)
5. datové sluţby – operace s databází vně logiky dat, např. definice dat, transakce
6. zpracování souborů – operace na fyzické úrovni, získání dat z disku, práce s vyrovnávací pamětí, … (většinou poskytuje operační systém)
Průvodce studiem
Typický SŘBD se skládá s jednotlivých vrstev – např. 1. Optimalizace a provádění dotazů, 2. Provádění relačních operátorů, 3. Správa souborů a přístupové metody, 4. Správa vyrovnávacích pamětí, 5. Správa disku. Vrstvy 2-5 musí umožnit paralelizmus řízení a zotavení po poruše.
Typické architektury mají historický kontext s návazností na stupeň vývoje HW i SW včetně operačních a síťových systémů. Některé vybrané příklady:
Centrální architektura:V/V (neinteligentní) terminál (sluţby 1) – sálový počítač (sluţby 2-6): sdílení systémových prostředků, ale primitivní textové rozhraní, problematická rozšiřitelnost o další klienty, zátěţ sítě o prezentační data
File-server, databáze jako soubory: stanice, např. PC (sluţby 1-5) - file-server (sluţba 6) : umoţňují rozšiřitelnost o nové klienty, ale velké zatíţení sítě, neefektivní souběţný přístup, citlivé na změnu logiky dat.
Klient – server má několik variant, je nejpouţívanější, znamená dekompozici funkcionality a jistou distribuci dat a databázového softwaru mezi databázovým serverem a jeho klientem. To umoţňuje aplikacím škálování zdrojů – horizontální ( aplikaci lze zpřístupnit více DB serverů) nebo vertikální ( nasazení levnějšího méně výkonného počítače pro klienta a výkonného pro server ). Komunikace mezi klientem a serverem probíhá pomocí příkazů SQL s odpovědí typicky ve formě relačních dat. Centralizace architektury podporuje ochranu dat před ztrátou, nebo zneuţitím.
Klient – server : stanice (sluţby 1-4)- DB server (sluţby 5-6) – mnoho variant architektury, ve které poţadavek jednoho procesu (klienta) je poslán k provedení na druhý proces (server), problémy s efektivitou při souběţném přístupu více uţivatelů : typicky heterogenní prostředí
Klient – server se třemi vrstvami : stanice (sluţby 1-2) - aplikační server (sluţba 3)- DB-server (sluţby 4-6)
Klient – server s více vrstvami : tenký web klient (sluţby 1) – web-server (sluţba 2) - aplikační server (sluţba 3)- DB-server (sluţby 4-6)
Dále existuje mnoho moţností, jak sluţby rozdělit nebo netypicky přesunout (např. sluţba 3 implementována v uloţených procedurách na DB serveru nebo na web serveru). Samostatnou kapitolou jsou distribuované DBS, které umoţňují fyzické rozdělení nebo replikaci dat na více uzlech sítě.
Shrnutí Databázové systémy tvoří většinou základ pro datovou úroveň v architektuře informačních systémů. Předchůdci moderních DBS byly souborové systémy s aplikačními programy se sluţbami zajišťujícími například tvorbu výstupních sestav, s izolovanými vlastními daty v kaţdém aplikačním programu. Problémy tohoto řešení – např. velká redundance a izolovanost dat, závislost na fyzické struktuře uloţení, nedostatečná podpora paralelního transakčního zpracování, nemoţnost jednoduše modifikovat menší části dat, atd. vedly postupně k vývoji systému řízení báze dat. SŘBD je programová vrstva, která podporuje efektivní správu velkých perzistentních dat, umoţňuje získání informací z databáze prostřednictvím dotazovacích jazyků, s moţností pracovat souběţně v transakcích s maximální vzájemnou podporou nezávislosti, izolovanosti a konzistence. Uţivatel komunikuje se SŘBD prostřednictvím databázových jazyků, ve kterých jsou jednotlivé příkazy podle účelu děleny na části jazyka definující data ( JDD) s moţností vytvořit a modifikovat databázové objekty a jazyka manipulující s daty ( JMD ), který umoţňuje provádění operací insert, update, delete a select. Do kontextu DBS můţeme zahrnout hardware – počítač na kterém DBS pracuje, software – SŘBD, operační systém, aplikační programy, dále data a procedury a nakonec různé skupiny uţivatelů – administrátor databáze, aplikační programátor, běţný uţivatel a podobně. Mezi nejdůleţitější moduly SŘBD patří manaţer paměti a transakcí a modul zpracování a optimalizace dotazu. Historicky první generaci databázových, souborově orientovaných systémů reprezentují hierarchické a síťové – podle CODASYL modely dat. Nejrozšířenější datový model databázových systémů je relační model, který informace organizuje ve formě tabulek a pro programování nejčastěji pouţívá jazyk SQL, který umoţňuje definovat a modifikovat datovou strukturu databáze, manipulovat s daty a administrovat databázový systém s moţností vytvářet i modifikovat všechny databázové objekty a určovat oprávnění k operacím. Perzistence dat je zajištěna uloţením databáze na disku. Nejčastější architektura databázových systémů je typu klient – server, s podporou uţivatelského rozhraní pro přístup do databáze na obou stranách, na klientovi i na serveru.
Pojmy k zapamatování
Databázový systém, vlastnosti databázových dat, historický přístup
Systém řízení báze dat, transakce
Datový model, úrovně abstrakce
Databázové jazyky, SQL
Architektura systému
2 Konceptuální modelování
Studijní cíle: Po prostudování kapitoly by studující měl porozumět modelování datové struktury databázové aplikace pomocí ER modelu, popsat základní koncept ER modelu. Měl by definovat a na jednoduchých úlohách pouţít konstrukty ER modelu při návrhu datové struktury ze zadání, popsat integritní omezení v ER modelu. Měl by vysvětlit pojem slabá entita a ISA hierarchie.
Klíčová slova: ER model, entita, atribut, vztah (relace), identifikační ( primární ) klíč, kardinalita, povinné členství ve vztahu, ISA hierarchie.
Potřebný čas: 2.hodiny
Rozsáhlejší projekt IS i malá aplikace prochází při vývoji typickými fázemi ţivotního cyklu:
Analýza (datová a funkční) – odpovídá na otázky : Proč vyvíjíme aplikaci? Kdo ji bude pouţívat? Jaký bude mít přínos pro uţivatele? Jaké funkce a potřeby bude splňovat? Kompletní funkčnost systému získáme z analýzy poţadavků, z formalizovaného zadání, konzultacemi s uţivateli.
Návrh – je nejdůleţitější fáze. Návrh databáze je prováděn modelováním datové struktury pouţitím ER diagramu tak, aby vyhovoval funkčním poţadavkům IS, logické schéma databáze se nakonec transformuje do fyzických struktur databázového systému.
Vývoj, Implementace – v této fázi se tvoří programy a datové struktury podle návrhu, na návrh a vývoj databáze navazuje vývoj aplikačních programů. Vytváří se prototypy z návrhu, po ověření správnosti následuje implementace aplikace.
Testování – je důleţitá fáze ověřování očekávaných funkcí systému v reálných podmínkách. Případné chyby jsou opraveny a znovu je prováděno testování.
Údrţba - je fáze, ve které se sledují vlastnosti systému, dolaďuje se, v průběhu času se mění poţadavky a systém se modifikuje, reorganizuje.
S rozvojem informačních technologií se mění metodologie i metody a prostředky. Konceptuální návrh databáze začíná analýzou, ze které vyplyne, jaké informace je nutno uloţit v databázi a v jaké struktuře. Komplexnější přístup k problematice analýzy a návrhu softwaru je jistě náplní speciálních předmětů, následující řádky jsou úvodem k typicky databázovým prostředkům pro konceptuální modelování formou ER-modelu.
Dá se říci, ţe v databázových aplikacích (soustředíme se na řešení datové struktury na úrovni relačních SŘBD) se často setkáváme s klasickými přístupy – konceptuální ER model nebo rozšířený EER model se transformuje do relační databáze, ale rozšiřuje se i objektově orientovaný návrh, pouţívající UML a nové metody návrhu (diagram tříd, … ). Výhodné je transformovat objektový návrh do objektového nebo objektově-relačního databázového systému. Důvody obliby ER modelu hledejme hlavně v převaţujících plochých typech aplikací, optimálně vyuţívající relační systémy a setrvačnosti v pouţívání osvědčených postupů, atd.. V této kapitole se soustředíme na první dvě fáze, které řeší základní problémy – jak v databázi popsat sémantiku dat a jak data strukturovat. Jednoznačnost a smysluplnost sémantiky konceptuálního schématu určuje jeho korektnost.
2.1 Analýza a návrh IS
Výstupem datové analýzy je konceptuální schéma databáze, jako výsledek iteračního procesu, jehoţ vstupem jsou poţadavky různých ( skupin) uţivatelů (charakterizují objekty aplikační domény, parciální data a funkce). V průběhu procesu se prvotní návrhy datové struktury integrují a modifikují podle toho, jak vyhovují poţadavkům funkční analýzy. Klasickými strukturovanými nástroji funkční analýzy jsou například diagram datových toků (DFD) a stavový diagram.

Principy konceptuálních modelů:
- oddělení konceptuální a interní úrovně
- orientace na objekty, entity ne na záznamy a soubory
- bohatší koncept, v relačním modelu jsou relace vyuţívány na „všechno“, reprezentují entity, vícehodnotové atributy, asociace, agregace, dědičnost, …
- moţnost vyuţít úrovně abstrakce v komplexních objektech k zakrytí detailů, moţnost modelovat přímo aplikační objekty.
- funkcionální podstata vztahů (atribut nebo funkce je jediným konstruktem)
- ISA hierarchie ( práce s nadtypy a podtypy)
- Hierarchický mechanismus (objekty lze konstruovat z jiných objektů, formou agregace, seskupováním do mnoţin, tříd)
Průvodce studiem
Konceptuální návrh řeší, prostřednictvím ER modelu otázky: Jaké entity ( objekty ) a v jakých vztazích a struktuře jsou v analyzovaném systému ? Jaké informace o těchto entitách, případně vztazích se mají uložit do databáze ? Jakým integritním omezením musí vyhovovat data v databázi ? Také prakticky - jak navrhnout ER diagram tak, aby byl srozumitelný a přehledný ( aby na některých úrovních zakrýval příliš velké detaily), aby jeho transformace do relačního modelu byla optimální ?
2.2 ER Model
ER model chápe realitu, případně její sledovanou část, jako mnoţinu objektů (entity) a vztahů mezi nimi (relationship). To představuje přirozený, ale zjednodušený pohled na svět. Model pracuje s těmito konstrukty a pojmy:
Entity odpovídají objektům reálného světa (osoba, věc, … )a jsou popsány pomocí hodnot svých vlastností. Entita musí být rozlišitelná od ostatních entit a existovat nezávisle na nich.
Relace – vztah, případně typ vztahu, je vazba mezi dvěma nebo více entitami. Vztahová mnoţina R je určena:
R E1 x E2 x … x En ={ (e1, e2, … , en) | e1 E1, e2 E2, … , en En }, kde ei je entita, Ei je entitní typ, n je stupeň relace.
Popisný typ (doménu atributu) definujeme jako jednoduchý datový typ (mnoţina přípustných hodnot, mnoţina operací).
Atribut je funkce, která přiřazuje entitám nebo vztahům hodnotu vlastnosti (popisného typu, domény), je charakteristikou entity. Je zadán svým názvem (identifikátorem) a datovým typem. Kaţdá entita je reprezentována mnoţinou dvojic {atribut, hodnota dat}. Rozlišujeme několik typů atributů, např.
Jednoduché – jedna atomická hodnota a skupinové (strukturované, kompozitní, sloţené) - struktura nemusí být jednoúrovňová, ale můţe vytvářet obecně celou hierarchii. Skupinový atribut vznikne vytvořením sloţitější struktury z jednotlivých poloţek. V obecných úvahách je uţitečné uţívat skupinové atributy, pokud potřebujeme někdy přehledně popisovat celou skupinu, jindy dáme přednost podrobnější reprezentaci pomocí jednotlivých sloţek a zploštěním víceúrovňové struktury.
např. ADRESA proti {ULICE, ČÍSLO POPISNÉ, MĚSTO, PSČ, STÁT}
Vícehodnotové - atributy obsahují opakující se stejné poloţky, tedy jsou představovány mnoţinou hodnot.
Např. AUTOR KNIHY – {J. Ullman, J. Widom}
Odvozené atributy – poţadovaná hodnoty atributů, které nejsou uloţeny v tabulkách, vypočteme z hodnot jiných atributů, uloţených v tabulkách.
Např. Známe POČET OBYVATEL a PLOCHA STÁTU a vypočteme HUSTOTA OBYVATEL
HUSTOTA OBYVATEL = POČET OBYVATEL / PLOCHA STÁTU
S nedefinovanou hodnotou (NULL), případně předdefinovanou hodnotou (default).
Typ entity - mnoţina objektů stejného typu, abstrakce popisující typ objektu. Je definován jménem a mnoţinou atributů. Jednotlivé entity nazýváme také výskyty, nebo instance objektů entitního typu.
Silný entitní typ – Entitní typ existenčně nezávislý na jiném entitním typu.
Slabý entitní typ – Někdy nejsou dvě instance jednoho entitního typu rozlišitelné pomocí svých atributů, jsou rozlišitelné aţ pomocí toho, ţe jsou povinně v identifikačním vztahu k další entitě jiného typu (silné, regulární). V identifikačním klíči takového slabého entitního typu musí mýt i vazební atribut, případně atributy (cizí klíč) identifikačního vlastníka. Graficky v ER diagramu se slabý entitní typ často znázorňuje dvojitým obdélníkem, identifikační vztah dvojitým kosočtvercem.
ISA hierarchie. Někdy se mezi sledovanými objekty vyskytují objekty podobného typu, sémanticky vyjadřující asociace – generalizaci ( jedním směrem ) nebo specializaci (opačným směrem), popsané řadou stejných atributů a lišících se jen v některých atributech. Specializace je proces maximalizující rozdíly mezi podobnými entitními typy identifikací rozdílných rysů. Naopak generalizace je proces minimalizující rozdíly mezi podobnými entitními typy identifikací jejich společných rysů. Jestliţe při většině manipulací s daty obou typů entit se provádějí akce nad společnými údaji, bude vhodné definovat společný typ entity, který bude mít atributy společné a speciální typy se speciálními atributy, které rozlišují odvozené entity. Někdy hovoříme o nadtřídě, respektive podtřídě. Takový vztah definuje ISA hierarchii.
Agregace reprezentuje vztah ‘je částí’, ‘obsahuje’ mezi dvěma entitními typy, z nichţ jeden představuje celek a druhý jeho část. Zvláštní případ agregace je kompozice pro případy silného, nesdíleného vlastnictví části celkem, se stejnou délkou ţivota obou entit.
Průvodce studiem
Integritní omezení ER modelu se týkají identifikačních klíčů, speciálně primárního klíče, referenční integrity, domény atributů, kardinality a členství ve vztahu.
Integritní omezení (IO) ER modelu jsou logická omezení na typy a hodnoty atributů, entit a vazeb taková, aby konceptuální schéma co nejlépe a nerozporně odpovídalo zobrazované realitě.
Jeden atribut nebo mnoţinu atributů, které jednoznačně určují entitu v mnoţině entit, nebo vztah v mnoţině vztahů, nazveme identifikačním klíčem, obecně nadmnoţinou klíče (superkey). Mnoţinu všech minimálních podmnoţin atributů entity, které ji identifikují, nazýváme kandidátní klíče. Jeden z kandidátních klíčů zvolíme za primární klíč. Vybíráme ten, který je z hlediska zpracování dat nejefektivnější, nebo přirozeně identifikující. Často se volí i uměle dodefinovaný identifikační atribut (automaticky generované přirozené číslo), jako klíč pro efektivnější provádění operací. V ER diagramu se značí obvykle podtrţením.
Na hodnoty atributů mohou být kladeny omezující podmínky rozličného charakteru, které respektují meze dané sémantikou dat a které představují doménové integritní omezení.
Další forma integritních omezení na úrovni ER diagramu se týká vztahů.
1. Kardinalita vztahu - Binární vztah typů entit E1 a E2 můţe mít jeden ze tří poměrů:
1:1 - jedné e1 E1 odpovídá ve vztahu nejvýše jedna e2 E2 a naopak, jedné e2 E2 odpovídá nejvýše jedna e1 E1;
N-ární vazby pak mohou mít poměry 1:1:1, 1:M:1, 1:M:N, M:N:K, . . .
2. Členství ve vztahu – vyjadřují moţnost samostatné existence entity (nepovinné, fakultativní členství)
- případ, kdy jsou entity existenčně svázány ve vztahu (povinné, obligatorní členství)
Přitom můţe mít jedna entita povinné členství, druhá nepovinné. Typ povinnosti členství alternativně zaznamenáváme graficky v ER diagramu značkou(např. plným krouţkem na straně příslušného entitního typu, nepovinnost prázdným krouţkem), nebo společně s kardinalitou
(E1:(min,max),E2:(min,max)), případně (min,max):(min,max)
kde min je hodnota 0 (nepovinné) nebo 1 (povinné), max je hodnota 1 nebo M dle kardinality vztahu.
kde min je hodnota 0 (nepovinné) nebo 1 (povinné), max je hodnota 1 nebo M dle kardinality vztahu.
Mezi další typy integritních omezení, které částečně souvisí a pouţívají se v relačním modelu dat, do kterého je ER diagram většinou transformován, můţeme zahrnout omezení na unikátní = neopakující se hodnoty v odpovídajících jednotlivých atributech nebo skupinách atributů. Dále můţe být pouţita referenční integrita, která zabezpečuje vztahy mezi objekty tak, aby případné odkazy nemohly odkazovat na objekt, který se v databázi nevyskytuje.

Obr. 8 Dr. Peter Chen, autor ER modelu (1970)

V současnosti se stále častěji vyuţívá rozšířený ( enhanced) ER model – EER s podporou agregace a kompozice, pouţívající UML.
Vymezení pojmů entita, vztah a atribut je velmi volné, při modelování se podle zkušeností analytika mohou z různých důvodů konstrukty transformovat, většinou se záměrem zvolit podobu ER diagramu ve formě vhodné pro převod do relačního databázového modelu. Jednoznačná pravidla pro klasifikaci neexistují, výsledná podoba schématu závisí na subjektivním chápání zadání analytikem. Následují ukázky některých typových situací
1. Převod vícehodnotového atributu na vztah mezi entitami
2. Převod ternárního vztahu na binární – pracovník pouţívá k řešení úkolu zařízení
Průvodce studiem
Při návrhu ER diagramu musíme vyřešit dilema: Modelovat koncept jako entitu, nebo atribut? Modelovat koncept jako entitu, nebo vztah? Modelovat koncept jako vztah binární, nebo n-ární, použít agregaci, ISA hierarchii?
Vlastní návrh ER diagramu můţeme provádět principiálně několika způsoby ( velice schématicky ) :
1. shora – dolů : popíšeme typy entit, typy vztahů a jejich atributy na určité úrovni podrobnosti, zformulujeme IO, vyzkoušíme funkčnost navrţené struktury, …(zjemníme pojmy, iterujeme )
2. zdola – nahoru : vycházíme z jednotlivých typů objektů na nejniţší úrovni, vytvoříme mnoţinu všech poţadovaných informací – potenciálních atributů jako výchozí univerzální relaci, definujeme a pracujeme s funkčními závislostmi mezi atributy, často i s pomocí počítače vhodnými algoritmy seskupíme atributy do entitních typů a vztahů. Vznikají tak dílčí nezávislé pojmy, integrují se do komplexnějších celků,
3. zevnitř ven : Zaměříme se na nejdůleţitější, jasné pojmy. Potom přes pojmy blízké výchozím se propracujeme ke vzdálenějším ( jakoby všemi směry, ne jen zdola nahoru ), postupným spojováním vytvoříme celek.
4. kombinovaně – vhodná kombinace předchozích způsobů
Příklad ER diagramu :
2.3 Konceptuální model HIT
Původním českým produktem je konceptuální model HIT (Homogenita-Integrovanost-Typy). Je zaloţen na teorii typovaného Lambda-kalkulu, která vychází z predikátové logiky vyšších řádů. Umoţňují pracovat s celou hierarchií typů (objekty, třídy objektů, třídy tříd ap.). Tím jsou jeho vyjadřovací schopnosti silnější a lépe postihnou sloţitost reálných objektů a jejich chování.
Na rozdíl od ER modelu, který pouţívá pojmů entita a vztah, pouţívá model HIT pojmy objekt a funkce, vztahy definuje jako funkce. Definuje vlastní grafickou reprezentaci základních datových typů a datových funkcí.
Shrnutí
ER diagram slouţí pro modelování datové struktury ve formě popisu entitních mnoţin a jejich vztahů a také vlastností jednotlivých entit. Existují různé notace pro kreslení ER diagramu, klasická Chánova pouţívá obdélník pro entitu, krouţek pro atribut a kosočtverec pro vztah. Kardinalita vztahu můţe být 1:1. 1: N a N:M. Podmnoţina atributů entity tvoří identifikační klíč, pokud kombinace hodnot těchto atributů určuje jediný výskyt entity. Primární a unikátní klíč, spolu s kardinalitou vazby, povinným a nepovinným členství ve vztahu, určení domén jednotlivých atributů a referenční integrity patří mezi integritní omezení ER modelu.
Specializace a generalizace je v ER diagramu zachycena pomocí ISA hierarchie. Modelování a transformace v ER diagramu umoţňují variantně modifikovat schéma například přechodem z atributu na entitu, modelováním vazeb se změnou jejich počtu a stupně, agregováním struktury entit a vztahů.
Pojmy k zapamatování
ER model, entita, slabá entita, atribut, vztah, asociace, agregace
Integritní omezení - primární klíč, kardinalita vztahu, členství ve vztahu, referenční integrita
ISA hierarchie, specializace, generalizace
Kontrolní otázky
10. Jaké konstrukty a s jakou charakteristikou má ER model?
11. Jaká integritní omezení má ER model?
12. Co je a jak určíme v konkrétním případě kardinalitu vazby?
13. Co je slabý entita a jak se s ní pracuje v ER diagramu?
14. Co je a k čemu slouží ISA hierarchie?
Úkoly k textu
Vytvořte z vlastního jednoduchého zadání ER diagram s několika vazbami. Určete kardinalitu a účast ve vztahu, modifikujte ER diagram ve dvou funkčních variantách, formulujte a znázorněte integritní omezení.
Navrhněte ER diagram se slabou entitou, ISA hierarchií.
3 Logické modely dat
Studijní cíle: Po prostudování kapitoly by student měl znát historii a charakteristiku jednotlivých logických databázových modelů, jejich integritní omezení. Na příkladech nakreslit jednoduché datové struktury ve zvoleném modelu transformací z ER diagramu. Student by měl popsat relační strukturu dat a její vlastnosti, vysvětlit základní termíny, definovat relaci, kategorie relací a n-tice, formulovat pravidla pro transformaci z ER diagramu do relačního modelu. Charakterizovat objektový model a jazyk ODL.
Klíčová slova: Síťový databázový model, Bachmanův diagram, C-mnoţina, hierarchický databázový model, relační model, integritní omezení, klíč, referenční integrita objektový model, ODL
Potřebný čas: 4.hodiny
Pro uţivatele při konkrétní práci s DBS je nutno zvládnout příkazy JDD a JMD příslušného SŘBD a rozumět datovému modelu, který podporuje. V současnosti se v praxi setkáme v převáţné většině případů s relačním nebo relačně-objektovým modelem, ale začneme přehledem historicky prvních modelů.
3.1 Síťový databázový model
V roce 1971 byla skupinou DBTG (Data Base Task Group) při sdruţením CODASYL (Conference on Data System Languages) definována architektura SŘBD síťového modelu, zaloţená na souborech a vztazích mezi záznamy. Vztahy mezi záznamy se modelují pomocí spojek. Logickému modelu databáze se říká schéma a má například s pomocí grafové struktury formu Bachmanova diagramu. Při definici schématu se typ entity nazývá typ záznamu - Record a můţe obsahovat poloţky – jména atributů čtyř typů – jednoduché, opakující se, složené nebo opakující se složené. Jednotlivým záznamům s nějakou kombinací hodnot odpovídajících poloţek říkáme výskyty záznamu příslušného typu. Mohou existovat dva identické záznamy. Tyto výskyty jsou rozlišeny pouze hodnotou identifikačního databázového klíče, který je systémem automaticky přidělován kaţdému výskytu záznamu.
Síťový model definuje pouze funkcionální binární vztahy typů 1:1 a 1:N mezi dvěma typy záznamů a tento vztah se nazývá set, C-mnoţina, případně CS-typ. Je definována pomocí svého typu vlastníka a typu člena nebo členů, jako pojmenovaná uspořádaná dvojice. Realizace vztahu je potom ve výskytech CS-typu. Výskyt CS-typu obsahuje právě jeden výskyt záznamu vlastníka a právě ty výskyty záznamů člena C-mnoţiny, které jsou s vlastníkem výskytu setu v příslušném vztahu. Výskyt setu můţe obsahovat pouze výskyt záznamu vlastníka (prázdný výskyt setu). Příklady operací
- vytvoř databázové schéma,
- vytvoř nový záznam daného typu, zruš daný záznam, změň daný záznam,
- vloţ člen do výskytu C-mnoţiny daného vlastníka,
- vyřaď člen z daného výskytu C-mnoţiny
- najdi první člen ve výskytu C-mnoţiny daného vlastníka,
- najdi následníka ve výskytu C-mnoţiny daného vlastníka pro daný člen,
- najdi vlastníka ve výskytu C-mnoţiny, známe-li člen
Schéma je tedy tvořeno zadáním typu záznamů a CS-typů. Implementace je realizována pomocí ukazatelů formou kruhových seznamů.
Grafické znázornění modelu (Bachmanův diagram):
Vybraná pravidla:
Tentýţ typ záznamu můţe být současně vlastníkem jedné C-mnoţiny a členem v jiné C-mnoţině.
Záznam libovolného typu můţe být členem, případně vlastníkem libovolného počtu C-mnoţin.
Vybraná omezení (integritní):
Nejsou povoleny rekurzívní typy vztahů.
Vlastník a člen C-mnoţiny nemohou být záznamy téhoţ typu. Unární vztah 1:N se realizuje prostřednictvím pomocného typu záznamu
Nemůţe existovat člen C-mnoţiny bez vlastníka
Příklad deklarace databáze :
Typy záznamů :
Čtenář( jméno, adresa)
Výpůjčka (dat_půjčeno, dat_vráceno)
Kniha-exemplář (autor, název)
Typy C-mnoţin :
Půjčil si(Čtenář, Výpůjčka)
Je půjčen(Výpůjčka, Kniha-exemplář)
Známé implementace – IDMS, ADABAS, DMS 1100
3.2 Hierarchický databázový model
Hierarchický databázový model můţeme pojmout jako speciální případ síťového modelu. Diagram datové struktury tvoří strom (graf bez cyklů) nebo les stromů. Prakticky to znamená, ţe záznam můţe patřit maximálně do jednoho setu. Typy záznamů se podobají síťovému modelu, ale jsou jednodušší, obsahují jen jednoduché atributy. Při popisování hierarchického modelu se mění terminologie. Místo vlastník se uţívá pojmu otec(rodič), místo člen pojmu syn(dítě).
Databázové schéma je tvořeno zadáním typu záznamů a hierarchické struktury definičních stromů. Záznamy stromů jsou uspořádané. Lze definovat pohledy. Databázi lze chápat jako jediný strom se systémovým kořenem. Pro ilustraci při manipulaci s daty postupujeme následovně:
1. Nastavení na kořen stromu DB
2. přechod na poţadovaný strom
3. přechod mezi úrovněmi hierarchie
4. přechod mezi poloţkami na jedné úrovni
5. poţadovaná operace se záznamem na specifikované pozici
Problém se vztahem M:N můţeme řešit podobně, jako u síťového modelu, rozloţením typu vztahu M:N na dva 1:N – více definičních stromů, nebo pomocí duplikovaných záznamů – k záznam typu dítě se vytvoří duplicitní záznamy se vztahy ke všem poţadovaným rodičovským.
Známé implementace – IMS firmy IBM
Průvodce studiem
Hierarchický i síťový model závisí na struktuře dat IS, informace tvoří příslušný graf a implementují je kolekce různých typů záznamů, nejčastěji ve vztahu 1: N.Pro pohyb datovou strukturou se používá odkazů – to vystihuje termín navigace při vyčíslování dotazů. Při změnách v datových strukturách se typicky musí měnit i aplikační programy.
3.3 Relační model
Databázový relační model dat navrhl v roce 1970 pracovník firmy IBM - Dr. E. F. Codd. Základem je matematické zobecnění pojmu soubor pomocí silného formalizmu matematické relace a vyuţívání operací relační algebry.
Hlavní pravidla relačního modelu :
Databázi, popisující úsek reálného světa, tvoří na logické úrovni konečná mnoţina relací - tabulek.
Transparentnost při manipulaci s daty – nezajímáme se o přístupové mechanizmy k datům, obsaţeným v relacích. Pro manipulaci s daty je silná matematická podpora, důsledné oddělení logické úrovně dat od implementace.
Informace v databázi jsou vyjádřeny explicitně na logické úrovni jediným způsobem - hodnotami v tabulkách, data jsou přístupná pomocí JMD, parametrizovaném kombinací logického jména tabulky, logických jmen sloupců a jejich výrazů, nejčastěji s hodnotami všech typů klíčů.
Systematická podpora zpracování nedefinovaných hodnot. Umoţňuje práci s neúplnými daty.
Dynamický on-line katalog zaloţený na relačním modelu. Schéma databáze je vyjádřeno na logické úrovni stejným způsobem, jako uţivatelská databáze, ve formě systémových tabulek. Správce databáze můţe pouţívat stejný relační jazyk pro dotazy na strukturu databáze, jako uţivatel při práci s daty aplikace.
Nezávislost IO na aplikaci - integritní omezení jsou definovatelná jazykovými prostředky SŘBD, jsou uloţena v katalogu, ne v aplikačním programu.
Omezení redundance dat v relační databázi - jsou navrţeny postupy, umoţňující normalizovat relace, tedy navrhovat potřebné relace s minimální strukturou uloţení na disku.
Vazby mezi entitami jsou reprezentovány opět relacemi. Formálně se s nimi pracuje stejně jako s entitními relacemi.

Obr. 10 Dr. Edgar Frank Codd
3.3.1 Relační struktura dat
Schéma relace R je výraz tvaru R(A1 : D1, A2 : D2, … An : Dn) Ai ≠ Aj pro i ≠ j, kde R je jméno schématu, A = {A1, A2,..., An} je konečná mnoţina jmen atributů, f(Ai) = Di je zobrazení přiřazující kaţdému jménu atributu Ai neprázdnou mnoţinu, kterou tradičně nazýváme doménou atributu Di, . V terminologii relačních jazyků odpovídá pojmu relace praktičtější pojem tabulka, která se skládá ze záhlaví a těla. Záhlaví odpovídá schématu relace, tělo je tvořeno mnoţinou n-tic (a1, a2,..., an), coţ je konečná podmnoţina kartézského součinu domén Di příslušejících jednotlivým atributům Ai -
R D1 x D2 x ...x Dn, , tedy hodnoty atributů jsou z příslušných domén a vyhovují všem integritním omezením. Hovoříme o přípustné relační databázi, nebo o konzistentní mnoţině relací.
Př. doména pro jméno : {Alena, Petr, Jiří, Jana, …}
Počet n-tic určuje kardinalitu relace. Číslo n se nazývá stupněm relace (aritou). Stupeň relace je relativně konstantní(umoţněna modifikace pomocí ALTER TABLE), kardinalita se v čase mění (INSERT, DELETE). Relacím se schématem R říkáme, ţe jsou jeho instancí, nebo jinak také jsou typu R .
Na tabulku můţeme také nahlíţet tak, ţe většinou (po transformaci z ER diagramu) kaţdý řádek odpovídá jedné entitě, kaţdý sloupec jednomu atomickému atributu. Na rozdíl od matematických relací jsou databázové relace proměnné v čase. Aktualizace databáze, která umoţňuje zachytit v databázi změny nastávající v reálném světě, tedy spočívá ve změně aktuálních relací přidáváním, rušením prvků relací nebo změnou hodnot některých atributů.
Vlastnosti relací a tabulek
Pořadí n-tic v relaci (řádků v tabulce) je nevýznamné
Pořadí atributů v relaci (sloupců v tabulce) je nevýznamné
V relaci neexistují duplicitní n- tice (je to mnoţina), v tabulce se obecně mohou duplicity vyskytovat, pokud se o jejich odstranění explicitně nepostaráme ( primární klíč, … distinct …)
Jména atributů jsou v relaci, tabulce unikátní,
kaţdý údaj (hodnota atributu ve sloupci) je atomickou poloţkou z jedné domény (vyhovuje 1NF)
V praktických aplikacích je kaţdý řádek tabulky jednoznačně identifikovatelný hodnotami jednoho nebo několika atributů (primárního klíče) – nepřipouští se duplicitní řádky.
Schéma relační databáze je dvojice (R, I), kde R je konečná mnoţina relačních schémat {R1(A1), R2(A2),. . . , Rm(Am)} a I je mnoţina IO.
Relace můţeme kategorizovat na:
Pojmenované
- bázové, reálné jsou fyzicky existující ( CREATE TABLE …)
- pohledy jsou virtuální, odvozené z bázových ( CREATE VIEW …)
- snímky jsou odvozené, statické, ale existující (CREATE MATERIALIZED VIEW / SNAPSHOT …)
Nepojmenované
- dočasné ( CREATE GLOBAL TEMPORARY TABLE …)
- výsledky a mezivýsledky dotazů ( SELECT …)
3.3.2 Integritní omezení v relačním modelu
Integritní omezení se dělí na
Specifická – typicky implementována v prostředí procedurálního jazyka, jako rozšíření SQL, ve formě triggeru, uloţené procedury. Jsou unikátní, určena specifikou aplikace. Dříve byla implementována v aplikaci.
Obecná – jednodušší, odvozená z principů relačního modelu, specifikovaná příkazy DDJ při definici tabulek, ověřovaná při manipulaci s daty.
1. Klíč relace (tabulky) je podmnoţina atributů relace, která identifikuje n-tici, tedy splňuje tyto časově nezávislé vlastnosti :
- unikátnost ( neexistují dvě n-tice se stejnými hodnotami klíčových atributů)
- Minimálnost ( z mnoţiny atributů klíče nelze vynechat ţádný atribut, aniţ by se tím neporušila unikátnost )
- platnost ( hodnoty všech klíčových atributů musí být definované)
Všechny takové podmnoţiny nazveme kandidátními klíči, z nich jeden vybraný je primárním klíčem, zbývajícím kandidátním klíčům někdy říkáme alternativní( pouţití klauzule UNIQUE). Zbývající podmnoţiny atributů relace, které nejsou kandidátními označujeme jako sekundární ( obecně jejich hodnoty určují více n-tic v relaci ) a uplatní se například při třídění a spojení relací.
Cizí klíč (jeho hodnoty jsou hlídány referenční integritou) je podmnoţina atributů relace, které zároveň tvoří primární ( kandidátní ) klíč v jiné relaci.Oba klíče by měly být ze stejné domény. Referenční integrita popisuje asymetrický vztah mezi dvěma (tabulka hlavní a závislá), nebo více tabulkami prostřednictvím cizího a kandidátního klíče, je typickou realizací vazby mezi entitami z ER diagramu. SŘBD připustí v cizím klíči jen hodnoty plně nezadané (nedefinované), nebo ty které jsou aktuálně v kandidátním klíči druhé tabulky. Databáze nesmí obsahovat nesouhlasnou hodnotu cizího klíče. Na to reaguje DMJ v příkazech INSERT omezením vloţení n-tice do závislé tabulky a DELETE omezením odstranění n-tice z hlavní tabulky, nebo kaskádovým odstraněním n-tic z hlavní relace s propagací do závislé (závislých) relací formou odstranění celých n-tic, či jen nahrazením hodnot cizího klíče prázdnou nebo implicitní hodnotou. Cizí klíč se můţe odkazovat i na svou vlastní relaci.
2. Doménové IO, testuje hodnoty vkládané do databáze podle oboru hodnot - domén atributů v tabulce, při dotazování testuje smysluplnost operací porovnání.
- Nejjednodušší IO, definuje přípustnost nedefinované hodnoty atributu( klauzule NULL proti NOT NULL )
- Definice implicitní hodnoty atributu – náhrada nedefinované hodnoty v některých příkazech ( klauzule DEFAULT)
- Zúţení předdefinovaných datových typů, pomocí logických podmínek v klauzuli CHECK.
- V SQL 92 se setkáme s ASSERTION, coţ je predikát, jehoţ podmínky musí databáze splňovat (CREATE ASSERTION …CHECK (…))
Průvodce studiem
Entitní integrita – v bázové relaci nesmí být v žádné složce primárního klíče nedefinovaná hodnota NULL. Referenční integrita – hodnota cizího klíče každé n-tice v relaci musí odpovídat hodnotě nadklíče v odkazované zdrojové relaci nebo může obsahovat ve všech složkách klíče nedefinovanou hodnotu NULL.
Mezi IO relačního modelu patří také funkční závislosti mezi atributy. Funkční závislost mezi mnoţinami atributů X a Y ( značíme obvykle X Y ) znamená, ţe ke kaţdé hodnotě atributů z mnoţiny X existuje nejvýše jedna hodnota atributů z mnoţiny Y. Funkční závislosti se definují jiţ na konceptuální úrovni z kontextu a zadání aplikace a podílí se na upřesnění sémantiky. Podrobněji v dalším textu.
3.3.3 Doporučení pro transformaci ER diagramu do relačního modelu
Cílem je vytvoření (výchozího) schématu databáze v relačním modelu dat ( definice záhlaví tabulek) z výchozího konceptuálního schématu aplikace v ER modelu. Nejdůleţitějším úkolem je zamezit nebo minimalizovat ztráty spojené s přechodem do niţší úrovně abstrakce, tedy zajistit jakousi informační ekvivalenci. Proto ke schématu relací připojujeme i integritní omezení. Vyberme některá doporučení, společná většině metodologií:
1. Vytvoření relací z regulárních (silných) entitních typů, atributy relací odpovídají jednoduchým atributům entitních typů, u sloţených typů atributů provedeme dekompozici na jednoduché atributy. Pokud je struktura sloţitější, transformujeme příslušné subschéma ER diagramu do pro transformaci pouţitelné podoby. Převezmeme, nebo určíme primární klíč.
2. K transformaci slabého entitního typu potřebujeme znát relaci identifikačního vlastníka. Provedeme transformaci jako v předešlém případě. Dostaneme pouze parciální klíč. Doplníme relaci o atributy identifikačního klíče relace identifikačního vlastníka ( tvoří cizí klíč ) a přidáním k parciálnímu klíči definujeme primární klíč.
Relace : Dokumentace(IDd, Projekt), Verze_dokumentace(IDd, Číslo_verze, Datum)
3. Typu vztahu odpovídá schéma relace, zahrnující referenční integritní omezení.Obecně pro všechny transformace existuje více variant a záleţí na dalších vazbách a IO ( povinné a nepovinné členství ve vztahu, …), předpokládaných datech ( rozsah, počet (relativní) propojených entit) a převaţujících dotazech. Problematiku naznačíme na příkladech.
Reprezentace vztahů 1:1
a) Při vztahu (1,1)-(1,1) , kaţdý pracovník má právě jeden počítač se nabízí moţnost spojit entitní typy do jedné relace, zvolit primární klíč z jednoho entitního typu, sloupec původního primárního klíče druhé relace (idP) doplníme o IO UNIQUE. Sémanticky z pracovního počítače uděláme charakteristiku zaměstnance. Toto řešení nepředpokládá další vazby na entitní typ počítač.
aa) Zaměstnanec(IDz, jméno, idP, TypP)
Jinak transformaci provedeme převedením na dvě relace. Do záhlaví jedné (Zaměstnanec) přidáme jako vazební poloţku primární klíč druhé ( idP), připojíme IO – referenční integritu, UNIQUE, případně NOT NULL. Nový sloupec je cizím klíčem, NOT NULL kontroluje povinné členství ve vztahu. Tedy pokud by počítač neměl kaţdý zaměstnanec – vztah (0,1)(1,1), potom NOT NULL nepouţijeme.
ab) Zaměstnanec(IDz, jméno, idP), Počítač(idP, TypP)
Pro některé případy ( velká záhlaví ) a převaţující uţívání speciálních dotazů( např. na atributy vazby) můţe být výhodné provést transformaci do tří relací. Dvě entitní relace jsou definovány entitními typy a záhlaví třetí vztahové relace (pro typ vztahu) vytvoříme z primárních klíčů ve vazbě zúčastněných entitních typů. Ty jsou opět cizími klíči, UNIQUE a NOT NULL. V kombinaci potom tvoří primární klíč. Toto řešení je sémanticky srozumitelné třeba v situaci, kdy vztahový typ má další atributy.
ac) Zaměstnanec(IDz, jméno), Vyuţívá(IDz, idP), Počítač(idP, TypP)
b)Podobně můţeme analyzovat reprezentace vztahů 1:N, N:1.
Vztah (1,N)(1,1) – všechny místnosti jsou obsazeny, všichni zaměstnanci jsou umístěni řešíme nejčastěji vytvořením dvou relací. Do záhlaví relace(Zaměstnanec), která je ve vazbě s kardinalitou 1 přidáme primární klíč z entitního typu(Místnost), který ve vazbě reprezentuje kardinalitu N. Ten je cizím klíčem s dalším integritním omezením NOT NULL (povinné členství ve vztahu), ale jiţ bez UNIQUE.
ba) Zaměstnanec(IDz, jméno, idM), Místnost(idM, plocha)
Z podobných důvodů, které byly analyzovány v předchozím případě ac), můţeme provést transformaci do tří relací.
bb) Zaměstnanec(IDz, jméno), Umístěn(IDz, idM), Místnost(idM, plocha)
c)Podobně řešíme reprezentace vztahů N:M. Pokud kaţdý zaměstnanec pracuje nejméně na jednom úkolu a kaţdý úkol je řešen nejméně jedním zaměstnancem, vztah lze popsat jako (1,N) (1,M).
Nebo relaci rozloţíme na binární vazby.
e) Se stejnými principy se setkáme u transformace ISA hierarchie, jde vlastně o speciální vztahy.
Příklady řešení
ea) Všechny entitní typy z ISA hierarchie transformujeme do jedné relace. V záhlaví jsou všechny atributy entitních typů, primárním klíčem relace je klíčový atribut (IDo) zdroje hierarchie(Osoba). Výhoda – ušetříme čas na spojení, nevýhoda – řídká tabulka s mnoha nedefinovanými hodnotami. Řešení:
Osoba(Ido, Jméno, Profese, pomůcky, Datum_ukončení_práce, částka_důchodu)
Eb) Všechny entitní typy transformujeme do samostatných relací. Součástí primárního klíče relací jsou sloupce, do záhlaví přidané propagací primárních klíčů z nadřazených úrovní hierarchie, zároveň jsou to cizí klíče a vazební poloţky pro získání sdílených sloupců (společných vlastností) pomocí spojení. Řešení:
Osoba(Ido, Jméno),
Zaměstnanec(Ido, Profese, pomůcky),
Důchodce(Ido, Datum_ukončení_práce, částka_důchodu)
Při konverzi se můţeme setkat (a musíme vyřešit) s těmito problémy:
1. Stejná logická jména sloupců se stejnou (ve vazbách) nebo různou sémantikou. Proto pouţíváme výstiţné, úplné unikátní pojmenování, případně tečkové notace.
2. Pokud mnoho vazeb v ER modelu tvoří sekvence nebo cykly, můţe dojít k neţádoucím efektům, které v konečném důsledku představují neúplnost, zkreslení, omezení nebo chybu.
Tabulka ekvivalentních poloţek ER modelu a relačního modelu ER model Entitní typ .Entita 1:1 nebo 1:N typ vztahu M:N typ vztahu n-ární typ vztahu jednoduchý atribut kompozitní atribut vícehodnotový atribut mnoţina hodnot klíčový atribut | Relační model relace cizí klíč (nebo vztahová relace) vztah. relace a dva cizí klíče vztah. relace a n cizích klíčů atribut mnoţina atributů relace a cizí klíč Doména Primární, kandidátní klíč |
3.4 Objektově-relační model
Tlak nových typů aplikací s bohatě strukturovanými daty a přirozený evoluční vývoj vedl k rozšíření relačních systémů o softwarovou vrstvu dodávající relačnímu SŘBD objektový charakter. Rozšiřuje relační model o bohatší typový systém. Takový databázový model dat nazýváme objektově-relační. Mimo jiné jsou podporovány zanořené relace (není vyţadována 1. NF) – jinak formulováno atributy entit – objektů mohou být strukturované, sloţité datové typy. Dále je moţné definovat uţivatelské ADT, kolekce typů jako např. mnoţina, multimnoţina, seznam, pole, … , reference na objekty, konstruktory sloţitých objektů. Podpora objektových rysů umoţňuje definovat metody objektů, aplikovat dědičnost. V objektově-relačních systémech přebírají n-tice relací roli objektů a proto mají povinně své identifikátory ID, většinou nepřístupné uţivateli. Doporučení a vlastnosti OR SŘDB jsou normalizovány v SQL 99 nebo v SQL 3 a představují proces sbliţování s čistě objektovými systémy. Proto jsou některé společné rysy podrobněji rozebrány v následující kapitole.
3.5 Objektový model
Datové modely, vyhovující aplikacím s plochou jednoduchou datovou strukturou (krátké záznamy pevné délky s atomickými hodnotami atributů) jsou prakticky nepouţitelné v aplikacích s bohatě strukturovanými daty( hierarchie sloţitých objektů, často se správou vývoje verzí), jako jsou systémy CAD, multimédia, grafické aplikace, hypertextové a dokumentografické systémy. Takové aplikace poţadují novou koncepci uloţení komplexních dat a efektivnější a abstraktnější operace s nimi – nové metody indexování a dotazování. Vývoj softwaru jasně směřuje k maximálnímu vyuţití výhod objektově orientovaného paradigmatu a technologie ve všech fázích vývoje programu – objektově orientovaná analýza a návrh, modelování procesů, implementaci (s rysy jako zapouzdření – část funkcí, dříve v aplikačních vrstvách, se přenáší do objektu a stává se součástí databáze , pouţití abstraktních datových typů, atd. s rozšířením o perzistenci objektů) a testování. Objektová technologie v databázových systémech přináší na konceptuální úrovni bezprostřední vztah mezi objektem reálného světa a jeho reprezentací ve formě sloţitého objektu.
3.5.1 Objektový koncept
Objekty v sobě kombinují a zapouzdřují data a operace nějaké entity z reálného světa. Data odpovídají atributům a reprezentují stav objektu, operace(metody) definují chování objektu, z hlediska programování představují rozhraní pro zprávy. Metody jsou programy, napsané většinou v univerzálních jazycích (C++, Java). Vlastní data objektu jsou přístupná přímo, na data ostatních objektů jsou odkazy ve formě zaslání zpráv. Velice důleţitá je identita objektu (OID), nezávislá na stavu objektu. To vede například k obecnějšímu chápání rovnosti a ekvivalence objektů. Stav dvou objektů můţe být stejný, ale nejsou si rovny, protoţe je rozlišuje OID.
Př. Entita Petr, data: (jméno= Petr, narozen= 1.3.1984)
Objektový Typ popisuje společné struktury (atributy a metody) mnoţiny objektů a vztahuje se více ke konceptuální fázi. Třída v sobě zahrnuje navíc i moţnost vytvářet nové objekty, rušit instance sdruţovat objekty do kontejnerů (extent, extenze třídy) a pracovat tam s nimi, vztahuje se více k implementaci. Objektově orientované jazyky nabízí tedy kromě atomických typů moţnost vytvářet vlastní komponentní typy (structures), sloţené z několika obecných typů, dále různé kolekce typů (set, bag, list, array, dictionary) a referenčních typů – hodnota tohoto typu určuje umístění odkazovaného typu. Schopnosti odvozovat z existujících tříd (superclass) nové třídy(subclass), které ke svým speciálním atributům a metodám automaticky získají atributy a metody svého předka se nazývá dědění. Obecně můţe vzniknout hierarchie tříd i s více nadtřídami (jednoduché proti vícenásobnému dědění) pro jednu úroveň podtřídy.
Zapouzdření – princip viditelnosti - zpřístupnění objektu jen přes jeho rozhraní, ne jiným způsobem. Zlepšuje se tím zabezpečení dat (data jsou modifikovatelná jen veřejnými operacemi). Mezi výhody patří podpora modularity – rozsáhlý problém se rozdělí na menší izolované části s jasnou zodpovědností bez nadbytečných závislostí na ostatních částech aplikace a zvětšuje se znovupouţití kódu v nových aplikacích.
Metody mohou být redefinovány pro různé typy, tj. identická zprava v různém kontextu vyvolá různé reakce na různých objektech (late binding). Schopnost operací fungovat na více neţ jednom typu objektů se nazývá polymorfizmus. Příklad
Výsledkem vývoje a potřeb různých aplikací je řada objektových modelů, lišících se často v důleţitých koncepčních aspektech. Snaha o dosaţení kompatibility čistě objektových systémů vedla ke schválení prvního standardu ODMG v roce 1993. ODMG definuje dva typy produktů :
ODBMS (Object Database Management Systems ) ukládají na disk přímo objekty
ODMs ( Objekt to Database Mapings) transformují objekty a ukládají je ve formě relací nebo XML dokumentů.
Průvodce studiem
Hlavní rysy objektově orientovaného přístupu:
Abstrakce – složitá komplexní realita může být reprezentována zjednodušenými konstrukty modelu.
Zapouzdření – znamená uzavření operací a dat dohromady v objektovém typu s přístupem přes veřejné rozhraní.
Dědičnost – představuje hierarchii objektových typů, kdy následník převezme část nebo všechna data a metody předka
Znovupoužitelnost – schopnost znovu využít objektový typ během návrhu nebo implementace systému.
Komunikace – objekty spolu komunikují prostřednictvím zpráv, které jsou určeny metodám příjemce.
Polymorfizmus – umožňuje psát kód čitelněji, když objekty dědí a modifikují stejnojmenné metody, metoda je aplikována na několik objektových typů.
3.5.2 Úvod do ODL
ODL (Object Definition Language) je standardizovaný jazyk pro definici struktury objektů v objektových databázových systémech. Vychází a rozšiřuje IDL (Interface Description Language) součást objektového standardu CORBA.. Podrobná syntaxe jazyka jde za rámec tohoto textu, ale pro ilustraci je uvedeno několik typických příkladů. Základní prvky jsou objekty (Olomouc, Petr Novák, …) a literály („Zelená 30“, „zedník“, …). Literály jsou jednoduché hodnoty, nemají ID, stav ani metody. Podobné objekty jsou sdruţeny do tříd, jsou generovány pomocí konstruktorů. Kdyţ navrhujeme třídy pomocí ODL, popisujeme tři druhy sloţek:
Stav - je určen
atributy – mohou být atomického, výčtového (seznam literálů) i strukturovaného typu
Např. 1. atomické atributy Attribute string povolání;
2. strukturované atributy Attribute struct Adresa { string obec; string ulice; int číslo } adr1;
3. vícehodnotové atributy Attribute set<int> pokusy;
4. odvozené atributy int věk(); -- metoda
dalšími objekty
Hodnoty se mohou měnit v čase. Několik objektů můţe mít v jednom okamţiku stejné hodnoty atributů.
Vztahy mezi objekty – s rozlišením kardinality a dalších vlastností vztahu, se zavedením inverzního vztahu pro řízení referenční integrity. Příklad vazby 1:1, 1:N a N:M
Metody – deklarace signatury se specifikací parametrů vstupních (in), typicky předávaných hodnotou, výstupních (out) a kombinovaných (inout), předávaných referencí a modifikovatelných. Nepovinně můţe následovat seznam vyjímek, které metoda umí ošetřit.
Class učitel
(extent učitels)
{
…
Int praxe();
void plat(out m_plat, in měsíc)
raises(chyba);
}
Objekty a literály jsou kategorizovány podle svých typů nebo tříd, které mohou tvořit hierarchie. Typy v ODL můţeme rozdělit na základní:
1. Atomické – např. bolean, integer, fload, string, …
2. Třídy - např. učitel, kurz, …
Kombinací základních typů můţeme vytvářet
Structure N {T1 F1, T2 F2, …, Tn Fn}, kde Ti jsou typy a Fi jsou jména poloţek
nebo kolekce s různými vlastnostmi:
1. Set <T> je konečná neuspořádaná mnoţina prvků typu T
2. Bag <T> je konečná neuspořádaná multimnoţina prvků typu T (vícenásobný výskyt prvků)
3. List <T> je konečná uspořádaná mnoţina prvků typu T
4. Array <T,I > je pole prvků typu T , jejichţ počet je I
5. Dictionary <T,S > je konečná mnoţina dvojic prvků klíčového typu T a typu S s vlastnostmi rychlého nalezení hodnoty S podle klíče T
Kolekce existují ve dvou verzích. V první verzi jsou jen hodnoty bez OID, v druhé jsou objekty i se svými metodami. Mnoţina aktuálně uloţených objektů z jedné třídy tvoří extent třídy.
3.6 Další databázové modely
Do praktického ţivota databázových aplikací se stále častěji prosazují aplikace, pro které jsou dříve uvedené klasické modely z různých důvodů méně vhodné. Prosazují se nové přístupy popisu, formy uloţení a přenosu dat v souvislosti například s internetem, kde se často pouţívají semistrukturovaná data. Podrobnější popis těchto modelů jde za rámec tohoto textu, ale alespoň krátká charakteristika:
V semistrukturovaných datových modelech jsou data uloţena ve formě grafu. Uzly grafu popisují strukturované objekty a hodnoty atributů a hrany zachycují vazby mezi objekty nebo objekty a atributy. Takové modely, například zaloţené na XML dokumentech, se pouţívají pro integraci databází napříč různými technologiemi a platformami, pro transformaci struktur dat a nové metody prezentace, hlavně v kontextu nových technologií na Internetu. Model obsahuje informace jak o své hierarchické struktuře, tak vlastní data. Strukturu dat lze explicitně formálně
popsat (DDT, XMLSchema) a tento popis pouţít pro kontrolu jednotlivých datových dokumentů. Do praktického pouţití se prosazuje dotazovací jazyk Xquery.
Shrnutí
Historicky první databázové modely jsou síťový a hierarchický, zaloţené na souborech a vztazích mezi záznamy, které se implementují kruhovými seznamy, pomocí odkazů. Graf datové struktury se skládá z entitních typů a hran, které zobrazují vazby 1:1 nebo 1:N mezi entitními typy a jsou definovány pomocí C-mnoţin – vlastník : člen nebo podobně otec : syn.
Relační model : Relace je při praktickém pohledu tabulka, kde sloupce představují atributy s přiřazením mnoţiny přípustných hodnot ve formě datového typu nebo domény. Řádky tabulky tvoří n-tice a představují informace o jednom výskytu entity. Schéma relace tvoří její logické jméno společně s logickými jmény atributů a doménami. Schéma databáze je kolekce všech relačních schémat aplikace, instanci databáze tvoří aktuální uloţená data. Konverze z ER diagramu do relačního modelu v prvé fázi probíhá tak, ţe entitě odpovídá tabulka, atributy entity převedeme na atomické poloţky a ty tvoří sloupce tabulky. U slabých entitních typů přidáme identifikační atributy z regulární entity, se kterou tvoří identifikační vazbu. Vazby mezi entitami se realizují pomocí atributů v jedné tabulce, korespondujících s primárními klíči v druhé tabulce nebo tabulkách, které figurují ve vztahu. Podobně se řeší transformace ISA hierarchie.
Objektový model: Vychází z ověřených zásad objektového konceptu, vyuţívající zapouzdření, polymorfizmus a třídy. Pro formální popis schématu databáze se pouţívá jazyk ODL, pomocí kterého definujeme třídy, jejich atributy, metody a vazby. Vztahy jsou pouze binární, mezi dvěma třídami, vyjádřené pojmenováním přímé i inverzní vazby v obou třídách. Kardinalita můţe být libovolná, coţ umoţňuje pouţití různých typů kolekcí objektů. Kaţdý objekt má své OID pro jednoznačnou identifikaci, které generuje systém a není uţivatelsky modifikovatelné. Objekt můţe obsahovat i klíčovou poloţku.
Pojmy k zapamatování
Bachmanův diagram, Entitní typ, C-mnoţina
Klíč identifikační, primární, kandidátní, sekundární, cizí
Referenční integrita, doménové integritní omezení
Objektový koncept, ODL
Kontrolní otázky
15. Kam se transformují atributy z ER diagramu při transformaci do hierarchického databázového modelu?
16. Jak se implementuje vazba N:M v síťové modelu?
17. Jaká jsou integritní omezení v logických modelech dat?
18. Jaké vlastnosti musí splňovat kandidátní klíč?
19. Jaké jsou vlastnosti relací?
20. Jaké jsou kategorie relací v databázových systémech?
21. Jak se realizuje vazba mezi entitami v relačním modelu dat, jaká jsou transformační pravidla?
22. Jak se definují základní struktury objektů pomocí ODL?
23. Jaké vlastnosti mají další databázové modely?
Úkoly k textu
Navrhněte ER diagram jednoduché databázové aplikace, obsahující vazby 1:N a N : M a vytvořte schéma databáze, definujte kandidátní, primární a cizí klíče, vyznačte referenční integritu. Vytvořte dané schéma databáze pro relační, hierarchický model dat .
Relační databázové a dotazovací jazyky
Studijní cíle: Po prostudování kapitoly by student měl charakterizovat a popsat základní dotazovací jazyky a jejich vztahy. Na příkladech vysvětlit operace relační algebry, kategorizovat operaci spojení, porovnat relační kalkuly formou zápisu dotazu pomocí jednoduchých výrazů. Student by měl zvládnou základy syntaxe jazyka SQL na základních příkazech pro definici dat a manipulaci s daty. Seznámit se s přístupem k dotazování pomocí QBE, DATALOG, OQL.
Klíčová slova: Operace relační algebry, n-ticový a doménový relační kalkul, bezpečný výraz, SQL, DDJ, DMJ, agregované funkce, QBE, DATALOG, OQL
Potřebný čas: 5 hodin
Obecné poţadavky na dotazovací jazyk můţeme formulovat jako
blízkost – výsledek dotazu musí být reprezentovatelný v konceptech datového modelu,
kompletnost – jazyk musí zajišťovat operace datového modelu – např. u OOJ konstruktory, selektory sloţek, dereference, operace s kolekcemi, …
ortogonalitu – moţnost různě kombinovat a vnořovat operace.
Hlavní sílou relačního modelu je matematicky formalizovaná podpora jednoduchého dotazování. Jazyky SŘBD můţeme rozdělit podle různých kritérií, například na procedurální proti neprocedurálním, nebo podle úrovně na „čisté“(matematické, interní), které tvoří základ pro vyšší uţivatelské dotazovací jazyky. Dva reprezentanti interních jazyků relačního modelu :
1. jazyky zaloţené na relační algebře, kde jsou výběrové poţadavky vyjádřeny jako posloupnost operací prováděných nad relacemi ( tím je definován algoritmus vyhodnocení dotazu – procedurální jazyk), vhodné pro reprezentaci prováděcích rozvrhů při optimalizaci.
2. jazyky zaloţené na predikátovém kalkulu, které poţadavky dotazu zadávají jako predikát P charakterizující poţadovanou relaci - {a, P(a)}. Jedná se o neprocedurální jazyk. Takové jazyky dále dělíme na
- n-ticové relační kalkuly
- doménové relační kalkuly.
Jazyky vyšší úrovně, např.
SQL- postavený na n-ticovém relačním kalkulu a vybraných algebraických konstruktech
QBE : vyuţívá doménové relační kalkuly
QUEL : vyuţívá n-ticové relační kalkuly
4.1 Relační algebra
Relační algebra je důleţitou podporou relačního modelu, představuje vyjadřovací sílu a sémantiku dotazu. Formálně je RA definována jako dvojice (R,O), kde nosičem R je mnoţina relací a O je mnoţina operací. Síla prostředku je dána tím, ţe nepracuje s jednotlivými n-ticemi, ale s celými relacemi. Operátory relační algebry se aplikují na relace, výsledkem jsou opět relace. V průběhu vývoje se ustálila skupina základních a odvozených(redundantních) operací – některé se jiţ obvykle nezmiňují (podíl), jiné odvozené se vyuţívají pro jednoduší
formulaci a efektivnější implementaci (spojení) Protoţe relace jsou mnoţiny n-tic, můţeme operace relační algebry rozdělit na mnoţinové nad relacemi s ekvivalentním záhlavím( sjednocení, průnik, rozdíl), mnoţinovou bez omezení (kartézský součin) a speciální (projekce, selekce, spojení) . Ekvivalencí záhlaví rozumíme stejný počet atributů relací a existence vzájemně jednoznačného přiřazení atributů z jedné a druhé relace, omezené na dvojice s odpovídajícími doménami. Operace jsou popsány formálně i s grafickou ilustrací.
Základní mnoţinové operace relační algebry pro relace R a S :
sjednocení relací ekvivalentního typu R S = {x | x R x S},
ekvivalence je definována nad R, S i V :
R1S1V1; R2S2V2
- přirozené spojení relací R(A) a S(B)
R[*]S = ((RxS)[P])[A1,...,Ak,C1,..,Cm+n-k]
kde Ai jsou všechny atributy se shodnými jmény(nebo sémantikou) jako atributy z B a C jsou ostatní atributy z A i B; ze součinu RxS se vyberou ty prvky, které mají stejné hodnoty(spojení na rovnost) na maximální mnoţině společných atributů.
Nedefinované hodnoty představují neznámá, nebo neexistující data. Pokud operace spojení vyuţívá i prázdné hodnoty (NULL) jedná se o vnější spojení . Motivací je snaha ve výsledku operace získat i n-tice, které s ničím spojit nelze. Podle lokalizace těchto n-tic definujeme levé
vnější spojení – ve výsledku jsou všechny n-tice levé vstupní relace ( v části se záhlavím, odpovídající levé relaci), analogicky pravé vnější spojení poskytne všechny n-tice pravé vstupní relace a symetrické(úplné) vnější spojení vznikne sjednocením levého a pravého vnějšího spojení. Ve výsledku operace je podmnoţina n-tic, odpovídající vnitřnímu spojení a ve zbylých n-ticích jsou na nedefinovaných místech hodnoty NULL. Pro levé spojení platí symbolicky
R*LS = (R* S ) (R x (NULL, … , NULL))
Do relační algebry se zahrnuje i operace přejmenování (atributu, relace), vyuţitelná například - spojení jedné relace sama se sebou, při stejných jménech atributů v různých relacích v jednom výrazu, atd. .
Další, praxí vynucené, rozšíření relační algebry se týká zvýšení síly dotazování o aritmetické operace ( agregační funkce), rozšíření o procedurální prvky, aby bylo moţné pracovat s rekurzí.
4.2 N-ticový relační kalkul
Jako jazyk pro výběr informací z relační databáze lze vyuţít jazyk logiky, predikátového kalkulu 1. řádu. V Coddově definici RMD byl zaveden n-ticový relační kalkul, později se objevil přirozenější doménový relační kalkul. Pod pojmem relační kalkul tedy zahrnujeme oba jazyky.
Abecedu n-ticového relačního kalkulu tvoří :
atomické konstanty (hodnoty atributů), např. ’Novák’
n-ticové proměnné (proměnné, jejichţ oborem hodnot jsou n-tice), označujeme je identifikátory. Za n-ticové proměnné lze dosazovat n-tice relací.
komponenty proměnných (indexové konstanty), odkazy na atributy relací. Označíme je jménem atributu a odkazem na relaci,
predikátové konstanty (jména relací),
predikátové operátory binární {< , <= , > , >= , = , <> }, obecně *
logické operátory a kvantifikátory {OR, AND, NOT, EXIST, FORALL}
oddělovače ( )
Formulí n-ticového relačního kalkulu je
atomická formule R(r), kde R jméno relace, r je n-ticová proměnná; formule znamená, ţe r je prvkem relace R;
atomické formule r.a * s.b, r.a * 'k' , 'k' * s.b, kde r, s jsou n-ticové proměnné, a, b jsou komponenty proměnných (atributy), 'k' je atomická konstanta, * je binární operátor, r.a je atribut a n-tice r, s.b atribut b n-tice s;
jsou-li F1 a F2 formule, pak také F1 OR F2, F1 AND F2, NOT F1 jsou formule;
je-li F formule, pak také EXIST r(F(r)), FORALL r(F(r)) jsou formule;
nic jiného není formule.
Podobně jako v predikátovém počtu jsou proměnné vázané kvantifikátory EXIST a FORALL nazývány vázanými proměnnými, ostatní n-ticové proměnné jsou volné. Formule relačního kalkulu reprezentuje vyhledávací podmínku.
Výraz n-ticového relačního kalkulu je výraz tvaru
{ x | F(x)}
kde x je jediná volná proměnná ve formuli F.
Výraz n-ticového relačního kalkulu určuje relaci tvořenou všemi moţnými hodnotami proměnné x, které splňují formuli F(x). x definuje seznam komponent proměnných, které definují schéma výstupní relace. Je to buď jiţ definovaná entita, seznam entit nebo seznam komponent volných proměnných.
Základní operace relační algebry se dají vyjádřit pomocí výrazů n-ticového relačního kalkulu, tedy n-ticový relační kalkul je relačně úplný.
Platí : R S => x | R(x) OR S(x)
R S => x | R(x) AND S(x)
R - S => x | R(x) AND NOT S(x)
R x S => x, y | R(x) AND S(y)
R[a1,a2,...,ak] => x.a1, x.a2,..., x.ak | R(x)
R(P) => x | R(x) AND P
R[A*B]S => x, y | R(x) AND S(y) AND x.A * y.B
Relační kalkul, jak byl zatím definován, umoţňuje zapsat i nekonečné relace, např.
t | NOT R(t)
Výrazy relačního kalkulu se proto omezují jen na tzv. bezpečné výrazy, které definování relací nekonečných nedovolují. dom(P) označme doménu formule P, tedy mnoţinu všech hodnot explicitně se vyskytujících v P nebo v relacích, které jsou součástí P. Bezpečný výraz t | P(t) musí splňovat podmínku, ţe všechny hodnoty, které se vyskytují v n-ticích výrazu P jsou z dom(P) .
Příklady jednoduchých dotazů:
Seznam pracovníků, jejichţ plat je menší neţ 15 000 Kč.
{P | Pracovníci (P) P.plat < 15 000 }
Seznam jmen a příjmení pracovníků, kteří sedí v místnosti s plochou větší, neţ 20 m2 .
{P.jméno, P.příjmení | Pracovníci (P) ( M)(Místnost(M) (P.místnost = M.číslo) (M.plocha > 20) }
4.3 Doménový relační kalkul
V doménovém relačním kalkulu jsou oborem hodnot jeho proměnných prvky domén (na rozdíl od n-tic prvků domén v n-ticovém kalkulu). Podle toho je modifikována také abeceda kalkulu:
atomické konstanty;
místo n-ticových proměnných jsou zavedeny doménové proměnné; ty nejsou strukturovány, odpadá tedy potřeba komponent proměnných,
predikátové konstanty, predikáty příslušnosti k relaci jsou obecně n-ární dle stupně relace;
predikátové operátory binární {< , <=, >, >= , = , <>} , obecně *
logické operátory a kvantifikátory {OR, AND, NOT, EXIST, FORALL}
oddělovače ( )
Atomické formule doménového kalkulu jsou :
R(x1,x2,...,xn), kde R je jméno relace stupně n, xi jsou buď doménové proměnné nebo atomické konstanty; tato atomická formule říká, ţe n-tice hodnot x1, ..., xn je prvkem relace R. Aby v této formuli nebyl seznam proměnných závislý na pořadí atributů, zapisuje se obvykle pro schéma relace R(A,B,C,...)
Formule příslušnosti n-tice k relaci R(A:x1,B:x2,C:x3,...);
x * y, kde x, y jsou doménové proměnné nebo atomické konstanty
* je binární predikátový operátor.
Formule doménového kalkulu se vytváří stejně, jako u n-ticového kalkulu.
Výraz doménového relačního kalkulu je výraz tvaru
x1 x2 ...xn | F(x1,x2,...,xn)
kde x1, ... , xn jsou jediné navzájem různé volné doménové proměnné ve formuli doménového relačního kalkulu F.
Výraz relačního doménového kalkulu určuje relaci tvořenou všemi moţnými n-ticemi hodnot proměnných x1, x2, ..., xn, které splňují formuli F.
Obdobně jako u n-ticového kalkulu se definují i zde bezpečné výrazy doménového relačního kalkulu.
Věta o ekvivalenci
Ke kaţdému výrazu relační algebry existuje ekvivalentní bezpečný výraz relačního kalkulu a opačně, oběma prostředky je moţno vyjádřit stejné třídy dotazů.
Příklady jednoduchých dotazů:
Seznam pracovníků, jejichţ plat je menší neţ 15 000 Kč.
{pjméno, ppříjmení, pplat, pmístnost | (Pracovníci (pjméno, ppříjmení, pplat, pmístnost)) (pplat < 15 000) }
Seznam jmen a příjmení pracovníků, kteří sedí v místnosti s plochou větší, neţ 20 m2 .
{pjméno, ppříjmení | (pplat, pmístnost ) (Pracovníci (pjméno, ppříjmení, pplat, pmístnost)) (mčíslo, mplocha ) (Místnost(mčíslo,mplocha)) (pmístnost = mčíslo) (mplocha > 20) }
4.4 Datalog
Relační algebra umoţňuje vyjádřit mnoho uţitečných operací, ale existují výpočty, zaloţené na zpracování rekurzívních sekvencí podobných výrazů, které nemohou být vyjádřeny. Reakcí je pouţití logicky orientovaného datového modelu v deduktivních databázích, s typickým reprezentantem v systému Datalog, který vychází . Datalog je zaloţen na logickém paradigmatu programování. Skládá se z části extenzionální, která obsahuje základní data ve tvaru tvrzení, tj. logických formulí a intenzionální, která osahuje odvozovací pravidla, pomocí nichţ se definují virtuální relace. Pravidla mají na levé straně hlavu a pravou tvoří tělo. Virtuální relace se tvoří pomocí pravidel se stejnou hlavou, pomocí odkazů na další pravidla i rekurzívně na sebe. Zápis tvrzení a pravidel má formu:
Lx :- Ly, …, Lz,
kde L jsou atomické formule – literály,ve tvaru P(t1, …, tk). P je predikátový symbol, t je proměnná nebo konstanta. Základní literály obsahují jen konstanty a definují tvrzení, tedy data databáze. Pro pravidla, podobně jako v relačním kalkulu, se zavádí omezující podmínky, aby virtuální relace byly konečné a obsahovaly pouze tvrzení.
Příklad rekurze Rozvíjí (x,y) :- PřímoVychází(x,y)
Rozvíjí (x,y) :- PřímoVychází(x,z) AND Rozvíjí (z,y)
Pro formulaci dotazu v DATALOGU musíme znát sémantiku programu. Výsledkem programu je materializace virtuálních relací pomocí odvozovacího stromu. Základní tvrzení jsou v listech,
vnitřní uzly jsou mezivýsledky aplikace pravidel. Princip dotazování ukáţeme na jednoduchém příkladu:
Učitel(U1, Petr, Novák, 21000, informatika)
Učitel(U2, Alena, Malá, 19000, čeština)
…
Virtuální relace :
DobbřePlacenýUčitel(jméno, příjmení) := Učitel(jméno, příjmení, plat, předmět), plat > 20000
reprezentuje dotaz :
?? := Učitel(jméno, příjmení, plat, předmět), plat > 20000, kterému vyhovují data <Petr, Novák>
Porovnání síly DATALOGu a relační algebry ukazuje následující obrázek.
4.5 Jazyk SQL
Jazyk SQL byl původně navrţen v roce 1975 u firmy IBM jako dotazovací jazyk (původní název Sequel v systémech R). V roce 1986 definován standard ANSI (American National Standard Institute), standard ISO – SQL/86, v roce 1989 přidán integritní dodatek –SQL/89. Přelomovým rokem byl rok 1992, standard SQL/92 se třemi úrovněmi souladu – Entry, intermediate, full. Další standardy (SQL3, SQL1999) evolučně směřují k relačně-objektovým databázím a různým rozšířením. Prakticky existují firemní dialekty SQL/92 s rozšířením.
Jazyk obsahuje příkazy pro definici databáze a vytvoření jejích objektů a integritních omezení, interaktivní jazyk pro manipulaci s daty – včetně komplexních dotazů, řízení přístupových práv, řízení transakcí, které z SQL dělají mnohem silnější prostředek, neţ jen dotazovací jazyk.
4.5.1 Příkazy pro definici dat
Následující přehled vybraných příkazů nemůţe nahradit obsáhlé firemní manuály nebo normy, cílem je naznačit syntaktická pravidla nejpouţívanějších tvarů, bez nároků na kompletnost. V úplná syntaxe příkazů je pro svou obsáhlost pro začínajícího uţivatele nepřehledná.
Administrátor nebo uţivatel má podle stupně oprávnění moţnost definovat a vytvořit řadu databázových objektů – od uţivatelsky nejběţnějších aţ po objekty, které definuje administrátor – např. TABLE, VIEW, INDEX, PROCEDURE, FUNCTION, TRIGGER, …, DATABASE, USER, … . Skupiny příkazů mají společnou syntaxi pro vytvoření objektu – CREATE objekt…, zrušení objektu – DROP objekt …, modifikaci objektu – ALTER objekt … .
Náznak základní syntaxe definice tabulky (obsahuje zjednodušení) :
CREATE TABLE [ IF NOT EXISTS ] tabulka_jméno
( sloupec_deklarace, [sloupec_deklarace]*, [TabIntegritníOmezení_deklarace], ... )
sloupec_deklarace ::= sloupec_jméno type [ŘádIntegritníOmezení_deklarace], ...
ŘádIntegritníOmezení_deklarace ::= [ DEFAULT výraz ] [ NULL | NOT NULL ] [ PRIMARY KEY | UNIQUE] [CHECK ( výraz )] [ REFERENCES tabulka_jméno [(sloupec_jméno )] ...]]
type ::= INTEGER | SMALLINT | NUMERIC | DECIMAL | FLOAT | REAL | CHAR | VARCHAR | DATE | TIME | BOOLEAN | …
TabIntegritníOmezení_deklarace :: = [ CONSTRAINT IOomezení_jméno ]
[ PRIMARY KEY ( sloupec_jméno1, sloupec_jméno2, ... )] |
[ FOREIGN KEY ( sloupec_jméno1, sloupec_jméno2, ... ) REFERENCES tabulka_jméno [ ( sloupec_jméno1, sloupec_jméno2, ... ) ] [ ON UPDATE t_akce ] [ ON DELETE t_akce ]] |
[UNIQUE ( sloupec_jméno1, sloupec_jméno2, ... )] | [CHECK ( výraz )]
t_akce :: = NO ACTION | SET NULL | SET DEFAULT | CASCADE
Tabulka má logické jméno a nejméně jeden sloupec. Kaţdý sloupec je logicky pojmenován, má definovaný jednoduchý datový typ (případně zúţený IO check() ) a případnou kombinaci řádkových integritních omezení. Po definici sloupců tabulky můţe následovat definice tabulkových IO pro jedno i více sloţek, sloupců.
Př.:
CREATE TABLE pracovník (
IDpra char (10) NOT NULL ,
Příjmení char (20) NULL ,
Jméno char (15) NULL ,
Číslo_místnosti char (10) NULL
)
Některé modifikace struktury tabulky( tento příkaz se často v některých frázích liší na různých firemních dialektech):
ALTER TABLE tabulka_jméno
[ADD [[sloupec_jméno] sloupec_deklarace] | [CONSTRAINT omezení_jméno IntegritníOmezení_deklarace]]|
[ALTER COLUMN sloupec_deklarace_nová]|
[DROP [CONSTRAINT omezení_jméno]| TabIntegritníOmezení | COLUMN sloupec_jméno ]
Př.:
ALTER TABLE pracovník ADD
CONSTRAINT PK_pracovník PRIMARY KEY CLUSTERED
(
IDpra
)
ALTER TABLE pracovník ADD
CONSTRAINT FK_pracovník_místnost FOREIGN KEY
(
Číslo_místnosti
) REFERENCES místnost (
Číslo_místnosti
) ON UPDATE CASCADE
Zrušení tabulky včetně definice
DROP TABLE tabulka_jméno
Př.
if exists (select * from sysobjects where id = object_id(N'pracovník') and OBJECTPROPERTY(id, N'IsUserTable') = 1)
drop table pracovník
Vytvoření a rušení indexu :
CREATE [UNIQUE] INDEX index_jméno ON tabulka_jméno (seznam_sloupců)
DROP INDEX index_jméno
Klauzule UNIQUE znamená poţadavek jednoznačnosti indexu
4.5.2 Příkazy pro modifikace dat
Vkládání nových řádků se provádí příkazem INSERT. Proti pouţití na počátku je moţno specifikovat i seznam a pořadí sloupců, do kterých se budou hodnoty ukládat a tak není nutné uvádět i hodnoty sloupců nevyplňovaných NULL (protoţe jejich hodnoty nejsou známy nebo budou dopočítány nebo doplněny později).
INSERT INTO tabulka_jméno [ ( sloupec_jméno1, sloupec_jméno2, .... ) ] VALUES ( výraz_1, výraz_2, .... )
Př.
insert into pracovník values ('A','Novák','Petr','10')
Pomocí příkazu INSERT je moţno také naplňovat řádky tabulky hod-notami z jiné tabulky tak, ţe místo klauzule VALUES pouţijeme SELECT, v němţ budou zadány řádky i sloupce jiných tabulek, které se do naší tabulky mají přenést.
INSERT INTO tabulka_jméno [ ( sloupec_jméno1, sloupec_jméno2, .... ) ]
SELECT ...
Změny hodnot v řádcích tabulky
UPDATE tabulka_jméno SET sloupec_jméno1 = výraz1, sloupec_jméno2 = výraz2, ....
[ WHERE výraz ]
Př.
update pracovník set Příjmení = 'Nováková' where IDpra like 'B%'
Rušení řádků tabulky
DELETE [FROM] tabulka_jméno [ WHERE výraz ]
Př.
delete pracovník where IDpra like 'A%'
Výběr informací z tabulky
Následující příkaz SELECT reprezentuje vlastní dotazovací jazyk, jeho pouţitím je moţno nejen vyhledávat údaje v databázi obsaţené, ale i údaje odvozené, případně vhodně setříděné. Základní tvar příkazu je
SELECT [ DISTINCT | ALL ]
sloupec_výraz1, sloupec_výraz2, ....
[ FROM from_clause ]
[ WHERE where_výraz ]
[ GROUP BY výraz1, výraz2, .... ]
[ HAVING having_výraz ]
[ ORDER BY order_sloupec_výraz1, order_sloupec_výraz2, .... ]
sloupec_výraz ::= s_výraz [ AS ] [ sloupec_alias ]
s_výraz ::= *| seznam_sloupců | …
from_clause ::= select_tabulka1, select_tabulka2, ...
from_clause ::= select_tabulka1 LEFT [OUTER] JOIN select_tabulka2 ON výraz ...
from_clause ::= select_tabulka1 RIGHT [OUTER] JOIN select_tabulka2 ON výraz ...
from_clause ::= select_tabulka1 [INNER] JOIN select_tabulka2 ...
select_tabulka ::= tabulka_jméno [ AS ] [ tabulka_alias ]
select_tabulka ::= ( sub_select_statement ) [ AS ] [ tabulka_alias ]
order_sloupec_výraz ::= výraz [ ASC | DESC ]
Pouţití znaku * místo seznamu sloupců znamená výpis všech sloupců tabulky.
Příkaz SELECT A1, A2, . . . , Ak FROM R WHERE podm
odpovídá výrazu relační algebry
(R(podm))[A1, A2, . . . , Ak]
nebo výrazu relačního kalkulu
x.A1, x.A2, . . . , x.Ak | R(x) AND podm
Jednoznačnost prvků výsledné relace nezajišťuje jazyk SQL automaticky, ale musí se zadat v příkazu klauzulí DISTINCT.
Podmínka selekce se zapisuje za klauzulí WHERE. Ve výběrové podmínce je moţno pouţívat :
konstanty, jména sloupců,
relační operátory : = <> < <= > >=
logické operátory : NOT AND OR
další operátory : BETWEEN dolní mez AND horní mez
IN(seznam_prvků_mnoţiny)
IS NULL | NOT NULL
LIKE vzor ... pro porovnání řetězců podobně jako u
hvězdičkové konvence :
% ... odpovídá skupině znaků
_ ... podtrţítko zastupuje jeden znak
SELECT pracovník.*, projektant.Obor AS [obor projektanta], místnost.Plocha AS [plocha místnost]
FROM pracovník INNER JOIN
projektant ON pracovník.IDpra = projektant.IDpra INNER JOIN
místnost ON pracovník.Číslo_místnosti = místnost.Číslo_místnosti
where pracovník.příjmení like 'D%'
order by pracovník.příjmení, pracovník.jméno
Setřídění výsledných řádků podle třídicího klíče, ne podle pořadí uloţení v souboru zajistí klauzule ORDER BY. Pokud jsou v třídicím klíči prázdné hodnoty, uvádí se tyto řádky vţdy na začátku tabulky při sestupném i vzestupném třídění.
Spojení více tabulek (vazba) se provede variantně klasicky i uvedením všech tabulek za FROM a podmínka spojení se uvede jako součást výběrové podmínky za WHERE. Bez této podmínky by se provedl prostý kartézský součin vyjmenovaných tabulek. Rozlišení stejnojmenných sloupců provedeme uvedením jména tabulky před jménem sloupce a oddělením tečkou(tečková notace).
SELECT {seznam_sloupců | *}
FROM seznam_tabulek
[WHERE podm_spojení]
Pokud je název tabulky jako prefix nepohodlně dlouhý, nebo pokud potřebujeme jednu tabulku označit dvakrát pokaţdé jinak (např. pro realizaci unární vazby), můţeme za klauzulí FROM kaţdé tabulce zadat vlastní prefix.
FROM tabulka_jméno1 [AS] P1, tabulka_jméno2 [AS] P2, . . .
4.5.3 Výrazy a funkce, agregované funkce
Pro vytváření výrazů pouţívá SQL aritmetických operátorů a závorek v obvyklých významech. Místo jména sloupce můţeme pouţít výraz, a to v seznamu za SELECT či v podmínce za WHERE. Pokud je výraz pouţit jako prvek seznamu za SELECT a chceme příslušnému sloupci na výstupu přiřadit sloupcový nadpis, zapíšeme ho po mezeře za výrazem. Pokud se nadpis skládá z více slov, uzavírá se do úvozovek.
Dále jazyk SQL pouţívá funkce
aritmetické: POWER(číslo,mocnitel)
ROUND(číslo,poč_des_míst)
ABS(číslo)
SIGN(číslo)
SQRT(číslo)
SIN(číslo) …
řetězcové: LEN (řetězec)
SUBSTRING(řetězec,pozice,délka) výběr podřetězce
UPPER(řetězec)
LOWER(řetězec)
LTRIM(řetězec,mnoţ_znaků) vypustí zleva
RTRIM(řetězec,mnoţ_znaků) vypustí zprava …
datumové a časové: DATEDIFF ( častdatum , stdatum , koDatum ) …
agregované: AVG ({[DISTINCT] sez_výr|*}) průměr
SUM ({[DISTINCT] sez_výr|*}) součet
MIN ({[DISTINCT] sez_výr|*}) minimum
MAX ({[DISTINCT] sez_výr|*}) maximum
COUNT({[DISTINCT] sez_výr|*}) počet
Př.
select count(*) as [celkový počet pracovníků] from pracovník
4.5.4 Agregační funkce se skupinou dat
Tabulku můţeme uspořádat tak, ţe vzniknou skupiny řádků se stejnou hodnotou třídicího klíče. Také pro tyto skupiny můţeme provádět operace (částečné počty, součty ap.). Vytvoření skupin se provede klauzulí GROUP BY klíč
SELECT {seznam_výrazů | *}
FROM seznam_tabulek
GROUP BY seznam_sloupců
Př.
select count(*) as [počet pracovníků v místnosti],Číslo_místnosti as [číslo místnosti] from pracovník group by Číslo_místnosti
Pokud pracujeme se skupinami a chceme formulovat podmínku pro celou skupinu, nejen pro jednotlivé řádky původních tabulek, nedává se tato podmínka za WHERE, ale za HAVING :
SELECT sez-výr
FROM sez_tab
[WHERE podm_pro_řádek]
[GROUP BY sez-klíčů
[HAVING podm_pro_skup] ]
Př.
select count(*) as [počet pracovníků v místnosti],Číslo_místnosti as [číslo místnosti] from pracovník group by Číslo_místnosti having Číslo_místnosti > 10
Syntaxe příkazu SELECT pro mnoţinové operace: např.
SELECT … UNION [ALL] SELECT …
SELECT … INTERSECT SELECT …
SELECT … MINUS SELECT …
Př.
select * from pracovník1
union
select * from pracovník2
4.5.5 Podotázky
V SQL je moţno dotazy řetězit, pro formulaci hlavního dotazu je moţno pouţít výsledků dotazu jiného - poddotazu. Přípustné je pouţít podotázky v podmínce za WHERE podle následujících pravidel :
pokud je výsledkem poddotazu jediná hodnota (relace o 1 řádku a 1 sloupci), pak kdekoliv místo hodnoty:
výraz rel_oper (příkaz SELECT)
pokud je výsledkem poddotazu n-tice hodnot (relace o 1 řádku), pak s relačními operátory = a <> místo n-tice hodnot:
výraz rel_oper (příkaz SELECT)
je-li výsledkem poddotazu mnoţina hodnot (relace o 1 sloupci):
výraz [NOT] IN (příkaz SELECT)
výraz rel_oper {[ANY | ALL]} (příkaz SELECT)
kde pro ANY je minimální a ALL maximální prvek výsledné mnoţiny.
Poddotazy je moţno pouţít za klauzulí WHERE i v příkazech UPDATE a DELETE.
Př.
select pracovník.příjmení from pracovník where pracovník.Číslo_místnosti in (select Číslo_místnosti from místnost where plocha > 100)
4.5.6 Pohledy
Pohled představuje virtuální tabulku - tabulku přímo v databázi neexistující, ale definovatelnou některým příkazem SELECT. Můţe to být projekce či selekce existující tabulky či spojení několika existujících tabulek, můţe obsahovat i sloupce odvozené z existujících hodnot (virtuální sloupce) ap. Pohled se definuje (podobně jako skutečná tabulka) příkazem :
CREATE VIEW pohled AS
SELECT …
Dále se s pohledem pracuje jako se skutečnou tabulkou. Provedeme-li změny v pohledu, změní se i hodnoty v tabulce, z níţ je pohled odvozen a naopak. Problémem je provedení změn ve virtuálních sloupcích, v pohledech setříděných atd., proto konkrétní implementace práci s pohledy omezují jen na některé funkce.
Při vytváření virtuálních sloupců zadáme jména nově vzniklých sloupců za názvem pohledu.
Př.
CREATE VIEW Projektanti_úkoly
AS
SELECT TOP 100 PERCENT projektant.*, Projektant_řeší_úkol.Termín AS [Termín projektanta], úkol.*
FROM projektant INNER JOIN
Projektant_řeší_úkol ON projektant.IDpra = Projektant_řeší_úkol.IDpra INNER JOIN
úkol ON Projektant_řeší_úkol.IDúkol = úkol.IDúkol
ORDER BY projektant.IDpra
4.5.7 Další možnosti SQL
Jiţ jsme uvedli, ţe SQL není jen dotazovací jazyk, ale obsahuje i příkazy další. Především obsahuje všechny potřebné příkazy JDD, definuje, modifikuje a ruší databázi, tabulky, indexy, pohledy. Dále obsahuje příkazy JMD, ukládá data do databáze, modifikuje je a ruší. Dotazovací jazyk pak reprezentuje mocný příkaz SELECT.
SQL zahrnuje také příkazy, slouţící správě databáze pro přidělování přístupových práv na různé úrovni různým uţivatelům:
GRANT privileges ON database_objekt TO ( PUBLIC | user_list )
[ WITH GRANT OPTION ]
Odebrání práv:
REVOKE privilegia_seznam ON database_object
FROM ( PUBLIC | user_list )
Zakázání práv:
DENY privilegia_seznam ON database_object
TO ( PUBLIC | user_list )
privilegia_seznam ::= privilegia1, privilegia2, ...
privilegia::= ALL [ PRIVILEGES ] | SELECT | INSERT | UPDATE |
DELETE | …
database_objekt ::= [ TABLE ] tabulka_jméno | SCHEMA schéma_jméno
seznam_uţivatelů ::= PUBLIC | uţivatel1, uţivatel 2, ...
Příkazy pro řízení transakcí,
BEGIN TRANSACTION, COMMIT, ROLLBACK
pro záznam některých IO, pro vytváření hierarchických struktur dat, pro práci se systémovým katalogem ap..
Příklad ukazující databázové schéma z ER diagramu předešlé kapitoly

Obr. 12 Schéma relací na SQL Serveru
Příklad skriptu
CREATE TABLE místnost (
Číslo_místnosti char (10) CONSTRAINT PK_místnost PRIMARY KEY CLUSTERED ,
Plocha numeric(18, 0) NULL
)
GO
CREATE TABLE pracovník (
IDpra char (10) CONSTRAINT PK_pracovník PRIMARY KEY CLUSTERED ,
Příjmení char (20) NULL ,
Jméno char (15) NULL ,
Číslo_místnosti char (10) NULL,
CONSTRAINT FK_pracovník_místnost FOREIGN KEY
(
Číslo_místnosti
) REFERENCES místnost (
Číslo_místnosti
) ON UPDATE CASCADE
)
GO
CREATE TABLE počítač (
IDpoč char (10) NULL ,
Velikost_disku char (10) NULL ,
Typ char (15) NULL ,
IDpra char (10) NOT NULL,
CONSTRAINT FK_počítač_pracovník FOREIGN KEY
(
IDpra
) REFERENCES pracovník (
IDpra
) ON UPDATE CASCADE
)
GO
CREATE TABLE projektant (
IDpra char (10) NOT NULL CONSTRAINT PK_projektant PRIMARY KEY CLUSTERED,
Obor char (20) NULL,
CONSTRAINT FK_projektant_pracovník FOREIGN KEY
(
IDpra
) REFERENCES pracovník (
IDpra
) ON DELETE CASCADE ON UPDATE CASCADE
)
GO
CREATE TABLE výplata (
IDpra char (10) NOT NULL ,
měsíc char (10) NOT NULL ,
částka char (10) NULL,
CONSTRAINT PK_výplata PRIMARY KEY CLUSTERED
(
IDpra,
měsíc
),
CONSTRAINT FK_výplata_pracovník FOREIGN KEY
(
IDpra
) REFERENCES pracovník (
IDpra
) ON DELETE CASCADE
)
GO
CREATE TABLE úkol (
IDúkol char (10) NOT NULL ,
Název char (20) NULL,
CONSTRAINT PK_úkol PRIMARY KEY CLUSTERED
(
IDúkol
)
)
GO
CREATE TABLE Projektant_řeší_úkol (
IDpra char (10) NOT NULL,
IDúkol char (10) NOT NULL ,
Termín datetime NULL ,
CONSTRAINT PK_Projektant_řeší_úkol PRIMARY KEY CLUSTERED
(
IDpra,
IDúkol
),
CONSTRAINT FK_Projektant_řeší_úkol_projektant FOREIGN KEY
(
IDpra
) REFERENCES projektant (
IDpra
),
CONSTRAINT FK_Projektant_řeší_úkol_úkol FOREIGN KEY
(
IDúkol
) REFERENCES úkol (
IDúkol
)
)
GO
CREATE VIEW Projektanti_úkoly
AS
SELECT TOP 100 PERCENT projektant.*, Projektant_řeší_úkol.Termín AS [Termín projektanta], úkol.*
FROM projektant INNER JOIN Projektant_řeší_úkol ON projektant.IDpra = Projektant_řeší_úkol.IDpra INNER JOIN
úkol ON Projektant_řeší_úkol.IDúkol = úkol.IDúkol
ORDER BY projektant.IDpra
GO
CREATE VIEW Projektanti_místnost
AS
SELECT pracovník.*, projektant.Obor AS [obor projektanta], místnost.Plocha AS [plocha místnost]
FROM pracovník INNER JOIN
projektant ON pracovník.IDpra = projektant.IDpra INNER JOIN
místnost ON pracovník.Číslo_místnosti = místnost.Číslo_místnosti
GO
insert into místnost values ('10',102)
insert into místnost values ('20',24)
insert into pracovník values ('A','Novák','Petr','10')
insert into pracovník values ('B','Dlouhá','Aneška','10')
insert into pracovník values ('C','Vít','Viktor','20')
insert into projektant values ('A','stavební')
insert into projektant values ('B','stavební')
insert into projektant values ('C','stavební')
insert into úkol values ('1','škola')
insert into úkol values ('2','radnice')
insert into Projektant_řeší_úkol values ('A','1','1/3/2004')
insert into Projektant_řeší_úkol values ('A','2','2/3/2004')
insert into Projektant_řeší_úkol values ('B','1','1/3/2004')
insert into Projektant_řeší_úkol values ('C','2','1/3/2004')
insert into počítač values ('1001','160G','aa1','A')
insert into počítač values ('1002','160G','aa1','B')
insert into počítač values ('1003','80G','aa0','C')
select * from Projektanti_úkoly
select * from Projektanti_místnost
drop VIEW Projektanti_úkoly
drop VIEW Projektanti_místnost
drop TABLE Projektant_řeší_úkol
drop TABLE úkol
drop TABLE výplata
drop TABLE projektant
drop TABLE počítač
drop TABLE pracovník
drop TABLE místnost
4.6 Jazyk QBE
Jazyk QBE (Query By Example) byl původně vytvořen v Yorktown Heights firmou IBM (Zloof, 1975) pro pohodlné zadávání výběrových podmínek pro naivní uţivatele. Vytvořil se z něj standard, uţívaný v modifikacích u řady SŘBD. Mezi nejznámější implementace patří Paradox. Je to grafický dotazovací jazyk, zaloţený na doménovém relačním kalkulu. Základem je voudimenzionální syntaxe. Dotazy jsou vyjadřovány interaktivně pomocí příkladů (odtud název jazyka). Tabulky, z nichţ se mají informace čerpat, se formou prázdných tabulkových schémat zobrazují na obrazovce. Dotaz se zapíše tak, ţe do příslušných sloupců prázdné tabulky se vypíší ty hodnoty, které se ve sloupcích hledají. Duplicity jsou většinou implicitně odstraněny.
Výpis všech sloupců se zadá znakem P. (print) pod jméno relace.
Osoba.db | Číslo osoby | jméno | adresa |
Dále existují moţnosti formulace sloţitějších podmínek, spojení( i vnější) více tabulek, třídění, výpočtu agregovaných hodnot, nedefinovaných hodnot, pohledů ap. Jsou podporovány další příkazy DMJ ekvivalent INSERT, DELETE, UPDATE a DDJ - CREATE TABLE(INDEX), , DROP TABLE (INDEX). To vše dělá jazyk QBE podobně silným prostředkem, jako je jazyk SQL.
QBE neumoţňuje hnízdění jako SQL.
4.7 Úvod do OQL
OQL je dotazovací jazyk, který je standardem pro OOSŘBD, část ODMG standardu. Důvody pro jeho vznik jsou například pro uţivatele v jednodušším neprocedurálním formulováním interaktivních ad hoc dotazů, zjednodušeném programování aplikací, moţnosti optimalizace, nezávislost na fyzických datech, pouţití trigerů a integritních omezení a hlavně v moţnosti odstranění nevýhody klasických relačních SQL – coţ je neschopnost vypočítat libovolnou vyčíslitelnou funkci, tj. nejsou výpočetně úplné. Problém síly jazyka se řeší začleněním SQL do procedurálního jazyka, který rozšiřuje sílu dotazu, ale vytvoří se sémanticky i strukturálně nesourodý prostředek ( impedance mismatch). OOSŘBD nabízí moţnost skloubit výpočetní úplnost a homogenitu konstruktů. Manipulačním jazykem je často Smalltalk, C++ nebo Java. Přesto zůstávají některé principiální problémy otevřené. Například otázka porušení zapouzdření objektu při dotazování, formulace dotazu pouze na data nebo i metody. Důleţité je rozhodnutí, jak chápat odpověď na dotaz. Zda výsledkem dotazu budou pouze hodnoty – ve formě datových struktur, sloţených z literálů ( např. tabulky), nebo nové objekty. OQL vychází ze zaběhnutého dotazu v SQL se syntaxí SELECT … FROM … WHERE …s rozšířením o rysy, které přináší ODL, jako jsou metody, strukturované a vícehodnotové atributy, vztahy definované ve třídách. Vyuţití tečkové notace a pojmenování objektů, atributů, metod a vztahů umoţňuje formulovat výrazy, které tvoří u sloţitých objektů cesty.
Např. u.adresa.ulice nebo u.praxe()
Výsledkem dotazu můţe být kolekce struktur ( structs) nebo objektů, vyuţitelná jako extenze.
Základní struktura dotazu je
SELECT < výraz >
FROM <extent>
WHERE < podmínka >
Podobnost s SQL je mimo jiné v pouţití
DISTINCT , EXISTS
Agregačních funkcí COUNT(), SUM(), MAX(), …
Mnoţinové operace UNION, INTRSECT, EXCEPT ( MINUS)
Vyhodnocení podmínky X ANDTHEN Y, X ORELSE Y
{FOR ALL | EXISTS } x IN ( poddotaz ) : ( podmínka )
Další rysy – např. kompatibilita typů, ekvivalence a porovnávání, dědičnost, kolekce různých typů, pohledy
Pro ilustraci uveďme několik jednoduchých příkladů -
1. Dotaz s metodou :
SELECT u
FROM učitels AS u
WHERE u.praxe() > 5
2. Se strukturovaným atributem :
SELECT u, u.adresa.ulice
FROM učitels AS u
WHERE u.adresa.obec = „OLOMOUC“
3. S vazbou N:M, kde se v SELECT frázi vyčíslí obecně mnoţina jmen a výstupem je tabulka se záhlavím (jméno : string, pomocník : SET<string>) :
SELECT u.jméno, (SELECT a.name
FROM u.učí.podporován AS a)
AS pomocník
FROM učitels AS u
Průvodce studiem
OQL je podobný SQL základní konstrukcí SELECT – FROM – WHERE, s rozšířením o komplexní objekty s identitou OID, výrazy v tečkové notaci pro vyjádření cesty ve struktuře objektu, možností využít metod, polymorfizmu a pozdní vazby. OQL může být vnořen do OO programovacích jazyků - Smalltalk, C++ nebo Java.
Shrnutí
Relační algebra tvoří základ pro většinu relačních dotazovacích jazyků.Je to procedurální jazyk vyšší úrovně. Základní operace jsou mnoţinové – sjednocení, průnik, rozdíl, kartézský součin a speciální – projekce, selekce, přirozené i vnější spojení a přejmenování. Selekcí získáme část výchozí relace, jejíţ n-tice vyhovují selekční podmínce. Projekcí se redukuje záhlaví výchozí relace na vyjmenované poloţky – sloupce. Obecné spojení je podmnoţina kartézského součinu relací, porovnávají se všechny kombinace n-tic zúčastněných relací a vybere se dvojice, která vyhovuje spojovací podmínce. Pokud v podmínce porovnáváme všechny sdílené atributy v jedné i na druhé relaci, hovoříme o přirozeném spojení. Vnější spojení – levé, pravé nebo úplné umoţní ve výsledku získat i data z n-tic příslušných (levé, pravé nebo obou) relací, které nevyhovují spojovací podmínce. V takovém případě je v druhé části výsledné dvojice n-tic nedefinovaná hodnota NULL. Pro výběr informací z relační databáze lze vyuţít jazyk logiky - predikátového kalkulu 1. řádu ve formě relačního kalkulu. Je to neprocedurální jazyk, který je moţné pouţít pro porovnání síly relačních dotazovacích jazyků. Jazyk, který dokáţe dotazem získat libovolnou relaci odvoditelnou relačním kalkulem se nazývá relačně úplný. Dotaz má formu výrazu s volnými proměnnými a formulí kalkulu s predikáty. Odpovědí jsou hodnoty, které po dosazení do volných proměnných splňují formuli. Bezpečný výraz určuje pouze konečnou mnoţinu dat v odpovědi. Ke kaţdému výrazu relační algebry existuje ekvivalentní bezpečný výraz relačního kalkulu a opačně, oběma prostředky je moţno vyjádřit stejné třídy dotazů. SQL jazyk je nejdůleţitější uţivatelský databázový jazyk relačních databází ve verzi SQL-92 a objektově-relačních databází ve verzi SQL-99 nebo SQL3. Pro dotazování slouţí příkaz SELECT – FROM – WHERE, pomocí kterého můţeme pouţít všechny operace relační algebry, například pouţitím operátorů UNION, INTERSECT, EXCEPT, JOIN, LEFT JOIN, … . Do frází FROM nebo WHERE můţeme vnořit poddotaz (= další SELECT) například pomocí operátorů EXISTS, IN, ALL, ANY nebo pomocí relačních operátorů =, <>, <, >, … . Výsledky některých operací nemusí tvořit mnoţiny n-tic – např. při pouţití operátoru UNION ALL. Pokud chceme odstranit duplicity, pouţíváme ve správném kontextu operátor DISTINCT. Výstupní n-tice můţeme setřídit operátorem GROUP BY. Pro aritmetické výpočty slouţí agregované funkce SUM, COUNT, MAX, MIN, AVG s moţností aplikace na skupiny n-tic pomocí operátoru GROUP BY a moţností výběru skupin pomocí HAVING. Další příkazy JMD jsou INSERT, DELETE, UPDATE. Příkazy JDD jsou například CREATE TABLE, CREATE VIEW, CREATE INDEX, … , podobně pro modifikaci schématu ALTER TABLE, ALTER VIEW, …, DROP TABLE, DROP VIEW, … . OQL nabízí podobně jako SQL výraz SELECT … FROM … WHERE. V klauzuli FROM mohou být deklarovány proměnné pro libovolné kolekce objektů nebo atributů, extenty tříd, atd. Operátory jsou v plné šíři převzaty z SQL. Je moţné definovat uţivatelské a referenční typy.
Pojmy k zapamatování
Operace relační algebry - sjednocení, průnik, rozdíl, kartézský součin, projekce, selekce, spojení a přejmenování
n-ticový a doménový relační kalkul, bezpečný výraz
jazyk SQL, OQL
Kontrolní otázky
24. Jaké jsou operace relační algebry a jak působí?
25. Jaké jsou druhy spojení a jak se liší?
26. Jak jsou definovány operace relační algebry pomocí relačního kalkulu?
27. Jaký je vztah relační algebry a relačního kalkulu?
28. Jaká je syntaxe hlavních příkazů jazyka SQL?
29. Kde v příkazu SELECT najdeme jednotlivé operace relační algebry?
30. Jak se formulují selekční podmínky?
31. Jak se vnořují podotázky v SQL?
32. Čím se liší OQL od SQL?
Úkoly k textu
Ověřte si prakticky syntaxi příkazu SELECT jazyka SQL na všech operacích relační algebry na dostupném DBS.
Navrhněte a vytvořte na relačním systému jednoduchou databázi a vyzkoušejte příkazy pro vytvoření tabulek a manipulaci s daty.
5 Fyzická organizace dat
Studijní cíle: Student by se měl seznámit se s hierarchií, vlastnostmi a typy pamětí v procesu přenosu mezi hlavní pamětí a vnější pamětí, se strukturou a organizací uloţení dat v souborech s pevnou i proměnnou délkou. Měl by vysvětlit metody přístupu k datům a související podpůrné datové struktury.
Klíčová slova: Poloţka, záznam, organizace souboru, primární sekundární a terciární paměť, hustý index, řídký index, víceúrovňový index, B-strom, ISAM, přímé hašování, nepřímé hašování, statické hašování, dynamické hašování, Faginovo hašování, hašovací funkce, shlukování
Potřebný čas: 3 hodiny
5.1 Databázový přístup k datům
Fyzická reprezentace datové struktury, implementace databázových operací a strategie organizace přenosu dat mezi diskovou pamětí a operační pamětí rozhoduje o efektivitě a úspěšnosti SŘBD. Databáze je typicky uloţena jako kolekce souborů. Při popisu struktury uloţení se setkáme s pojmy jako:
Záznam (věta)
- logický (kolekce logicky souvisejících poloţek, hodnot atributů)
- fyzický ( doplnění o oddělovače a další reţijní poloţky, definice délek, …)
Soubor - homogenní (záznamy stejného typu, pevné délky) a nehomogenní - je identifikovatelná kolekce logicky souvisejících záznamů, seskupená do bloků. Soubory se záznamy s proměnnou délkou mohou obsahovat záznamy různých typů, nebo typ záznamu s proměnnou délkou některých poloţek, ale také s opakujícími se poloţkami. K dalším datovým strukturám patří datový slovník ( jinak systémový katalog) a indexy. Systémový katalog obsahuje mimo jiné metadata schématu databáze, tj. logická jména relací a jejich atributů, domény, IO, pohledy, indexy, …. Dále statistické informace o uloţené databázi.
Záznamy tedy mohou být v databázi uloţeny fyzicky různým způsobem a v průběhu zpracování se nachází v různých typech pamětí s klasifikačními parametry, jako jsou rychlost přístupu, cena za jednotku dat, spolehlivost a chování při ztrátě napájení nebo poruše zařízení.
Hierarchie pamětí v DBS je na následujícím obrázku
Terciální paměť je velkokapacitní (TB), často se sekvenčním přístupem, s příznivým poměrem cena/ byte, s pouţitím například pro zálohování systému. Sekundární disková paměť je typicky rychlejší, s přímým přístupem, zabezpečena proti ztrátě informace při poruše disku ( disková pole RAID s úrovněmi 4-6 se samoopravnými kódy ), se standardními konstrukčními prvky. Proto u disků můţeme dobu přístupu (čas od poţadavku na čtení nebo zápis a počátkem přenosu dat) rozdělit na čas nastavení hlavičky disku na poţadovanou stopu (Seek time ~ 1-20 ms) a čas, kdy se disk otočí do polohy, kdy hlavička je u poţadovaného sektoru na stopě (Rotational latency ~ 0-10ms). Další důleţité parametry jsou rychlost přenosu dat (Data-transfer rate ~ 1ms/4kB) a průměrná doba mezi poruchami disku (Mean time to failure). Diskovou adresu na fyzické úrovni proto tvoří označení diskové jednotky, číslo cylindru, stopy a sektoru.
Blok je souvislá sekvence sektorů z jedné stopy a zároveň je základní jednotkou pro přenos dat mezi pamětí vnitřní a vnější. Rychlost přenosu se měří i u rychlých systémů v ms, rychlost operací ve vnitřní (hlavní) paměti je řádově měřena v μs a vyšší. Tedy rychlost zpracování dat záleţí na počtu přenosů dat mezi diskem a primární pamětí a prakticky nezáleţí na počtu operací v hlavní paměti , případně paměti typu CAHE ( statická paměť typu CACHE je nejrychlejší, ale i nejdraţší a stejně jako hlavní paměť je energeticky závislá). Dalším typem paměti, jeţ zatím není tolik rozšířen, je paměť FLASH. Ta je energeticky nezávislá a srovnatelně rychlá, jako operační paměť, ale počet přepisovacích cyklů paměti je limitován.
Ilustrační příklad vyhledání záznamu na disku :
Na základě logické podmínky pro záznam určíme logickou adresu záznamu IDZ, tj. dle okolností pořadové číslo záznamu pro soubor s pevnou délkou nebo adresu v rámci souboru. V obou případech lze pak určit číslo bloku bn v souboru IDS, ve kterém je záznam uloţen a určit začátek záznamu v bloku. Dále odvodíme z čísla bloku fyzickou adresu záznamu, tedy číslo válce, stopy a sektoru.
První etapu řeší SŘBD: v průběhu zpracování aplikace nebo zadáním dotazu pomocí dotazovacího jazyka je zadána logická podmínka, se kterým záznamem se bude pracovat.
Druhou etapu řeší obvykle součást operačního systému - subsystém ovládání souborů. Ten na základě zadaného čísla bloku v souboru spočítá absolutní číslo válce, stopy a sektoru. Pak na základě pořadí záznamů v bloku určí hledaný záznam.
S rychlostí přístupu k datovým souborům souvisí také vyuţívání vyrovnávací paměti, její velikosti a ovládání. Ovládání se řeší na několika úrovních : v rámci OS, nastavením velikosti CACHE paměti, případně si vyrovnávací paměť řídí SŘBD sám. Volí se různé strategie výměny bloků (LRU - least recently used – uvolňuje se blok, se kterým se nejdéle nepracovalo,FIFO, MRU- Most recently used s fixací bloků (Pinned block), které se nevrací na disk ). Snaha o předvídání potřeby následujících bloků z analýzy vyuţití předešlých bloků i modelu chování a jejich přesunutí do vyrovnávací paměti. Implementace vyhodnocení dotazů má obvykle předvídatelně definované modely chování, které se dají po získání informací z DBS o uţivatelském dotazu pouţít jako předloha pro předpověď vyuţitelných následujících bloků. LRU například selhává u dotazů, kdy opakovaně pracujeme a vracíme se k jiţ pouţitým datům. Manaţér vyrovnávací paměti můţe vyuţít statistické informace k odhadu pravděpodobnosti pouţití bloků na disku, proto jsou ve vyrovnávací paměti bloky systémového katalogu a indexů.
5.2 Organizace souborů
Počet přístupů závisí také na organizaci uloţení dat v diskových souborech. Při popisu následujících technik budeme předpokládat soubory s pevnou délkou záznamu. Jazyky třetí generace nabízely sekvenční, index-sekvenční a indexované organizace, vhodné spíše pro statické - neaktualizované databáze. S počtem aktualizací narůstají problémy s výchozím, pevně vymezeným diskovým prostorem a řešením jsou neefektivní techniky, vedoucí na řetězení záznamů v přetokových oblastech. Odpovědí jsou dynamické organizace dat, kdy i při aktualizacích databáze je rychlost vyhledání konstantní, nebo logaritmická. Přesto se v DBS můţeme stále setkat se všemi uvedenými postupy. Záznamy mohou být obecně organizovány několika základními způsoby v mnoha alternativách, z nichţ kaţdý můţe být optimální v jisté situaci a méně vhodný v jiné. Nejčastější formy:
Hromada/ nesetříděné – záznamy mohou být umístěny v souboru kdekoliv je volné místo, bez jakéhokoliv uspořádání. Organizace vhodná pro případ zpracování všech nebo většiny záznamů.
Sekvenční - záznamy jsou ukládány sekvenčně v uspořádání podle pořadí vkládání záznamů nebo
Setříděné - podle vyhledávacího klíče. Vhodné pro případ, kdy zpracování informace probíhá při jistém uspořádání záznamů nebo pro jistý interval hodnot.
Indexované – pomocná datová struktura (index) urychluje přístup do hlavního datového souboru
Hašované – hašovací funkce z klíčového atributu vypočte fyzickou adresu bloku ukládaného nebo uloţeného záznamu. Vhodné pro vyhledávání na rovnost.
Shlukované (Clustering) – záznamy různých typů jsou uloţeny v jednom souboru, související záznamy jsou uloţeny ve stejném bloku. Vhodné pro efektivní spojování zúčastněných relací.
Průvodce studiem
Fyzický návrh databáze je postup popisující implementaci databáze na discích počítače. Určuje bázové relace a jejich uložení na disku a přístupové metody tak, aby systém pracoval efektivně i při splnění podmínek integritních omezení a bezpečnostních hledisek, vždy v návaznosti na podporu poskytovanou SŘBD. V prvním kroku se provede transformace integrovaného logického schématu do formy implementovatelné SŘDB, dále se navrhuje organizace souborů, přístupové metody, volba indexů, odhaduje prostor na disku, potřebný k implementaci.
5.2.1 Sekvenční soubory
Nejjednodušší organizací, vycházející z přirozeného uspořádání záznamů podle pořadí jejich uloţení, jsou sekvenční soubory. Věty jsou uloţeny v souboru v libovolném pořadí v blocích, které mohou následovat fyzicky za sebou(v následujícím cylindru, stopě) a díky eliminaci nebo minimalizaci mechanických přesunů hlavičky a předvídané načítání několika bloků najednou do vyrovnávací paměti (pre-fetching) je sekvenční přístup rychlejší neţ náhodný. Pokud bloky nenásledují fyzicky za sebou ( sekvence je na vyšší logické úrovni) , jsou propojeny ukazateli (obsazené i uvolněné bloky), nebo jsou adresy bloků souboru někde uloţeny - obvykle řeší OS. Implementace sekvenčních souborů je nejjednodušší.
Provádění databázových operace - nový záznam se uloţí jednoduše na konec souboru.Pro vyhledání záznamu je nutno prohledávat datový soubor sekvenčně : kaţdý záznam postupně načíst a otestovat, zda vyhovuje podmínce. Vyhledávání sekvenční potřebuje průměrně n/2 porovnání nebo n/(2*fR) přístupů na disk. Číslo n znamená počet záznamů a číslo fR je blokovací faktor, znamená počet záznamů v bloku. Modifikace záznamu znamená tyto operace : nalézt záznam, načíst, opravit a na stejnou adresu znovu zapsat. Zrušení záznamu u sekvenčních souborů se obvykle provádí označením jeho neplatnosti, ne vymazáním. K označení neplatnosti se obvykle vyhradí místo v záznamu (bit, byte) a vlastní poloţky záznamu zůstanou zachovány. Při zpracování se záznamy označené jako neplatné nezpracovávají. "Díry" po zrušených záznamech postupně zabírají v souboru místo. Je moţné zbavit se těchto poloţek a soubor setřást. Jiná moţnost je vyuţít prázdných míst při vkládání nové věty, záznam se uloţí do prvé díry po vypuštěné větě, nebo se uloţí na konec souboru, pokud díra neexistuje. Ovšem pak se i operace vloţení věty provádí průměrně pomocí n/2 přístupů na disk.
Mají-li věty klíče, musí se prohledat celý soubor a zkontrolovat jedinečnost klíče vkládané věty.
5.2.2 Setříděné sekvenční soubory
Pokud se v souboru často vyhledává podle některého klíče (zde myslíme vyhledávací klíč, coţ nemusí být vţdy primární klíč) a provádí se relativně málo změn těchto klíčů, je vhodné uchovávat soubor v setříděném tvaru. Znamená to po kaţdé změně (vloţení nové věty nebo modifikaci klíče) znovu soubor setřídit. Pak se dá vyhledávat podle klíče mnohem rychleji (např. metodou půlení intervalu nebo některou její modifikací). Počet přenosů pro binární hledání je průměrně log n.
Někdy se metoda vylepšuje tak, ţe provádíme interpolaci na základě znalosti statistického rozloţení hodnot klíče v tabulce.
Jestliţe vyţadujeme, aby záznamy byly nějakým způsobem setříděny, je moţno pouţít také zřetězení záznamů. Proti sekvenčnímu souboru obsahuje kaţdý záznam navíc jednu poloţku. V ní je ukazatel na následující záznam v souboru podle daného uspořádání. V souboru tak je vytvořen seznam či řetěz vzájemně propojených záznamů, seznamy mohou realizovat uspořádání dle libovolného kritéria.
5.2.3 Indexování
Datové záznamy jsou v indexovaném sekvenčním souboru, ke kterému existuje jedna nebo několik dalších pomocných struktur, uloţených v indexovém souboru, pomocí nichţ můţeme v datovém souboru rychleji hledat. Indexové soubory jsou podstatně menší neţ datové.
Indexování je zaloţeno na principu rychlého nalezení dvojice - vyhledávací klíč, (fyzická) adresa záznamu, která je uložena v pomocné struktuře – indexu. Ukazatele nemusí být tedy součástí záznamů (jako u zřetězených organizací), ale mohou být uloţeny zvlášť.
Správa pomocných indexových struktur při manipulaci s daty zabírá čas. Proto mezi sledovaná kritéria při pouţití indexů počítáme nejenom zrychlení při vyhledávání, ale i zpomalení při vkládání a mazání dat. Indexem nemusí být jen primární klíč, ale kterákoliv poloţka souboru nebo seznam několika poloţek.
Primární index – jeho vyhledávací klíč(obsahuje klíčové atributy) určuje uloţení záznamu.
Sekundární index – jeho vyhledávací klíč neurčuje uloţení záznamu.Realizován mapováním do datového soboru nebo do hodnot primárního klíče. Můţe být i více sekundárních indexů k jednomu datovému. Pro sekundární index se také pouţívá název invertovaný soubor.
Jednoduché indexování :
Hustý index – v indexu jsou sekvenčně uloţeny a setříděny všechny vyhledávací klíče datového souboru s příslušnými odkazy IDZ. Datový soubor je typicky nesetříděný podle vyhledávacího klíče. Jednomu indexovému záznamu odpovídá jedna hodnota vyhledávacího klíče v datovém souboru.
Řídký index – v indexu jsou sekvenčně uloţeny a setříděny některé vybrané vyhledávací klíče datového souboru s příslušnými odkazy. Datový souboru je setříděný podle vyhledávacího klíče. Jednomu indexovému záznamu odpovídá řada hodnot vyhledávacího klíče v datovém souboru. Typicky odkaz indexovému záznamu určuje právě jeden datový blok.
V některých aplikacích mohou být klíče velmi dlouhé. Pak se také místo v paměti zvětšuje a se zvětšováním délky klíče se prodluţují seznamy záznamů, odkazující na shodné hodnoty podklíče. Pak se prodluţuje i hledání v takových indexech. Proto se někdy ukládají klíče v indexech zkráceným způsobem tak, ţe je v tabulce uloţena předpona klíče a je připojen seznam přípon s adresami, potom další předpona atd. Stejná metoda je pouţívána v jazykových slovnících.
Jednoduché indexování (lineární, jeden index na záznam) můţe vést k velkým a neefektivním indexovým souborům. Proto se pouţívají sofistikovanější postupy. Přechodem k nim je: Víceúrovňový index – struktura „index na index“, je moţno pro hledání v indexovém souboru pouţít opět indexový soubor a sestrojit tak celou hierarchii indexových souborů. Typicky je na vyšších úrovních pouţit řídký index a na nejniţší úrovni je pouţit hustý index.
Dalším vylepšením je pouţití stromových struktur, které podporují dotazy na rovnost i na interval hodnot. Pro statičtější případy databází se pouţívají struktury ISAM (Indexed Sequential Access Method) se sekvenčním i náhodným, indexem podporovaný přístupem(index-sekvenční soubor), pro dynamičtější případy jsou pouţívané B+ stromy. Základem obou přístupů jsou varianty stromových struktur. Nejefektivnější jsou varianty B stromu , s poţadavkem vyváţenosti(všechny cesty od kořene stromu do libovolného listu jsou stejně dlouhé), nelistový uzel je chápán jako blok se strukturou (po, K1, p1, K2, p2, …, Kn, pn). Kde pi jsou ukazatele na následníky, Ki jsou vyhledávací klíče, pro které platí K1< K2 < K3 < … < Kn .Kaţdý uzel má nejvýše m a nejméně m/2 následníků. Levý podstrom klíče Ki obsahuje klíče menší nebo stejné neţ Ki, pravý podstrom naopak klíče větší. V listových uzlech jsou všechny vyhledávací klíče s odkazy do datových stránek (B+ stromy), doplněné o ukazatel na následující listový uzel (blok) pro rychlé sekvenční čtení dat. Počet přístupů na disk při vyhledávání odpovídá výšce stromu ~ logm n, kde n je počet klíčů primárního datového souboru. Vyváţenosti při manipulaci s daty se u B-stromů dosahuje štěpením a sléváním uzlů, u ISAM, s nemodifikovatelnou strukturou vnitřních uzlů stromu, pomocí přetokových bloků (stránek).
Při vyhledávání datového záznamu najdeme cestu ve stromě od kořene aţ k listu, v němţ by měl být hledaný záznam (pokud v souboru existuje). V kaţdém uzlu najdeme správnou větev porovnáním hledaného klíče s klíči v uzlu. Klíče v uzlu mohou udávat minimální (příp. maximální) hodnotu klíče, která je příslušnou větví dosaţitelná v podstromu. Modifikace záznamu je z hlediska vyhledávání triviální. Ilustračně popíšeme zbylé manipulace.
Při vkládání nového záznamu najdeme příslušný blok a mohou nastat dvě moţnosti : buď v nalezeném bloku je dostatečný prostor, takţe můţeme přidat vkládaná data, nebo nalezený blok je plný, takţe musíme vytvořit nový blok; z původního plného bloku vytvoříme dva bloky. Do vyšší úrovně musíme nový blok niţší úrovně zaznamenat a opět mohou nastat dva případy. Proces se opakuje aţ do kořene stromu a případně se musí kořen rozdvojit. Pak se přidá nový kořen a vznikne další úroveň v indexové struktuře.
Rušení záznamů se provádí opačně, neţ vkládání. Při zrušení posledního záznamu bloku se zruší i odkaz na něj, totéţ se promítne do vyšších úrovní, případně se v krajním případě můţe hierarchie indexů o jednu úroveň sníţit – rozhoduje o tom obsazení uzlů.
Průvodce studiem
Index je pomocná struktura, ve které je efektivním způsobem zpřístupněna uložená dvojice <klíč, adresa záznamu>. Hašování pomocí hašovací funkce, parametrizované klíčem, určí adresu uložení, použitelnou i při vyhledávání záznamu výpočtem.
5.2.4 Soubory s přímým adresováním - hašování
Velmi rychlý přístup k záznamům prostřednictvím klíčů zajišťuje metoda přímého adresování. Teoretický princip metody je tento - jednoznačný klíč záznamu se pomocí hašovací funkce transformuje do jednoznačného čísla, které určuje adresu záznamu v souboru. Tak je moţné jediným přístupem na disk záznam načíst, případně zapsat. Poţadavkem na hašovací funkci je zajištění rovnoměrného rozloţení obsazených míst adresového prostoru i pro náhodné aktuálně zpracovávané hodnoty klíče. Hašování můţe být:
přímé ( výsledkem hašování je adresa v primárním datovém souboru)
nepřímé( výsledkem hašování je adresa sektoru ukazatelů)
statické (velikost adresového prostoru je konstantní)
dynamické(velikost adresového prostoru se přizpůsobuje potřebám)
Problémem statického hašování jsou kolize a velikost adresového prostoru. Kolize jsou důsledkem vlastnosti kaţdé běţně pouţívané hašovací funkce, kdy několika vyhledávacím klíčům odpovídá stejná adresa - Fhaš ( K1) = Fhaš ( K2).
Na jedné adrese ale nemůţe být více záznamů. Situace se pak řeší různými technikami. Mezi nejjednodušší způsoby patří postup, kdy všechny záznamy, určené hodnotou hašovací funkce do jednoho adresového prostoru se zřetězí do seznamu záznamů. Kdyţ se do databáze přidává mnoho nových záznamů, adresový prostor je více zaplněn a dochází často ke kolizím a zřetězení záznamů vede ke zmenšování rychlosti vyhledání – proces se blíţí sekvenčnímu vyhledávání. To vede k opakované reorganizaci – nová velikost adresového prostoru, nová hašovací funkce. Další moţností je pouţití přetokové oblasti, nebo dynamicky modifikované vícenásobné hašovaní a další strategie.
Dynamické hašování nabízí mnoho sofistikovaných postupů, jak se problémům statického hašování vyhnout. Typickým příkladem je Faginovo hašování:
Hašovací funkce transformuje vyhledávací klíč do binárního řetězce. Je pouţita pomocná dynamická struktura – adresář. Ten můţe být modelován jako tabulka s jedním sloupcem prefixů zahašovaných klíčů a druhým sloupcem odkazů na paměťové bloky. Podle aktuální potřeby bloků paměti se mění velikost adresáře na 2n, kde n je délka prefixu (v našem případě n=3, velikost je 8). Délka prefixu (hloubka adresáře) je zaznamenána v hlavičce adresáře. Podobně je umístěna odvozená veličina, tzv. lokální hloubka - n´, v kaţdé paměťové stránce. Pro vloţení a vyhledání záznamu platí stejné postupy. Z bitového řetězce po hašování je oddělen prefix s aktuální délkou n. Ve sloupci adresáře, kde jsou všechny kombinace binárních řetězců dané délky, je nalezen řádek s odpovídající hodnotou prefixu a zároveň odkazem na blok paměti, kde je nový záznam umístěn, nebo starý nalezen. Pokud při vkládání je určen plný blok a pro jeho n´ platí n´ < n, tak operační systém dodá nový paměťový datový blok, zvětší se n´ na n´ = n´ + 1 a záznamy z původní stránky se rozdělí do obou bloků podle nového prefixu n´. Zároveň se opraví příslušný odkaz v adresáři na nový blok. Pokud ale n´ = n, zvětší se prefix n na n = n + 1, adresář se zdvojnásobí a dále se postupuje stejně jako v předešlém případě. Při mazání záznamů se kontroluje obsazení bloků a pokud to podmínky dovolí, dojde ke slévání stránek a případně zmenšení adresáře opačným postupem.
5.2.5 Shlukování – clustering
Techniky shlukování umoţňují uţivateli ovlivnit fyzické uloţení záznamů tak, ţe v jednom paměťové bloku ( nebo z hlediska přístupu blízkém) jsou umístěny záznamy různých typů se stejnou hodnotou v atributech spojovací podmínky, figurující v nejfrekventovanějších dotazech uţivatelů. Schématicky pro vazbu 1:N mezi relací R a S s vazebním atributem a se organizace souboru dá znázornit
Blok: b1 (R1.a = S1.a = S3.a = S4.a, …) | b2 (R3.a=S7.a, R4.a=S8.a=S9.a) |
R1 | S1 | S3 | S4 | R2 | S5 | S6 | R3 | S7 | R4 | S8 | S9 | |
| | | | | | | | | | | | | |
Existují dva typy shluků - indexované a hašované. Zhruba platí, ţe u spojení dvou tabulek pro vytvoření jednoho spojeného záznamu je třeba dva přístupy na disk při klasickém uloţení a jen jeden při pouţití shlukování. Protoţe se jedná o fyzické uloţení, je moţné takto preferovat jenom jednu skupinu dotazů, pro ostatní to neplatí – vazby na ostatní tabulky, prostřednictvím jiných vazebních atributů.
5.2.6 Indexování pomocí binární matice
Pro sekundární indexování se někdy pro ušetření kapacity pouţívá jiného způsobu - binárních matic. Poloha záznamu se bude zaznamenávat polohou jedničkového bitu v posloupnosti, která má tolik bitů, kolik má soubor záznamů. První bit odpovídá prvnímu záznamu, druhý druhému atd. Pro kaţdou hodnotu sekundárního atributu je zaznamenána nová posloupnost. Zřejmě je tato metoda vhodná pro takové atributy, které nabývají jen několika různých hodnot.
Binární matice jsou zvlášť výhodné v případech, ţe se hodnoty sekundárních atributů nebo záznamy nemění. Hlavní výhodou binárních matic je rychlá realizace kombinovaných dotazů pomocí logických operátorů negace, konjunkce a disjunkce.
5.2.7 Soubory s proměnnou délkou záznamu
Dosud jsme předpokládali pevnou délku záznamů. Jejich implementace je výrazně jednodušší a mnohé SŘBD jinou moţnost nepřipouští. Ovšem z reality plyne často poţadavek na sloţitější strukturu. Jde např. o jiţ zmiňované opakující se poloţky (pole) předem známým počtem i předem neznámým počtem, o skupinové poloţky, dále o dlouhé texty různé délky, o záznamy obrázků, zvuků (datový typ BLOB, CLOB, …) a mnohé jiné datové typy.
Pouţívání souborů s proměnnou délkou záznamu vede k řadě nových problémů. Často se úvahy o datových typech vedoucích k proměnné délce záznamu vyskytují jen v logickém modelu a implementace se provádí pomocí záznamů pevné délky. Novější SŘBD však stále častěji připouštějí různé datové typy proměnné délky a také je tak implementují. Hlavní metody těchto implementací jsou následující :
1. Vyuţití pevné délky záznamu
Takto nazveme případ, kdy se logicky proměnná délka záznamu implementuje jako záznam s pevnou délkou. Pouţívají se k tomu následující způsoby:
pole se známým počtem opakování: pole atomických poloţek se rozloţí na jednotlivé poloţky, kaţdá dostane vlastní jméno a pracuje se sní samostatně.
pole s neznámým počtem opakování odhadne se shora počet výskytů prvků pole a tak se převede na předcházející případ. Můţe se stát, ţe značná část prvků pole bude nevyuţitá; další problém je rozpoznání prázdného prvku
místo opakující se poloţky uvedeme odkaz na seznam jejích prvků, ten můţe být součástí jiného souboru;
pro záznamy s alternativními skupinami poloţek buď se proměnná část "překrývá" a záznam zabírá velikost nejdelší z proměnných částí, avšak v záznamu se musí rozlišovat typ proměnné části a implementace je sloţitější, nebo se všechny rozdílné atributy zaznamenají "za sebou" a pro kaţdý typ se vyplňují jen odpovídající atributy; implementace je jednodušší, záznam však obsahuje vţdy řadu prázdných poloţek.
terciární páskovou nebo CD ROM pamětí. Pro rychlé zpracování dat je rozhodující práce manaţeru dat a disku se strukturou dat na disku, organizací sektorů a bloků, spolupráce operační paměti, vyrovnávací paměti a disku. Existuje mnoho způsobů, jak zrychlit přístup k datům. Mezi často pouţívané patří metoda rozdělení dat mezi několik diskových jednotek s vyuţitím souběţného přístupu, pouţití zrcadlových disků s udrţováním několika kopií dat rovněţ s moţností souběţného přístupu. Dále se klasicky vyuţívá konstrukce disku a organizace dat pro souběţný přístup na stopy nebo cylindry disku s uchováním maximální velikosti dat ve více vyrovnávacích pamětích a sofistikovaných algoritmech predikce následně pouţitých bloků dat. Disková zařízení musí být schopná maximálně eliminovat případné chyby. K odhalení slouţí klasické cyklické součty, parita, atd., ale uţitečnější jsou postupy umoţňující opravy případných chyb. RAID úrovně 1 vyuţívá zrcadlení, RAID úrovně 4 pouţívá disk, jehoţ obsah je paritním součtem korespondujících bitů ostatních disků. RAID úrovně 6 umoţňuje pouţití samoopravné korekce chyb a zvládne odstranit chyby i u několika souběţných poruch ve skupině disků. Poloţky nebo záznamy tvoří základ struktury uloţení. Mohou být obecně pevné ( standardní atomické typy – INT, CHAR(15), atd.), nebo proměnné délky. Záznamy mohou obsahovat hlavičku s informací o struktuře poloţek, délce a podobně. Tyto informace jsou nezbytné u organizací s různou délkou poloţek nebo záznamů. Záznamy jsou organizované v blocích, které rovněţ ve své hlavičce udrţují informace o datové struktuře bloku. Velké záznamy informací ve formě obrázků, zvuků atd. jsou typu BLOB (binary large object) a typicky zaberou několik bloků, nejlépe na jednom cylindru. Záznamy mohou být obecně organizovány ve formě hromady, sekvenční, setříděné, indexované, hašované a shlukované. Hustý index představuje pomocnou strukturu, ve které jsou uloţeny dvojice klíčová hodnota – adresa v datovém souboru pro všechny n-tice v nesetříděném datovém souboru. Řídký index naopak ukládá dvojici klíčová hodnota – adresa na první poloţku v bloku setříděného datového souboru. Víceúrovňový index vytváří další index na existující index nebo indexy. Efektivnější podpory přístupu je docíleno stromových organizací ISAM a hlavně dynamického vyváţeného B-stromu, jehoţ nelistové uzly obsahují n klíčů a n+1 odkazů a listy stromu odkazy do datového souboru. Obsah uzlu kolísá mezi polovičním a úplným obsazením. Pro dotazy, ve kterých figuruje poţadavek na rozsah hodnot je výhodné pouţít B+ stromy se zřetězením listů podle poţadovaného uspořádání. Pro dotazy na izolované hodnoty se naopak hodí hašování, kde hašovací funkce podle klíčového parametru určí adresu uloţení i vyhledání v datovém souboru. Dynamické hašování umoţňuje přizpůsobovat velikost adresového prostoru aktuálním poţadavkům. Velice efektivní podpora rychlosti zpracování souvisejících dat spočívá ve shlukování, tj. uloţení souvisejících dat do jednoho prostoru – bloku nebo sousedících bloků.
Pojmy k zapamatování
Sekvenční soubor, soubory s proměnnou délkou záznamu
hustý index, řídký index, víceúrovňový index, B-strom, ISAM
statické a dynamické hašování
Kontrolní otázky
33. Jaké jsou vlastnosti jednotlivých druhů paměti?
34. Jaké jsou formy organizace záznamů?
35. Co je to index a jaké druhy indexů znáte?
36. Jaké vlastnosti má B-strom?
37. Čím se odlišují indexování a hašování?
38. Jak pracuje Faginovo hašování?
39. Jak jsou organizovány soubory s proměnnou délkou záznamu?
40. Co je to shlukování
6 Zpracování dotazu
Studijní cíle: Po zvládnutí kapitoly bude studující schopen popsat jednotlivé fáze zpracování a optimalizaci dotazu a odpovídající softwarové moduly, popsat přepisovací pravidla algebraické optimalizace, způsoby reprezentace výrazu dotazu a optimalizační heuristiky. Seznámí se s vybranými statistikami databáze a jejich vyuţitím pro optimalizaci, dále s moţnostmi implementace klíčových databázových operací
Klíčová slova: Optimalizace dotazu, algebraické přepisování, heuristika optimalizace dotazu, databázová statistika, implementace operací,
Potřebný čas: 2 hodiny
Zpracování dotazu je rozdílné podle typu SŘBD. Hierarchické a síťové databáze mají DMJ niţší úrovně a optimalizaci řeší aplikační programátoři. Relační systémy mají dotazovací jazyk vyšší úrovně a optimalizaci provádí SŘBD. Modul pro zpracování dotazu – dotazový procesor zahrnuje komponenty, které optimalizaci provádí ve dvou fázích – logické a fyzické. V logické části se transformuje dotaz v interní formě (relační algebra) na ekvivalentní výraz s efektivnějším vyhodnocením. Výraz dotazu určuje posloupnost databázových operací a ve fyzické fázi optimalizace se určuje, jakým způsobem se provedou operace v závislosti na fyzické struktuře uloţení a podpoře. Optimalizace se podílí rozhodujícím způsobem na komerčním úspěchu SŘBD, protoţe rozhoduje o rychlosti odezvy DBS. Ve výrazu dotazu jsou pouţita logická jména tabulek a sloupců, pohledů, … , čili se předpokládá uţivatelova znalost schématu databáze.
6.1 Základní etapy
Základní postup zpracování dotazu:
1. analýza a překlad dotazu – SQL dotaz se po kontrole syntaxe vhodným lexikálním a syntaktickým analyzátorem a po ověření sémantiky dotazu - logických jmen ( relací, atributů, typů …) preprocesorem pomocí informací v katalogu, se přeloţí do interní formy niţšího dotazovacího jazyka (relační algebry nebo relačního kalkulu). Obvykle se provede konverze do kanonického tvaru. Forma lineárního výrazu dotazu se obvykle transformuje do stromové struktury – parse tree ( listy stromu jsou zúčastněné relace, vnitřní uzly představují operace relační algebry, kořen pak dává výsledek dotazu). Pokud výraz projde všemi kontrolami, vygeneruje se z něj výchozí logický plán dotazu.
2. optimalizace – hledání nejrychlejšího plánu vyhodnocení s dosaţitelnými zdroji ( statistiky o databázi, omezení hlavní a vyrovnávacích pamětí, podpůrné indexy, …), jinak formulováno – systém hledá optimální pořadí operací, které provádí dotaz a vybírá nejvhodnější metodu přístupu do databáze – např. existující primární nebo sekundární indexy na jedno nebo vícesloupcové poloţky (případně dočasně vytvořené pro účel optimalizace přístupu), hašování, … . Pro optimalizaci se vyuţívají i statistiky, získané z katalogu ze subsystémů uloţení dat na disku. Optimalizace má tedy dvě fáze: logickou – algebraické přepisování a fyzickou – volba algoritmů.
3. vyhodnocení – vyhodnocovací stroj převezme prováděcí plán vyhodnocení – optimální pořadí operací relační algebry a na základě nejvýhodnější implementace operací vyhodnotí dotaz. Faktory ovlivňující rychlost vyhodnocení jsou např.:
Fyzická organizace uloţených záznamů v relaci
Zda diskový blok obsahuje záznamy jedné relace nebo několika (shlukování)
Pouţité algoritmy operací (hlavně časově náročného spojení)
6.2 Optimalizace dotazu
Výraz relační algebry se dá vyhodnotit obecně mnoha způsoby. V první fázi se typicky generují ekvivalentní výrazy k výrazu, vygenerovanému překladačem vstupního SQL dotazu. Ekvivalentní výrazy jsou různé tvary výrazu dotazu v relační algebře, které po vyhodnocení vygenerují stejná výstupní data. Podle konceptu by se měly systematicky na kaţdý nový podvýraz opakovaně aplikovat všechna dále uvedená pravidla, aby se postupně vygenerovaly všechny ekvivalentní výrazy. Tento postup je velmi časově i prostorově náročný. Prostor se dá ušetřit sdílením podvýrazů, čas se šetří tím, ţe se negenerují všechny výrazy.
