Testovací případ |
| Kategorie : Software | Podkategorie : | Tutoriálů: 1 |
| POPIS:
V softwarovém inženýrství je testovací případ souborem podmínek, za kterých tester určí, zda aplikace, softwarový systém nebo jedna z jeho funkcí funguje tak, jak bylo původně zamýšleno. |
Testovací případ
Testovací případ (test case) definuje postup, jak otestovat daný požadavek. Pokud hovoříme o požadavcích, máme na mysli funkční a nefunkční požadavky uváděné většinou v SRS (Software Requirements Specification) dokumentu. Testovací případ popisuje, jak otestovat požadovanou funkčnost, to znamená, co má být zadáno na vstupu a co lze očekávat na výstupu. Testovací případy si můžeme rozdělit na logické a fyzické.
Logický testovací případ (logical test case) je abstraktní popis toho, co se má otestovat, definuje obor a množinu hodnot.
Fyzický testovací případ (physical test case) je konkrétní popis toho, co se má otestovat, definuje jaké hodnoty se mají zadat.
Doporučuji vždy začít návrhem logického testovacího případu a poté k němu vytvořit odpovídající fyzické testovací případy (obvykle k jednomu logickému případu existuje několik fyzických). Každý testovací případ by měl:
mít přidělen jednoznačný identifikátor,
mít stanovenu prioritu,
obsahovat stručný popis předmětu testu,
uvádět, jaké hodnoty se mají zadat na vstupu,
uvádět, jaká je očekávaná doba zpracování,
uvádět, jaké hodnoty je možno očekávat na výstupu,
mít předepsáno na jaké HW a SW konfiguraci se má test provést,
uvádět, jaký test má tomuto testu předcházet.
Nyní si výše uvedené požadavky na ideální testovací případ stručně popišme.
Jednoznačná Identifikace testovacího případu
Aby bylo možné jednotlivé testovací případy vyhodnotit a případně zopakovat, musí mít každý testovací případ přidělen jednoznačný identifikátor. Nezapomínejte na to, že stejný test může být prováděn více testery. To je další důvod, proč je jednoznačná identifikace nutná.
Priorita testovacího případu
Pokud nebyla ve fázi requirements development podceněna prioritizace požadavků, stačí již jen přihlédnout k tomu, jaký dopad by měla chyba na business zákazníka a podle toho výslednou prioritu testovacího případu stanovit.
Popis testovacího případu
Doporučuji u každého testovacího případu uvádět kromě stručného popisu i odkaz na dokumentaci, kde je uveden detailní popis vlastnosti, která má být testována. Jedině tak lze zajistit, že předmětné vlastnosti budou pokryty odpovídajícími testovacími případy. Další důvod je ten, že lidé obvykle dosahují lepších výsledků, pokud rozumí tomu, co vlastně dělají.
Vstup
Vstupem je obvykle hodnota zadaná z klávesnice, vybrána myší nebo načtená ze souboru. Doporučuji věnovat zvýšenou pozornost datovému typu, jeho syntaxi, délce a hraničním hodnotám. Testujte také, jak se aplikace zachová a jaký je výsledek operace pokud zadáte číslo mimo rozsah, desetinnou čárku místo tečky a naopak, číslo se zápornou hodnotou, matematický výraz nebo textový řetězec tam, kde aplikace očekávala číslo.
Zpracování
Mezi vstupem a výstupem obvykle dochází k nějakému zpracování. U některých typů testů nás zajímá i doba zpracování, v takovém případě by měla být uvedena konkrétní hodnota, které se má dosáhnout. Pokud je v SRS dokumentu požadována okamžitá odezva, jedná se sice o nefunkční požadavek, ale špatně definovaný, protože každý z nás může mít o okamžité odezvě zcela jinou představu. Takový požadavek by měl být vrácen a upřesněn.
Výstup
Výstup je obvykle zobrazen na obrazovce nebo zapsán do souboru. Pokud máme výstup porovnávat s očekávanou hodnotou, musí být očekávaná hodnota nebo alespoň její rozsah uveden.
HW a SW konfigurace
Pokud má mít testování nějakou vypovídající hodnotu, musí být definováno na jaké HW a SW konfiguraci se mají jednotlivé testovací případy provádět. Prostředí, kde je daná aplikace hostována, je většinou dostatečně popsáno, problém však často bývá s popisem prostředí, ze kterého se testy spouští. Pokud budeme uvažovat webovou aplikaci, ke které se přistupuje prostřednictvím tenkého klienta (browseru), měli bychom popsat nejen typ a verzi OS, ale i typ prohlížeče a na jakých verzích se má testování provádět. Pokud hovořím o SW konfiguraci, mám na mysli například i to, že výsledky testování a tedy i vlastní funkčnost daného SW mohou ovlivnit i zdánlivě takové maličkosti, jako je zapnutí nebo vypnutí java skriptu, ActiveX komponenty či cachování. I tuto skutečnost je nutné vzít při návrhu testů v potaz. Největším problémem samotného testování tak může být rozhodnutí o tom, na jakých HW a SW konfiguracích by se mělo testování provádět. Ale i odpověď na tuto otázku bychom měli nalézt v SRS dokumentu. Je zřejmé, že není možné aplikaci otestovat na všech možných konfiguracích a je nutné se smířit s tím, že na některých konfiguracích daná aplikace prostě fungovat nebude. Z tohoto důvodu by vždy mělo být uvedeno, na jakých HW a SW konfiguracích bylo testování provedeno.
Předcházející test
V některých případech nemůže test začít dříve, než jiný test skončí. Tato informace nabývá na významu obzvlášť v případech, kdy se testování účastní více testerů.
A jak stanovujete prioritu testovacího případu vy?
Testovací scénář
V tomto příspěvku se dozvíte, co je to testovací scénář a jak se testovací scénáře vytváří.
Testovacímu scénáři by měl být přidělen jednoznačný identifikátor a měl by obsahovat odkaz na Plán testování (ten by zase měl jednoznačně identifikovat testovací scénáře). Testovací scénář je tvořen sadou testovacích případů. Může se jednat o testovací případy, které na sebe navazují a musí být vykonány v přesně uvedeném pořadí. Nebo na pořadí, v jakém jsou jednotlivé testovací případy prováděny, nezáleží. Testovací scénář může mít stejnou hierarchickou strukturu jako má specifikace požadavků. Cílem test designera by mělo být pokrytí všech požadavků odpovídajícími testovacími případy. Běžně se postupuje tak, že se provede návrh testovacích scénářů, následně dojde k jejich posouzení a poté k jejich případné opravě. Testovací scénář, pokud má podobu dokumentu, mívá obvykle tuto strukturu:
Vlastnosti, které budou testovány (Features to be tested) – co bude obsahem této kapitoly už asi tušíte. Všimněte si ale, že zde není kapitola Vlastnosti, které nebudou testovány (Features not to be tested). Tak je to správně, protože co se nebude testovat, jsme si již uvedli v Plánu testování a bylo by naprosto zbytečné to tady znovu opakovat.
Přístup k testování (Test approach) – způsoby testování a typy testů jsme si popsali již v samostatných článcích.
Testovací případy – v této kapitole se uvádí jednotlivé testovací případy a případně i testovací skripty, které budou pro dané testovací případy použity.
Kritéria – (Pass/Fail criteria) – zde se obvykle uvádí kritéria, na základě kterých je možno rozhodnout o tom, zda test prošel nebo ne.
Vzhledem k tomu, že některé testovací případy mohou být použity i v jiném testovacím scénáři nebo dokonce i v rámci testování úplně jiné aplikace, pravděpodobně se v praxi s dokumentem tohoto typu nesetkáte. Je to proto, že ten kdo se testováním vážně zabývá, používá obvykle nějaký SW nástroj, který mu umožňuje jednotlivé testovací případy a scénáře efektivně spravovat a využívat. Tímto způsobem je možné dosáhnout vysoké znovupoužitelnosti (reusability) testovacích případů a snížit tak náklady na testování.
Poznámka: V tomto příspěvku se úmyslně dopouštím určité nepřesnosti vůči IEEE 829. Ten totiž pojem testovací scénář vůbec nepoužívá. Místo něj hovoří o návrhu testů. Rozdíl je v tom, že zatímco design může v angličtině zastupovat jak sloveso (navrhnout) tak i podstatné jméno (návrh), tak scenario zastupuje jen podstatné jméno – scénář. Vycházím z jednoduchého předpokladu, že test designer navrhuje, jak by měl test probíhat a vytváří tak scénář nebo chcete-li test design.
Testovací skript
V tomto krátkém příspěvku se dozvíte, co je to testovací skript a co by měl dokument popisující testovací skript obsahovat.
V okamžiku, kdy se všechny nebo některé požadavky testují automatizovaně, obvykle se k tomu používá nějaký speciální SW nebo skript. Každému takovému skriptu by měl být přidělen jednoznačný identifikátor a mělo by být popsáno, k testování jakých požadavků slouží. Dále by mělo být uvedeno:
co je potřeba provést před vlastním spuštěním skriptu,
jak se daný skript spouští,
jaké se mu předávají parametry,
kam se provádí logování,
jak je možné běh skriptu přerušit a znovu ho spustit,
co se má udělat poté, co skript skončí.
U popisu skriptu by měl být též uveden odkaz na testovací scénář nebo testovací případ, který ho využívá.
Poznámka: Někdy se místo pojmu testovací skript (test script) používá pojem testovací procedura (test procedure). S tímto pojmem je možné se setkat např. v dokumentech, které jsou připraveny v souladu s IEEE 829.
Testovací log
V tomto krátkém příspěvku se dozvíte, k čemu slouží Testovací log a jaké informace by měl obsahovat.
Testovací log poskytuje informace o průběhu jednotlivých testů. Testovací log by měl mít jedinečný název, aby nedošlo k záměně s logem z jiných testů, z jiného časového období nebo od jiného testera. Testovací log by měl obsahovat tyto informace:
jednoznačný identifikátor skriptu, který byl spuštěn,
jednoznačný identifikátor osoby, která skript spustila,
jednoznačný identifikátor testovacího případu,
čas zahájení, ukončení a délky trvání jednotlivých testovacích případů,
jaká byla zadaná vstupní hodnota,
jaká byla výstupní hodnota.
Všimněte si, že nikde neuvádím, jakým způsobem testovací log vzniká, neboť testovací log může být vytvářen buď přímo testovacím skriptem nebo samotným testerem, který ručně zaznamenává provedení jednotlivých kroků podle testovacího scénáře.
Poznámka: Ideální testovací log by měl obsahovat i informace o aktuálním stavu systému, tzn. jaké bylo zatížení CPU, využití paměti a množství I/O operací v průběhu jednotlivých testovacích případů. Vzhledem k tomu, že ne každý nástroj toto umožňuje, je možné využít vlastních prostředků operačního systému a produktů třetích stran a po dobu testování tyto parametry auditovat. Po skončení testů potom můžeme vyhodnotit, jak jednotlivé testy zatěžují systém.
Protokol o předání SW l testování
V tomto krátkém příspěvku se dozvíte, k čemu slouží Protokol o předání SW k testování (test item transmittal report) a jaké náležitosti by měl obsahovat.
Důvod existence tohoto dokumentu je prostý. Vlastní testování bude nejspíš provádět někdo zcela jiný, než kdo plán testování, testovací scénáře, testovací případy a testovací skripty navrhoval. Protokol o předání SW k testování by proto měl:
mít přidělen jednoznačný identifikátor,
jednoznačně identifikovat SW, který se bude testovat,
uvádět přesné umístění SW (název serveru, IP adresa)
obsahovat odkaz na plán testování, podle kterého se má testovat.
Nedílnou součástí tohoto protokolu je datum a podpis dvou klíčových osob a to test managera – osoby odpovědné, za správný průběh testů a development managera – osoby odpovědné za přípravu prostředí (HW a SW konfiguraci) pro testování. Development manager svým podpisem stvrzuje, že prostředí pro testování bylo připraveno a test manager zase stvrzuje, že rozumí, co je předmětem testování. Možná se vám tento způsob zdá přiliš byrokratický, ale v okamžiku, kdy odpovídáte za správný průběh několika současně prováděných testů, se jedná o jedinou možnost, jak zajistit, aby se testovalo ve správném prostředí a správná verze SW.
Plán testování
V tomto příspěvku se dozvíte, co je to testovací plán, plán testování nebo chcete-li plán testů, jaká je jeho struktura a jaké informace by měl obsahovat.
Hned v úvodu bych chtěl zdůraznit, že plán testování není nic jiného, než dokument, který slouží k popsání toho, co se bude testovat a to kdy, kde, jak, kým a čím. Vzhledem k tomu, že testovacích plánů může vzniknout několik a dokonce v různých verzích, obzvlášť ve společnostech, které se vývojem a testováním SW zabývají, je nutné zajistit, aby se vždy pracovalo se správným testovacím plánem.
Každému testovacímu plánu by proto měl být přidělen jednoznačný identifikátor, který se nejčastěji sestavuje z názvu aplikace nebo modulu, který je předmětem testování a čísla vyjadřujícího verzi plánu. Jednoznačný identifikátor doporučuji uvádět nejen na hlavní stránce, ale i v záhlaví nebo zápatí každé stránky a stránky číslovat (číslo stránky / celkový počet stran). Na první stránce by měl být též uveden text „Plán testování“ a poté by mělo následovat jméno osoby resp. osob, které jsou autory tohoto dokumentu. Dokument má obvykle následující strukturu:
Úvod (Introduction/Management summary)
V této kapitole je vhodné velice stručně uvést, k čemu SW, který se bude testovat, slouží, kdo ho používá a z jakých hlavních částí se skládá. Na jaké HW a SW konfiguraci systém bude běžet a na jaké HW a SW konfiguraci se bude testování provádět. Kdo, kde, kdy a jak bude testování provádět.
Dokumentace (Test items)
Zde by měly být uvedeny dokumenty, ze kterých se bude při návrhu testů vycházet. Obvykle se jedná o specifikaci softwarových požadavků (Software Requirements Specification), uživatelskou příručku (User Guide), příručku operátora (Operator Guide) a instalační příručku (Installation Guide). Pokud píšete testy ještě dřív, než se začne programovat, budete mít k dispozici jen SRS. Doporučuji jednoznačně identifikovat SW, který se má testovat, včetně čísla verze a jeho umístění. Určitě nechcete omylem otestovat starou verzi nebo provádět testy v jiném prostředí.
Vlastnosti, které budou testovány (Features to be tested)
Zde by měly být uvedeny všechny vlastnosti, které se mají testovat. Každá vlastnost by měla být popsána a měla by mít přidělen jednoznačný identifikátor.
Vlastnosti, které nebudou testovány (Features not to be tested)
Zde by měly být uvedeny vlastnosti, které se nemají testovat a proč. I zde doporučuji uvést u jednotlivých vlastností jednoznačný identifikátor. Především proto, že jedině tak lze zjistit, zda se na některé vlastnosti uvedené v SRS nezapomnělo.
Průběh testů (Approach)
Zde by měl být uveden stručný popis toho, jak jednotlivé testy budou probíhat a jaký způsob testování bude u jednotlivých typů testů použit. V této kapitole je třeba také uvést nad jakými daty a v jakém prostředí bude testování probíhat a zda se budou data obsahující např. osobní údaje nějakým způsobem modifikovat.
Přerušení testů (Suspension criteria and resumption requirements)
Zde by měly být uvedeny podmínky, za jakých je možno testy zastavit a co je nutné udělat pro to, aby se mohlo v testování pokračovat.
Výstupy z testování (Test deliverables)
Seznam dokumentů, které by měly v rámci testování vzniknout. Minimálně by se mělo jednat o dokumenty popisující: testovací případy, testovací procedury, testovací logy a závěrečnou zprávu o testování.
Harmonogram testování (Schedule)
Vzhledem k tomu, že testování je vhodné pojmout jako projekt, který se musí naplánovat a určit kdo, kdy a co má dělat, nejedná se tedy v podstatě o nic jiného, než o vytvoření WBS. Teoreticky by se sice dalo testovat do nekonečna, ale vzhledem k tomu, že disponujeme jen omezenými zdroji, není možné otestovat všechno a stejně detailně. V praxi prostě musíme něco otestovat velice důkladně, a něco jen zběžně. Většinou podle toho, které funkčnosti jsou pro zákazníka nejdůležitější. To je ostatně důvod, proč by měl být zákazník do testování zapojen.
Požadavky na zdroje (Environmental needs)
V této kapitole by měly být uvedeny veškeré požadavky na zdroje tzn. na HW a SW vybavení, nároky na prostory a jejich vybavení, přístupy do těchto prostor, přístupy do daného systému a aplikace, dodání dokumentace, testovacích dat.
Odpvědnosti (Responsibilities)
Stejně jako v jakémkoliv jiném projektu i při testování lze Identifikovat různé skupiny nebo jednotlivce, kteří mají odpovědnost za splnění jednotlivých úkolů. Typicky se jedná o osoby odpovědné za řízení celých testů, přípravu podmínek pro testování, vlastní testery, správce systému, vývojáře a v neposlední řadě i vlastníka dat. Odpovědnosti jednotlivých osob a skupin je vhodné uvést právě zde.
Personální zajištění (Staffing and training needs)
Počet členů jednotlivých skupin a požadavky na proškolení a znalosti testerů jsou obsahem této kapitoly. Je zřejmé, že čím vyšší požadavky na znalosti testerů jsou kladeny, tím méně detailní potom musí být popis testovacích případů. A naopak, čím kvalitnější popis testovacích případů máme, tím nižší jsou nároky na znalosti testerů.
Rizika (Risks and contingencies)
Zde bychom měli popsat, jaká jsou rizika. Např. že nebude včas dodána verze SW, který se má testovat, nebude připraveno pracoviště pro testery apod.
Souhlas s testováním (Approvals)
Na poslední straně dokumentu se obvykle uvádí datum a jména osob, které svým podpisem odsouhlasí daný testovací plán.
Poznámka: Názvy jednotlivých kapitol uvádím jak v češtině, tak i v angličtině. Ne vždy se jedná o doslovný překlad, srovnejte např. s IEEE 829 Standard for software and system test documentation.
Vývojové-testovací-produkční prostředí a rizika
Tento článek přináší odpověď na otázku, jak zajistit bezpečnost dat ve vývojovém, testovacím a produkčním prostředí a úspěšně zvládat rizika, která jsou s provozem těchto prostředí spojena.
Je třeba si uvědomit, že každý SW prochází zpravidla během svého vývoje několika různými prostředími. Běžně se jedná o vývojové, testovací a produkční prostředí. Vzhledem k tomu, že testovací prostředí se může ve velkých společnostech dále dělit na integrační a akceptační, jsme postaveni před poměrně nelehký úkol: zajistit zachování důvěrnosti, integrity a dostupnosti informačních aktiv během celého životního cyklu vývoje softwaru a to ve všech těchto čtyřech prostředích. Podívejme se nyní společně na největší rizika, kterým musíme čelit.
Riziko: narušení důvěrnosti
Hrozba: Únik důvěrných dat z vývojového a testovacího prostředí. Je zajímavé, že zatímco data v produkčním prostředí bývají velice často chráněna a společnosti vydávají nemalé prostředky na jejich ochranu, tak ve vývojovém a testovacím prostředí tomu tak není. Podle průzkumu, který provedla společnosti Compuware a organizace Ponemon Institute, používá většina společností při vývoji a testování aplikací skutečná data.
Opatření: Ve vývojovém a testovacím prostředím nepracovat s reálnými daty. Pokud je to možné, mělo by se provést jejich zneplatnění, např. formou kódování, scrambling, apod. V opačném případě musí být před přenesením skutečných dat do vývojového nebo testovacího prostředí zajištěn souhlas vlastníka. Vlastník by měl být s rizikem úniku důvěrných dat prokazatelně seznámen, toto riziko akceptovat a s testováním nad reálnými daty souhlasit. Podepisování nejrůznějších NDA je sice možné, ale v praxi vás to stejně před únikem důvěrných dat neochrání.
Riziko: narušení integrity
Hrozba: Neupravený konfigurační soubor může způsobit, že server z vývojového nebo testovacího prostředí bude komunikovat přímo se serverem z produkčního prostředí. Může se tak snadno stát, že např. požadavek na smazání vybraných záznamů se místo na DB serveru v testovacím prostředí provede na DB serveru v produkčním prostředí. Pokud se na tuto skutečnost nepřijde včas, může to mít pro společnost zcela katastrofální následky.
Opatření: Jako vhodné řešení se jeví oddělit od sebe vývojové, testovací a produkční prostředí a to tak, aby servery z jednoho prostředí nemohly komunikovat se servery z druhého prostředí.
Hrozba: Osoba s přístupem do produkčního i testovacího prostředí může provést úmyslný nebo úmyslný a z pohledu společnosti nežádoucí zásah do SW vybavení a dat
Opatření: Vývojářský tým by měl mít přístup pouze do vývojového a integračního prostředí, neboť nemá dělat nic jiného než unitní a integrační testy. Testovací tým by měl mít přístup zase jen do akceptačního prostředí.
Hrozba: Osoba s přístupem do více prostředí si může splést prostředí v jakém pracuje a provést nežádoucí změnu v SW vybavení a datech.
Opatření: Pokud chce společnost toto riziko co nejvíce eliminovat, je asi nejlepším řešením zablokovat uživateli po dobu testování přístup do konkrétní aplikace v produkčním prostředí a po skončení testů mu ho zase odblokovat. Vzhledem k tomu, že se každé testování velice pečlivě plánuje (předpokládám, že váš Plán testování obsahuje všechny náležitosti), tak kdo a kdy bude testovat je v dostatečném časovém předstihu známo a tak by pro vás neměl být problém účet testera do aplikace v produkčním prostředí zablokovat. Je na test managerovi, aby si ověřil a zajistil, že přístupy testerů do aplikace v testovacím prostředí jim budou aktivovány až poté, co jim bude zablokován přístup do aplikace v produkčním prostředí. Výhodou tohoto řešení je, že pracovník se nemusí nikam stěhovat a může testování provádět ze svého pracoviště. Tímto způsobem lze výrazně ušetřit, neboť není nutné budovat speciální pracoviště a vybavovat ho dalšími počítači, které by byly navíc mimo testování nevyužity.
Opatření: Přístup do testovacího prostředí umožnit jen z počítačů, které budou umístěny v chráněných a oddělených prostorách společnosti. Na takové pracoviště se bude muset pracovník před započetím testu dostavit. V praxi se bohužel ukazuje, že ani přesun pracovníka na jiný počítač není dostatečnou zárukou. Je možné si to vysvětlit tím, že většina kancelářských prostor vypadá úplně stejně, takže za chvíli pracovník už ani neví, kde že to vlastně sedí.
Opatření: Jednotlivá prostředí od sebe odlišit např. odlišnou barvou okna, změnou promptu, titulku okna, jiným pozadím pracovní plochy apod.. Bohužel, stejně jako v předchozím případě i zde se ukazuje, že toto opatření v praxi selhává, protože v okamžiku, kdy mají testeři současný přístup do více prostředí a mezi jednotlivými prostředími se přepínají, vždy se najde někdo, kdo se splete. Toto opatření lze nasadit snad jen jako doplněk k předchozím opatřením, samo o sobě riziko moc nesnižuje.
Riziko: narušení dostupnosti
Hrozba: Nežádoucí síťová komunikace iniciována servery z vývojového nebo testovacího prostředí může vést až k zahlcení produkčních serverů a síťové infrastruktury.
Opatření: Jako vhodné řešení se jeví oddělit od sebe vývojové, testovací a produkční prostředí. To lze provést např. za použití firewallů a nastavení příslušných pravidel spočívající v povolení komunikaci pouze pro konkrétní IP adresu, protokol a port.
Závěr: Je zajímavé, že ač společností investují nemalé prostředky do vybudování jednotlivých prostředí, tak jejich zabezpečení spočívající v implementaci vhodných opatření věnují minimální nebo vůbec žádnou pozornost. A jak výše uvedená rizika zvládáte vy ve vaší společnosti?
Testování SW
V tomto příspěvku se dozvíte, proč testovat SW, co je cílem testování SW, jaká je závislost mezi kvalitou SW, testováním SW a počtem chyb a kdy začít s testováním SW.
Proč testovat? Vývoj SW se stále zrychluje, požadavky na kvalitu jsou minimálně stejné, ne-li vyšší než tomu bylo před lety. Testování SW tak nabývá stále na větším významu, protože čím dříve se chyby odhalí, tím nižší jsou náklady na jejich odstranění. Testování SW se stává nedílnou součástí životního cyklu vývoje software (SDLC – Software Development Life Cycle).
Co je cílem testování? Cílem testování obvykle bývá ověřit, že SW dělá přesně to, co je uvedeno ve specifikaci a dále jak je schopen se vyrovnat s nestandardními stavy, jak reaguje na chybu uživatele nebo chybu v datech, selhání jiné SW nebo HW komponenty, jak se vypořádá se zátěží a nedostatkem systémových zdrojů, zda se dokáže zotavit po havárii, zda je odolný vůči útokům, jak funguje na různých HW a SW konfiguracích, atd.
Je třeba mít neustále na paměti, že to, že se během testování neobjevila žádná chyba a všechny testy byly úspěšné, neznamená, že SW žádné chyby neobsahuje. S velkou pravděpodobností nějaké obsahuje, ale jen se na ně nepřišlo. To je dáno tím, že SW stejně jako testy dělají lidé a lidé jak známo chybují. Odhalené množství chyb je tak značně závislé na kvalitě vývoje a kvalitě testování. V praxi tak může dojít k tomu, že:
kvalita SW i testů je vysoká, lze předpokládat, že bude odhaleno jen malé množství chyb, ale pár jich produkt přesto může obsahovat;
kvalita SW je vysoká, naproti tomu kvalita testů je nízká, lze předpokládat, že bude odhaleno méně chyb než v předchozím případě;
kvalita SW i testů je nízká, lze předpokládat, že bude odhaleno jen malé množství chyb, přestože produkt jich bude obsahovat velké množství;
kvalita SW je nízká, naproti tomu kvalita testů je vysoká, lze předpokládat, že bude odhaleno velké množství chyb.
To, že je SW nebo testování kvalitní, je často založeno jen na naší víře a přesvědčení. Můžeme se tak mylně domnívat, že nízký počet odhalených chyb je dán vysokou kvalitou SW a testování. Opak však může být pravdou, SW obsahuje plno chyb, ale z důvodu nízké kvality testování jich bylo odhaleno jen pár.
Kdy začít psát testy? Psát testy můžeme začít ještě dřív, než začneme programovat a to v okamžiku, kdy máme k dispozici SRS (Software Requirements Specification) dokument. Testy tak můžeme založit na požadavcích uvedených SRS. Vycházíme z jednoduchého předpokladu, že když se vyvíjí nějaký SW, vždy existuje nějaká specifikace toho, co by měl SW dělat. K dispozici tak většinou máme již na samém počátku vývoje seznam funkčních a nefunkčních požadavků. Na jejich základě můžeme vytvořit testovací případy a scénáře pro manuální i automatizované testy. Ostatní často uváděné dokumenty pro psaní testů jako je instalační příručka (Installation guide), příručka operátora (operator guide) a uživatelská příručka (user guide), vznikají až během vývoje nebo v jeho poslední závěrečné fázi, ale to už můžeme mít většinu testů připravených a naplánovaných.
V článku nazvaném Způsoby testování jsme si testy rozdělili podle přístupu k informacím nutným k provedení testů na white box, black box a grey box. V článku Typy testů jsme si testy rozdělili pro změnu podle V-modelu. Testy však můžeme rozdělit i podle subjektu, který je provádí. V takovém případě můžeme testy rozdělit na testy prováděné:
dodavatelem, který obvykle provádí testy unitní, integrační a systémové a
odběratelem, který obvykle provádí testy akceptační.
Další dělení může být podle způsobu provedení, můžeme tedy mít testy:
automatizované – jejich výhodou je, že jsou rychlé, lze otestovat větší množství vstupních dat, lze je snadno a s minimálními náklady zopakovat, výsledky testu se zapisují do logu, některé testy se v podstatě ani jinak než automatizovaně dělat nedají (např. zátěžové testy). Jejich nevýhodu je, že je nutné je naprogramovat a to něco stojí.
manuální testy – jejich nevýhodou je, že jsou pomalé, nelze jimi otestovat velké množství vstupních dat, každé opakování je prodražuje, vše je třeba ručně zapisovat. Na druhou stranu se nemusí nic programovat, a některé testy ani jinak než manuálně provést nelze (např. test použitelnosti).
Aby naše dělení bylo úplné, nesmíme zapomenout na:
statické testování – prohlíží se zdrojový kód SW a hledají se v něm chyby,
dynamické testování – chyby se hledají za běhu SW.
K testování SW je vhodné přistoupit jako k jakémukoliv jinému projektu. Celý projekt lze rozdělit do 4 hlavních částí:
Příprava na testování – v této fázi vznikají obvykle tyto dokumenty: testovací plán, testovací scénáře a testovací případy.
Provedení testů – v souladu s testovacím plánem pak probíhají vlastní testy podle testovacích scénářů.
Vyhodnocení testů – pokud by se vyhodnocování neprovádělo, tak by testování ani nemělo smysl.
Rozhodnutí o dalším postupu – zopakování některých testů apod.
V rámci testování SW lze identifikovat tyto role:
Test designer – zodpovědný za přípravu testů, vytváří testovací scénáře, logické a fyzické testovací případy a rozhoduje o tom, jaká budou testovací data.
Test manager – zodpovědný za plánování, organizovaní, koordinování a reportování stavu testování.
Test executor – zodpovědný za vlastní provedení testů, dokumentuje výsledky testů, kontroluje logy a hlásí defekty.
Defect solver – nejčastěji to bývá vývojář, kdo řeší defekty.
Dále je nutné definovat závazná pravidla pro tvorbu názvů dokumentů, které by měly v průběhu testování vzniknout. V některém z příštích článků si povíme, co je to plán testování, testovací scénář, testovací případ, testovací skript, protokol o předání SW k testování, testovací log, test incident report a test status report.
Usability test
Usability test, nebo chcete-li testování použitelnosti, patří do kategorie testů typu black box. Bohužel jen málokdo jej umí zrealizovat.
Stále se najde dost firem a manažerů, kteří jsou přesvědčeni, že provádět usability testy je naprostá ztráta času a vyhozené peníze, protože nikoliv uživatel, ale oni a jejich vývojový tým nejlépe ví, jak má uživatelské rozhraní vypadat.
V tomto příspěvku nebudu psát o tom, že i usability test musíte naplánovat, připravit, provést a vyhodnotit, to už byste měli vědět. Zaměřím se spíš na to, co je pro usability test charakteristické. Usability test obecně by se měl zaměřit především na to, jak snadné je produkt zprovoznit a používat. Je zřejmé, že když budete testovat webovou aplikaci, tak nemůže být o nějaké instalaci nebo konfiguraci řeč. Nezapomínejte ale, že produktem může být jakýkoliv HW a SW, a tam pak má smysl testovat i to, zda uživatel dokáže daný produkt vůbec zprovoznit. To znamená nainstalovat, zkonfigurovat a případně ho i aktualizovat, pokud produkt tuto možnost nabízí. Dost často se v případě hodnocení použitelnosti uvádí následující kritéria:
snadnost – jak rychle se uživatel naučí daný produkt používat;
efektivita – jak rychle dokáže s daným produktem poté, co se ho naučil používat, splnit zadané úkoly;
přesnost – kolik chyb uživatel udělá, jak jsou závažné, a zda má možnost je napravit
zapamatovatelnost – jak rychle si dokáže způsob ovládání vybavit, když produkt dlouho nepoužíval;
spokojenost – zda uživatel s produktem spokojen, líbí se mu a bude ho rád používat.
Všechna výše uvedená kritéria mají svůj význam, a kromě posledního se dají i snadno změřit. Bohužel, zrovna to poslední kritérium je to, co nás obvykle nejvíce zajímá.
Co chcete zjistit?
Hned na úvod byste si měli stanovit, co od nové verze produktu očekáváte? Má vám pomoci udržet stávající zákazníky? Přetáhnout zákazníky konkurence? Získat úplně nové zákazníky? Jak se bude nová verze produktu líbit stávajícím klientům, anebo jak se s ní bude pracovat klientovi, který ji uvidí poprvé v životě, a který používá konkurenční produkt, ba dokonce který žádný podobný produkt doposud nepoužívá? Vidíte, hned zde máme tři kategorie uživatelů a od uživatele každé kategorie můžete očekávat naprosto rozdílné reakce.
Výběr vhodných respondentů
Vybrat vhodné testery je pro správné provedení usability testů naprosto klíčové. Je třeba si uvědomit, že osoby různého věku, pohlaví a vzdělání budou disponovat rozdílnými zkušenostmi a k řešení zadané úlohy budou přistupovat jinak. Vzhledem k tomu, že provedení usability testů je poměrně finančně a časově náročné, je vhodné vyzvat k testování typické zástupce daných skupin uživatelů.
Výběr vhodného prostředí
V materiálech, které se věnují usability testům se obvykle dočtete, že byste měli testerům vytvořit příjemné prostředí, aby se cítili během testování dobře. Toto doporučení je zavádějící. Měli byste usilovat o vytvoření takového prostředí, v jakém se bude váš produkt opravdu používat. To znamená, že pokud se předpokládá využití vašeho produktu např. v rušném prostředí nebo v přírodě, je nesmysl provádět testování v místnosti.
Sestavení úlohy
Hlavní pravidlo zní, že úloha by neměla testera v žádném případě navádět k řešení. Na řešení by měl přijít sám. Zde nevytváříme detailní testovací případy a scénáře, jako tomu je u ostatních testů, kde je to naopak nutnost. Pokud testujeme např. e-shop, tak úloha může znít velice jednoduše. Např.: „Představte s, že jedete se svou 4členou rodinou na dovolenou k vodě a chcete si koupit nafukovací člun, do kterého byste se všichni vešli. Použijte k tomu e-shop, který se nachází na adrese…“ A to je vše přátelé, nic víc není třeba uvádět.
Průběh testování
Vlastní usability test spočívá v tom, že sledujeme testera, jak požadovanou úlohu řeší. Zaznamenáváme nejen to, na co uživatel v aplikaci kliká a jak rychle se dostává k cíli, ale především jeho chování a emoce. Za tímto účelem se používají kamery s mikrofony a jednosměrné zrcadlo, aby bylo možné celé uživatelovo sezení nahrát a zpětně vyhodnotit. Tester též může být vyzván, aby přemýšlel nahlas, komentoval, co dělá, co se mu líbí a co se mu naopak nelíbí, že byl překvapen, že se stalo něco úplně jiného, než očekával, že aplikace je nepřehledná, že hledá jak změnit adresu příjemce a nemůže to najít, že se mu nelíbí design, co by udělal jinak apod. Netřeba snad dodávat, že v takovém případě by již neměl být testování přítomen další tester, aby se vzájemně neovlivňovali.
Poznámka: Je nesmysl používat k usability testům vlastní zaměstnance. Jsou sice možná zainteresování na zisku, takže by mělo být v jejich zájmu, aby produkt byl co nejlepší, ale mnozí z nich se také na vývoji produktu podíleli, velice dobře ho znají, mají k němu osobní vztah a vědí naprosto přesně, jak nejrychleji danou úlohu vyřešit. Od nich nemůžete očekávat upřímnou zpětnou vazbu.
Závěr: Dost často se uvádí, že usability testy jsou finančně velice náročné, a že není možné do usability testů zapojit větší počet testerů. Je to možné, a nemusí to být ani moc drahé. Musíte však počítat s tím, že nikdo nic zadarmo testovat nebude. Testovat lze i přes internet, můžete oslovit testery, které mají web kameru s mikrofonem a požádat je, aby ji během testu aktivovali, a pak už je celkem jedno, zda tester sedí u sebe doma nebo na vašem pracovišti. Množství testerů je pak čistě dáno vaší schopností analyzovat došlé nahrávky a logy ze serveru a výší finančních prostředků, které jste na toto testování ochotni vyčlenit.
Black box test
Black box testování, známé také jako opaque box, closed box, behavioral nebo funkční je realizováno bez znalosti vnitřní datové a programové struktury.
To znamená, že tester nemá k dispozici žádnou dokumentaci, binární ani zdrojové kódy. Tento způsob testování vyžaduje testovací scénáře, které jsou buď poskytnuty testerovi nebo si je tester u některých typů testů sám vytváří. Vzhledem k tomu, že jsou obvykle definovány typy a rozsahy hodnot přípustných a nepřípustných pro danou aplikaci a tester ví, jaký zadal vstup, tak ví i jaký výstup nebo chování může od aplikace očekávat. Black box testy mohou stejně jako white box testy probíhat ručně nebo automatizovaně za použití nejrůznějších nástrojů. I v tomto případě se s oblibou využívá obou přístupů. Black box se jeví jako ideální tam, kde jsou přesně definované vstupy a rozsahy možných hodnot.

Využití
Black box testu lze využít např. na zjištění problémů typu odepření služby (DoS) nebo aktuálních zranitelností již běžícího systému nebo aplikace. V případě použití tohoto způsobu testování je třeba vždy počítat s určitým rizikem pádu daného systému. Black box testem je také možné demonstrovat chybu, která byla objevena během white box testu. K provedení testů stačí mít k dispozici jen daný program nebo znát jeho umístění, v takovém případě může být proveden test i vzdáleně po síti.
Výhody
Snadnost – test může být proveden bez znalosti programovacích jazyků, operačních systémů.
Rychlost – lze rychle v krátkém období otestovat i rozsáhlé systémy.
Transparentnost – test je pro zákazníka srozumitelný – chápe, co se bude a jak testovat, může a často to bývá i on, kdo testovací scénáře vytváří a testování pak sám provádí.
Testovací scénáře mohou být napsány v okamžiku, kdy je kompletní specifikace (některé prameny uvádí, že je možné je psát už v průběhu vzniku specifikace.)
Testování není založeno na aktuální implementaci. I když se změní programovací jazyk, operační systém a HW, testování bude probíhat pořád stejně. Testovací scénář není nutno měnit.
Testerovi není nutné zpřístupňovat zdrojový kód.
Nevýhody
Nižší kvalita kódu – to, že se na výstupu objeví očekávaná hodnota, neznamená, že aplikace je správně napsaná. Kód může být značně neefektivní.
Nežádoucí chování aplikace – kromě požadované funkcionality může produkt provádět i jiné akce, které nejsou ve specifikaci a jejichž výstup se na standardním výstupu neobjeví a test je proto neodhalí.
Grey box test
Grey box testování, známé též jako translucent box předpokládá omezenou znalost interních datových a programových struktur za účelem navrhnutí vhodných testovacích scénářů, které se realizují na úrovni black box.
Způsob testování je tak kombinací black box a white box testování. Nejedná se o black box, protože tester zná některé vnitřní struktury, ale zároveň se nejedná ani o white box, protože znalosti vnitřních struktur nejdou do hloubky. Koncept grey box testování je velice jednoduchý. Jestliže tester ví, jak produkt funguje uvnitř, potom ho může lépe otestovat zvenku. Gray box test, stejně jako black box test je tedy prováděn zvenku, ale tester je lépe informován, jak jednotlivé komponenty fungují a spolupracují.
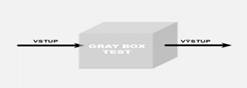
Využití
Typickým příkladem je, že white box test je použit k nalezení zranitelností a black box test je následně použit ke zjištění, zda je tyto zranitelnosti možné použít k úspěšnému provedení útoku. Se znalostí vnitřních struktur může tester lépe sestavit testovací scénáře, určit hranice hodnot atd. Grey box testu se obzvlášť používá, když se provádí integrační testování dvou modulů od dvou různých dodavatelů a je potřeba otestovat interfacy. Další velice častý případ užití je v případě testování vícevrstvé aplikace, kdy máme kontrolu nad vstupem, výstupem a máme přímý přístup do databáze. Můžeme tak porovnávat všechny tři hodnoty: vstup, hodnotu v databázi a výstup. Tímto způsobem můžeme zjistit, kde dochází k manipulaci s výsledkem, zda na straně klienta, aplikace nebo při zápisu či čtení z databáze nebo přímo v databázi například triggerem, který spustí nějakou uloženou proceduru. Dále můžeme prohlížet vytvořený HTML formulář, analyzovat skripty a práci s cookie. Stejně tak je možné použít tohoto přístupu k penetračnímu testování webové aplikace. Grey box testů se také s oblibou používá v okamžiku, kdy nechceme poskytnout zdrojové ani binární kódy, a zároveň nechceme, aby tester ztrácel čas skenováním sítě a inventarizací. V takovém případě mu informace o topologii sítě a architektuře aplikace poskytneme.
Výhody
Slučuje v sobě výhody black box i white box přístupu.
Neintrusivní – přístup ke zdrojovému ani binárnímu kódu není třeba. Je založeno na znalosti funkční specifikace, rozhraní a architektuře aplikace.
Inteligentní testy – tester je schopen díky znalostem, byť omezeným, napsat inteligentní testovací scénáře zaměřené i na manipulaci s daty a použité komunikační protokoly.
Nevýhody
Neúplné otestování – to je dáno tím, že binární ani zdrojové kódy nejsou k dispozici a není tak možné otestovat všechny datové toky. Míra pokrytí těchto toků závisí hodně na schopnostech, znalostech a zkušenostech testera.
Kvalita kódu – stejně jako u black box testu, to že něco funguje podle specifikace a je to odolné proti známým zranitelnostem, neznamená, že kód je efektivní a že aplikace neobsahuje žádný nežádoucí kód.
White box test
White box testování, známé též jako glass box, clear box, open box nebo také strukturální, předpokládá znalosti vnitřní struktury.
Přesněji řečeno vyžaduje znalost vnitřních datových a programových struktur a také toho, jak je systém naimplementován. Testerovi jsou v případě white box testování poskytnuty veškeré informace, to znamená, že má k dispozici nejen příslušnou dokumentaci, ale i binární a zdrojový kód testované aplikace. Tester musí zdrojovému kódu porozumět a analyzovat ho. Někdy se tomuto způsobu testování říká také audit zdrojového kódu. Zahraniční literatura má pro tuto činnost označení ‘code-review‘ exercise. White box testování může probíhat zcela automatizovaně nebo ručně. V praxi se však velice často oba tyto způsoby vhodně kombinují. Existují v zásadě dva typy analytických nástrojů, ty které požadují zdrojový kód a ty, které jsou schopny v případě, že zdrojový kód není k dispozici, provést automatickou dekompilaci binárního kódu a zdrojový kód si de-facto vyrobit a ten poté řádek po řádku analyzovat.
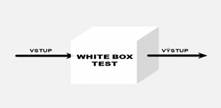
Využití
White box testování je velice vhodné např. pro webové služby a to obzvlášť na počátku vývojového cyklu, kdy vývojář a tester mohou spolupracovat na odhalování chyb. White box test můžeme využít ke zjištění, jak se systém chrání před neautorizovaným přístupem, jak je řízen přístup k jednotlivým částem aplikace a k datům, jak je implementována integritní ochrana nebo jak jsou ukládána hesla. White box test můžeme také použít k nalezení nežádoucího kódu, bezpečnostních chyb a zranitelností.
Nalezení nežádoucího kódu považuji vůbec za největší přínos white box testování. V podstatě v jakékoliv aplikaci může být přítomen nežádoucí kód a aplikace přitom může pracovat zcela správně a v souladu se specifikací. Jde o to, že naprostá většina testů je zaměřena na to, aby se ověřilo, že aplikace funguje správně, resp. že dělá to co má, nebo ještě lépe, že jsou splněny všechny funkční a nefunkční požadavky uvedené ve specifikaci. A v tom je kámen úrazu. Málokdo totiž testuje, zda aplikace náhodou nedělá ještě něco navíc.
Takový nežádoucí kód může provádět v podstatě cokoliv a záleží čistě na fantazii vývojáře, co to bude a kdy se takový kód spustí. Zda bude kód provádět nějakou činnost soustavně nebo bude skrytě čekat na výskyt nějaké konkrétní události. Takovou událostí může být třeba zaslání předem definovaného typu zprávy, stisknutí určité kombinace kláves, zadání určitého jména a hesla, které je uloženo přímo v autentizačním modulu.
Výsledkem činnosti takového kódu pak může např. být získání neoprávněného přístupu do aplikace, převod finančních prostředků na jiný účet, ukládání informacích o klientech společnosti a jejich transakcích do úložiště do kterého má útočník přístup nebo zasílání vybraných informací do e-mailové schránky útočníka, pro tento účel zřízené.
V rámci objektivity je nutné podotknout, že nežádoucí kód nemusel být do aplikace začleněn jen úmyslně, ale mohl zde zůstat i proto, že vývojář si třeba nechal v rámci ladění aplikace někam zapisovat výstup a pak na to zapomněl a kód neodstranil. Čím později se na to přijde, tím větší může být problém dokázat, zda byl nežádoucí kód do aplikace začleněn úmyslně nebo jeho výskyt v aplikaci pramení z nedbalosti. Ať už je ale příčina existence nežádoucího kódu v aplikaci jakákoliv, určitě se shodneme na tom, že je nutné takovýto nežádoucí kód včas odhalit a odstranit.
Při black box nebo grey box testování by k odhalení nežádoucího kódu mohlo dojít spíš náhodou. Např. tak, že by nežádoucí kód svou činností zabíral příliš mnoho místa na disku nebo v paměti, spotřebovával větší šířku pásma, než se předpokládalo, způsoboval nárůst počtu I/O operací, zatěžoval procesor atd. Na to, že se kód nějak prozradí sám, však nelze spoléhat.
Výhody
Včasné odhalování chyb – analýza zdrojového kódu umožní odhalit chyby, kterých se programátor dopustil ještě dřív, než je kód zkompilován.
Odhalení nežádoucího kódu – je třeba si uvědomit, že program může kromě požadovaných operací provádět i některé další nežádoucí operace, které mohou zůstat během jiných testů zcela nepovšimnuty.
Nevýhody
Náročnost – vyžaduje výbornou znalost cílového systému, testovacích nástrojů a programovacích jazyků.
Vysoké náklady – požaduje specializované nástroje jako jsou analyzátory zdrojového kódu, debuggery atd.
Typy testů
Cílem tohoto článku je stručně charakterizovat základní typy testů během životního cyklu vývoje SW.
Způsoby testování byly popsány již v samostatných článcích white box test, black box test a grey box test. Vzhledem k tomu, že vývoj SW zpravidla probíhá v několika fázích, je zřejmé, že v jednotlivých fázích budeme provádět rozdílné typy testů. Jednotlivé testy můžeme rozdělit např. podle V-modelu asi takto:
1.) Unitní testy
Každý vývojář by si měl svou práci vždy sám otestovat. V rámci testování by se měl zaměřit i na to, jestli používá vhodné algoritmy, návrhové vzory, datové typy atd.
2.) Integrační testy
Cílem těchto testů je zjistit, zda spolu jednotlivé moduly spolupracují tak, jak mají.
Regression test
Ověření, zda se v důsledku změny neobjevila chyba tam, kde to předtím již bylo v pořádku.
Incremental Integration Test
Provádí se v okamžiku, kdy je ke stávajícím již otestovaným modulům přidán další.
Smoke test
Test, zda je systém připraven na hloubkový systémový test, aniž by spadnul. To je důležité, protože kdybychom tento test přeskočili, mohlo by se stát, že by v hloubkovém systémovém testu došlo k pádu a v testování by se nemohlo pokračovat.
3.) Systémové testy
Cílem těchto testů je ověřit, že produkt splňuje všechny požadavky.
Recovery test
Účelem je otestovat, jak rychle a zda vůbec se produkt vzpamatuje po pádu systému, HW chybě, výpadku proudu atd. Tento požadavek by měl být uveden v SRS dokumentu v sekci nefunkčních požadavků.
Security test
Odhalují, jak a zda vůbec se systém chrání před neautorizovaným přístupem, jak jsou ukládána hesla, jak je řízen přístup, jak je implementována integritní ochrana. Slouží k nalezení nežádoucího kódu, bezpečnostních chyb, zranitelností.
Stress test
Cílem je ověřit, zda při velké zátěži, která může být vygenerována automaticky např. provedením velkého počtu složitých dotazů, a nedostatku zdrojů, nedojde k chybě, která by se za normálního provozu neobjevila.
Performance test
Při tomto testu systém odolává velkému počtu různých požadavků a sleduje se, jaká je jeho odezva, resp. jak je ovlivněn výkon aplikace, např. jak rychle je aplikace schopna na jednotlivé typy požadavků odpovídat. Tím lze vysledovat, které části systému je třeba věnovat větší pozornost a provést v ní příslušné optimalizace (Může to být refaktorizace kódu, ale stejně tak i prosté vytvoření indexů nad tabulkou databáze.)
Installation test
Testuje se, jak probíhá instalace a odinstalce produktu na dané platformě.
4.) Akceptační testy
Alpha test
Tyto testy ve vývojovém prostředí provádí někdo jiný než vývojový tým, ten to jen sleduje a poskytuje podporu.
Beta test
Tyto testy probíhají v prostředí zákazníka a chyby jsou reportovány vývojářům dohodnutou cestou pomocí připravených formulářů.
Acceptance test
Provádí zákazník ve svém testovacím prostředí a ověřuje, zda produkt je v souladu s požadavky ve specifikaci a zda se v jeho prostředí chová tak, jak má.
Long Term Test
Tyto testy slouží k odhalení chyb, které se zpravidla vyskytnou až po delší době používání aplikace.
Poznámka: Uvedené rozdělení není jediné možné a ani se nesnaží být vyčerpávající.
Test status report
Co je to test status report? Jednoduše řečeno, jedná se o zprávu o výsledcích testování, kterou zpravidla Test manager předkládá vlastníkovi.
Stejně jako všechny ostatní dokumenty, které v rámci testování vzniknou, i tento dokument by měl obsahovat jednoznačný identifikátor. Vzhledem k tomu, že ne vždy se povede plán testování dodržet, mělo by se ve výsledné zprávě objevit, co přesně se testovalo a kdo, kdy, kde a jak testování prováděl. Jedině tak je možné splnit podmínku opakovatelnosti a měřitelnosti.
Podmínka opakovatelnosti a měřitelnosti testů znamená, že jestliže bude test nad stejnými daty proveden znovu a podle stejných testovacích scénářů a za použití stejných testovacích skriptů, měli bychom dosáhnout velice podobných výsledků. Záměrně nepíši stejných, protože k jisté odchylce u určitých typů testů může dojít a nelze tuto skutečnost považovat za chybu. V test status reportu by měl být uveden odkaz na:
Pokud testovaný SW vykazoval nějaké odlišnosti od specifikace, mělo by se to v reportu objevit. V reportu by měly být též uvedeny odchylky od testovacího plánu, scénářů a skriptů. Stejně tak, pokud nějaké vlastnosti nebyly testovány, měl by být uveden důvod. Co je vůbec nejdůležitější a co každého zajímá asi ze všeho nejvíc, je počet a typ:
odhalených defektů,
opravených defektů a
neopravených defektů.
Po seznámení se s výsledky testování je na vlastníkovi, aby rozhodl o dalším postupu, např. zda je možné aplikaci nasadit do produkčního prostředí nebo ne. Ostatně toto rozhodnutí by měl vždy učinit vlastník, neboť on nese odpovědnost.
Defect management
V tomto příspěvku se dozvíte, co je to defect management, jaký je životní cyklus defektu. Co je to test incident report a jaké informace by měl obsahovat.
Vzhledem k tomu, že ne vždy test projde, je potřeba mít definován závazný postup, jak tento stav řešit. Vznešeně se této činnosti říká defekt management (defect management). V podstatě jde o to určit, kdo, komu a jakým způsobem by měl defekty hlásit a jak by s nimi mělo být dále nakládáno. Pokud se nepoužívá na správu defektů žádný pokročilý SW nástroj, vytváří se tzv. test incident report, ve kterém by mělo být uvedeno:
kdo test prováděl,
jaký skript byl spuštěn,
o jaký se jednalo testovací případ,
jaký byl vstup,
jaký byl očekávaný výstup a
jaký byl skutečný výstup,
na jaké HW a SW konfiguraci k chybě došlo a
kdy se tak stalo.
Životní cyklus defektu je možno jednoduše popsat takto:
Detekce – test neprošel, skutečný výsledek se liší od předpokládaného výsledku, říkáme, že tester právě objevil defekt.
Evidence – tester, který defekt objevil, ho dohodnutým způsobem nahlásí. Nejčastěji ho zapíše do nějaké aplikace a uvede všechny náležitosti, které jsme si uvedli výše.
Analýza – defekt koordinátor analyzuje nahlášený defekt a ověří, zda se opravdu jedná o defekt a zda již nebyl nahlášen jiným testerem a není již v systému evidován.
Prioritizace – vlastník by měl každému defektu přidělit priority kód, který by měl vyjadřovat jeho naléhavost.
Přiřazení – defekt koordinátor rozhodne, které vývojářské skupině nebo vývojáři daný defekt přiřadí k vyřešení.
Potvrzení – vývojářský tým potvrdí nebo odmítne přijetí defektu k řešení. V případě, že odmítne, musí se najít správný řešitel.
Opravení – vývojář analyzuje defekt, navrhne řešení, provede příslušnou úpravu v kódu, otestuje a předá SW k opětovnému testování.
Ověření – testovací tým zopakuje příslušné testy a o ověří, zda se v nově dodané verzi SW defekt již neobjevuje.
Uzavření – poté, co se testováním prokáže, že defekt byl opravdu odstraněn, je možné ho označit jako uzavřený.
Poznámka: Všimněte si prosím, že testeři chybu obvykle označují jako defekt nebo incident a vývojáři zase jako bug. Kromě toho se chyba dost často označuje také jako anomaly, error, failure, fault, problem nebo variance.
A jak říkáte chybám, na které narazíte během testování SW vy a v čem je evidujete?
Load test
Cílem tohoto testu je zjistit, jak se systém bude chovat v reálném provozu, kdy k němu bude současně přistupovat velké množství uživatelů.
Ze zkušenosti mohu říci, že na některé chyby se dá přijít až v okamžiku, kdy je k danému systému přihlášeno velké množství uživatelů, kteří současně využívají služeb, které daný systém poskytuje.
Možná si říkáte, že na provedení takového testu nic není, vždyť přeci máme nástroje, které slouží k provedení automatizovaných testů webových aplikací a vytvořit pomocí takového nástroje testovací skripty, které budou simulovat chování typických uživatelů vaší aplikace je snadné, stejně jako spustit tento skript třeba 1000krát. Ano, tímto způsobem můžeme snadno vyzkoušet, jak se aplikace bude chovat, když k ní bude připojeno současně 1000 uživatelů.
Problém je, že pokud chcete opravdu simulovat provoz v reálném prostředí, nemůže se spokojit s tím, že vytvoříte testovací prostředí, které bude odpovídat produkčnímu, a v aplikaci založíte testovací účet a pak pod ním necháte robota se 1000x přihlásit a provést předpřipravenou sadu skriptů. Tím byste jen otestovali, jak se systém chová v případě, že by si jeden jediný uživatel vytvořil 1000 sezení. A řešením dokonce není ani vytvoření 1000 různých účtů.
Takhle byste např. nikdy nezjistili, že systém začne při určitém počtu současně připojených uživatelů zobrazovat data jiného uživatele. Vy potřebujete vytvořit nejen odpovídající množství účtů, ale zároveň musíte nastavit práva v systému tak, že každý účet bude mít přístup jen ke svým datům a ta data navíc budou jedinečná. Nestačí tedy jednoduše zkopírovat stejná data na tisíc míst, to byste zase nic nepoznali.
Vy ta data budete muset buď vyrobit, nebo zkopírovat databázi uživatelů z produkčního prostředí do testovacího a použít reálná data. V takovém případě zvažte, zda neprovést i scrambling těch dat. Určitě ale nezapomeňte na důsledné oddělení testovacího a produkčního prostředí, protože pokud tak neučiníte, mohlo by se snadno stát, že servery z testovacího prostředí začnou komunikovat se servery z produkčního prostředí.
Tip: Od věci také není během load testu nechat ve vašem systému pracovat skutečné uživatele, neboť tím se ještě více přiblížíte reálnému provozu. No a nakonec můžete provést ještě stress test a pokud i tím aplikace úspěšně projde, máte velkou šanci, že stejně dobře si vaše aplikace povede i v okamžiku, kdy ji vystavíte do internetu. Hodně štěstí.
Jak provádíte load testing vy a jaké nástroje používáte?
Automatizované testy aplikací typu klient-server
V tomto příspěvku se podíváme na automatizované testy aplikací typu klient-server, které mohou být v zásadě dvojího typu.
V obou případech musíme na nějakém stroji spustit robota, který bude automatizované testy provádět. Rozdíl spočívá pouze v tom, že buď bude robot simulovat uživatele dané aplikace nebo stroj, který uživatel používá.
Simulace uživatele
V tomto případě bude robot provádět vybrané operace tak, jak by je prováděl uživatel systému. Výzvou, kterou musí automatizace tohoto typu řešit, je především porozumět“ obsahu zobrazovaných údajů, neboť uživatel na obrazovce vidí hned, jaký je výsledek, ale automat musí nejprve správně identifikovat pole či oblast, kde se výsledek zobrazuje a následně rozpoznat výsledek, což bývá složité zejména u testování tlustých Windows klientů. Dalším problémem je krátká životnost těchto testů, neboť změna rozvržení stránky si může vynutit i přepsání kódu testu.
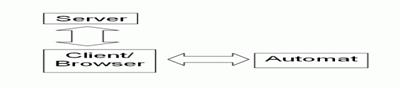
Simulace stroje
V tomto případě se klient úplně obchází a testuje se čistě funkcionalita serveru – volání serverových funkcí (requestů na server) se simuluje buď jako http Request, Remote Function Call, WebService Call nebo jinou další technikou, kdy užitá technika závisí na typu klienta a typu prováděného testu. Výhodou této metody je, že je odolná vůči změnám v GUI aplikace. Její nevýhodou naopak je, že se vůbec netestuje strana klienta a pokud na ní dochází k nějakým důležitým činnostem (typicky validace vstupů), zůstává tato část neotestována.
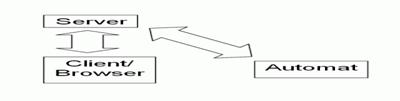
Nástroje pro automatizované testování
Na trhu je poměrně široký výběr nástrojů pro provádění automatizovaných testů ovšem s velkými rozdíly pokud jde o komfort a údržbu scénářů a rozsah podporovaných technologií.
Enterprise řešení
Před několika lety ovládaly trh specializované firmy Mercury Interactive a Rational Software. Dnes je situace jiná pouze v tom, že se obě staly součástí globálních firem HP a IBM. Vedle nich existuje řada menších firem s podílem méně než jednotky procent trhu. Software této kategorie využívají významní provozovatelé systémů jako finanční instituce, telco operátoři apod. Typická cena instalovaných licencí u těchto uživatelů je v řádu milionů korun. Jednotková cena za „seat license“ čili jmenovaného uživatele jednoho produktu se uvádí kolem 8000 dolarů (150000 Kč). Cena konkurentních uživatelů bývá vyšší. TestPartner uvádí 9127 USD za „1 Concurrent User License“. Ovšem pro běžné použití nikdy nestačí zakoupení jedné uživatelské licence pro jeden produkt, a navíc ani licenční podmínky to nemusí umožňovat.
HP Quality Center je webový systém pro komplexní řízení testování, původně z dílny Mercury Interactive. Využívá technologii client-server a má pět hlavních modulů Releases, Requirements, Test Plan, Test Lab and Defects Pro vlastní testování slouží dva z nich – Test Plan se používá k tvorbě a organizaci test cases, buď pro manuální nebo automatické testy. Test Lab je modul sloužící ke spuštění testů uložených v Test Plan. V případě manuálních testů vede testera při vyplňování výsledku testu. U automatizovaného testu ukládá výsledek testu pro srovnání s uloženým očekávaným výsledkem. HP Quick Test Professional je nástroj sloužící primárně pro automatizaci regresního testování funkcí, které vyžadují interakci s uživatelem. Je určen pro webové rozhraní nebo aplikace využívající MS Windows. Slouží pro zachycení uživatelových (testerových) akcí do skriptu, který pak použije HP Quality Center k provedení testu.
IBM Rational Functional Tester je nástroj s podobnými funkcemi jako HP Quick Test Professional. Pochází však z divize Rational Software. Akce uživatele-testera na testované aplikaci jsou zachyceny jako Java nebo Visual Basic.net skript. Od verze 8.1 zachycuje nástroj také obrazovky testované aplikace. To výrazně usnadňuje pozdější změny testovacího scénáře, které mohou být provedeny pomocí GUI, které tester zná, bez nutnosti měnit skript. Tester také specifikuje kontrolní body testu. V průběhu testu se při dosažení kontrolního bodu zaznamenají zvolené parametry (hodnota položky, stav objektu apod.), které pak slouží k porovnání s očekávanými údaji.
Obdobné nástroje s menším podílem na trhu jsou například TestPartner firmy Micro Focus nebo SilkTest původně od firmy Borland je dnes také součástí portfolia firmy Micro Focus, která v roce 2009 Borland koupila.
Střední kategorie
Pod úrovní produktů kategorie enterprise existuje řada firem nabízejících méně univerzální a zpravidla méně škálovatelné produkty v cenové kategorii od stovek do tisíce dolarů, které ovšem mohou adekvátně splnit účel, pro který byly vytvořeny. Uveďme dva příklady takových nástrojů.
Wapt je nástroj pro testování zátěže webových stránek a aplikací s webovým rozhraním. Produkt simuluje zátěž stovek až tisíců uživatelů na testované webové stránce, a to včetně simulace chování uživatelů na příslušných stránkách nebo aplikaci. Cenová hladina licencí je od 350 USD za licenci pro jeden počítač, s koupeným počtem licencí cena za jednotku klesá.
TestComplete je nástroj společnosti AutomatedQ pro automatizované unit, regresní, a funkční testování a pro zátěžové testování http. Nástroj je určen pro Windows a webové aplikace. Podporuje .NET, WPF, Silverlight, Ajax, Java, JavaFX, Flex a Flash; prohlížeče Internet Explorer 8 a Firefox 3.5, mobilní systémy Windows Mobile, Pocket PC, Smartphone support a OS Windows 7, Vista, XP, 2000, Windows Server 2003 and 2008. Cena rozlišuje Enterprise Edition, od 2000 USD za jednu „named user“ licenci nebo 4500 USD za jednu „concurrent user“ licenci. Obdobné licence pro Standard Edition jsou 1000 a 3000 USD. Standardní verze ovšem nemá schopnost testovat webové aplikace nebo http load testing.
Open source řešení
Otevřenost existující ve vývojovém prostředí webových technologií vedla ke vzniku řady open source řešení, která lze přizpůsobit a uplatnit tam, kde jsou k dispozici vývojoví pracovníci s touto kvalifikací. Mezi osvědčená řešení patří následující frameworky:
Selenium je framework pro testování webových aplikací. Poskytuje nástroj pro záznam a playback scénářů bez nutnosti znalosti skriptovacího jazyka. Součástí Selenia je doménově specifický jazyk (DSL) umožňující psát testy v prostředí Java, Ruby, Groovy, Python, PHP a Perl. Je podporován na platformách Windows, Linux a Macintosh.
JUnit je testovací framework pro jazyk Java. Hrál významnou roli při tvorbě techniky test-driven development, kdy vývoj softwaru je rozdělen na krátké vývojové cykly, z nichž každý začíná konstrukcí testovacího případu. Junit byl aplikován na další jazyky – Ada (AUnit), PHP (PHPUnit), C# (NUnit), Python (PyUnit), Fortran (fUnit), Delphi (DUnit), Free Pascal (FPCUnit), Perl (Test::Class and Test::Unit), C++ (CPPUnit), R (RUnit) a JavaScript (JSUnit).
Jmeter je projekt Apache Jakarta, který slouží pro zátěžové testování webových aplikací a služeb. Lze ho použít pro testování JDBC, FTP, LDAP, webservices, JMS, HTTP a generických TCP.
Jtest je produkt pro testování a statickou analýzu kódu v jazyku Java. Vyvíjí a podporuje jej společnost Parasoft, která nabízí několik typů licencí. Produkt slouží pro generování scénářů pro unit testy, regresní testování, statickou analýzu a code review.
Downgrade test
Myslíte si, že když úspěšně otestujete přechod na novou verzi systému a v rámci testování se neobjeví žádné problémy, že máte vyhráno?
Vězte, že problémy se obvykle objeví až po nějaké době používání a v některých případech jsou dokonce takového rázu, že není jiné cesty, než se zase vrátit k předchozí funkční verzi. Možná si teď říkáte, v čem je problém, máte přeci zpracovaný a otestovaný DRP a sekundární server pro případ výpadku. Nainstalujete na něj předchozí verzi, uživatele přesměrujete na něj a nikdo si ničeho ani nevšimne.

Testy dopadly výborně
Možná, ale co když vám řeknu, že spolu s novou verzí aplikace došlo i ke změně DB schématu? Zjišťovali jste, k jakým všem změnám s nasazením nové verze systému skutečně dochází? Obvykle se to nedělá, takže předpokládám, že jste se spokojili s tím, že funkční a performance testy dopadly výborně, systém obsahuje všechny požadované vlastnosti a je rychlejší a stabilnější než předchozí verze. Uvědomujete si ale, že když na sekundární server nainstalujete předchozí verzi aplikace, tak nebude s novou verzí DB pracovat. Dobře, tak nainstalujeme i předchozí verzi DB a data obnovíme ze zálohy, ne? Omyl, data, která jste mezitím pořídili, jsou v nové verzi systému uložena i v nové struktuře, neboť je použito nové DB schéma, takže do starého schématu je budete muset převést. Už jste to někdy dělali? Že ne, pak máte problém. Vaši DB administrátoři umí sice provést backup a restore celé DB, dokážou optimalizovat dotazy, vytvářet nad příslušnými tabulkami indexy, ale DB schéma nenavrhovali. To dělala firma, co vám daný systém dodala, takže se budete muset obrátit na ní.
Nechodí, stále nechodí
Obrátíte se tedy na firmu, a co myslíte, že se dozvíte? Nejspíš, že žádný jejich zákazník problém nehlásil, všem nová verze systému bezvadně funguje a jsou s ní naprosto spokojeni. Co jste proboha čekali, že se dozvíte? Doufám, že jste si nemysleli, že by renomovaná firma, jejíž systém získal i mnohá ocenění, vypustila do světa novou verzi systému bez důkladného otestování? Jak je tedy ale možné, že vám ten jejich úžasný systém nefunguje? Nejspíš proto, že váš systém byl řekněme poněkud víc customizován, aby splnil vaše náročné požadavky. Mimochodem, byly to tenkrát pěkné blbosti, co jste požadovali. Firma vám sice tenkrát doporučovala provést optimalizaci procesů, ale vy jste si prosadili svojí a teď to tady máte.
Obnova provozu
Dobře, byla to tenkrát možná chyba, ale jak z té šlamastiky ven? Pro dodavatele systému by neměl být problém převést data z nového DB schématu do starého. Skript na převod ze starého do nového přeci má, jinak by nemohl proběhnout upgrade. Úpravou instalačního skriptu by tak mělo být možné provést downgrade na předchozí verzi a pokračovat na ní dál, dokud nebude problém ve vaší nové verzi odstraněn. Možná, že k chybě došlo u dodavatele systému, že opravdu neotestoval vaší custmizovanou verzi, která byla od verzí ostatních zákazníků natolik odlišná, těžko říci. Další možností je posoudit, nakolik jsou problémy v nové verzi závažné a zda není možné s nimi systém provozovat a čekat na dodání opravného patche.
Závěr: Do svého testovacího plánu byste měli zahrnout i downgrade test, nikdy nevíte, co se může stát a vy byste měli mít vždy možnost vrátit se zpět k předchozí funkční verzi.
Vícevrstvá architektura: popis vrstev
Vícevrstvá architektura se často označuje jako multi-tier nebo ještě častěji jako n-tier, kde n vyjadřuje počet vrstev, ze kterých se vícevrstvá architektura skládá.
Jako vícevrstvá se označuje proto, že funkčnost aplikace je rozdělena mezi několik vzájemně spolupracujících vrstev, které spolu komunikují přes definované rozhraní. Nejběžnějším příkladem vícevrstvé architektury je architektura třívrstvá, kterou používá mnoho webových aplikací. V takovém případě rozlišujeme vrstvu, která se stará o uživatelské rozhraní, vlastní logiku aplikace a databázi.
Tier vs. layer aneb není vrstva jako vrstva
Pokud budeme hovořit o vícevrstvé architektuře, tak dříve či později narazíme na pojmy tier a layer, které bývají dost často zaměňovány, ač je mezi nimi dost podstatný rozdíl. Vzhledem k tomu, že pojem tier a layer nelze do češtiny dost dobře přeložit, budu se raději tam, kde to bude nutné, držet anglických termínů tier a layer. Rozdíl mezi nimi je ten, že pokud se hovoří o tiers, máme na mysli fyzickou HW vrstvu, zatímco v případě layers máme na mysli logickou SW vrstvu.
Horizontální vs. vertikální přístup, aneb zvyšujeme výkon
Pokud budeme aplikaci již od počátku vyvíjet jako vícevrstvou, můžeme se kdykoliv později rozhodnout z nejrůznějších důvodů pro umístění jednotlivých logických vrstev (layers) na dedikované fyzické stroje (tiers). Jedná se o tzv. vertikální přístup (vertical approach), kdy předem vyhradíme určité stroje k provádění konkrétních úloh. Nic nám však nebrání v horizontálnímu přístupu (horizontal approach), který spočívá čistě v posílení výkonu daného tieru např. přidáním dalšího serveru do clusteru, tím může být zajištěno vyrovnávání zátěže (load balancing). Oba přístupy je samozřejmě možné kombinovat. Takový přístup se pak nazývá diagonální (diagonal approach).
Optimální počet vrstev
Nelze stanovit, jaký počet vrstev je optimální, vždy to závisí na konkrétním nasazení, potřebách uživatelů a celkové architektuře řešení. Mohou nastat případy, kdy navýšení počtu vrstev může celému řešení uškodit a naopak. Jde o to, jakým způsobem spolu jednotlivé vrstvy komunikují. Layers, které jsou navrhnuty, aby komunikovaly v rámci jednoho tier, mohou využívat tzv. chatty interface. Do doby, kdy jsou tyto layers umístěny na jednom tier (rozuměj serveru), nám to nemusí vadit, ale v okamžiku, kdy se rozhodneme je umístit na samostatné tiers (servery) by nám to začít vadit mohlo, protože by mohla výrazně vzrůst meziserverová komunikace. Z těchto důvodů by layers měly používat spíše tzv. chunky interface. Popsání rozdílu mezi těmito dvěma interfacy bych se chtěl věnovat v některém z příštích příspěvků.
Pojmenování vrstev
Počet vrstev a jejich pojmenování není jednotné. My si stručně popíšeme 5-vrstvou architekturu webové aplikace, která bude obsahovat tyto tiers: client, presentation, business, integration a enterprise. U každé vrstvy si uvedeme další možné pojmenování a účel, ke kterému slouží. Pokusím se o high level popis, protože se nechci věnovat konkrétní technologii nebo frameworku. Tam, kde to budu považovat za nutné, zmíním konkrétní produkt, aby bylo možné si představit, co se za danou vrstvou v praxi skrývá.

Client tier
Tato vrstva se někdy nazývá také jako GUI tier nebo presentation tier a komunikuje s prezentační vrstvou. Klientem může být, co se týká HW, stolní počítač nebo notebook stejně jako mobilní telefon. Snahou vývojáře je, aby jeho aplikace byla pokud možno nezávislá na platformě, na které bude spuštěna. Běžně rozlišujeme tři typy klientů: tenký (thin/slim/lean), tlustý (thick/fat) a chytrý (smart/rich). Tenký klient je obvykle browser, do kterého je aplikace po zadání URL stažena ve formě (X)HTML stránky, kdy vzhled bývá často upraven CSS a může a nemusí být pro její správný běh vyžadováno povolení např. JS. Tlustý klient je aplikace, která se musí na zařízení uživatele nainstalovat. Polotlustý klient se nachází někde mezi tenkým a tlustým klientem a často využívá JAVA, ActiveX, Flash, Silverlight.
Presentation tier
Tato vrstva, někdy nazývaná také jako web tier nebo presentation logic tier obsahuje obvykle dvě layers, pokud je jako architektonický vzor (architectural pattern) použit MVC (Model-View-Controller) a to Controller a View. Obvykle běží na webovém serveru, tím může být např. IIS nebo Apache. Tato vrstva je odpovědná za poskytování statického obsahu jako jsou HTML stránky, CSS, JavaScript, obrázky, animace a video a to na základě požadavků, které přicházejí z vyšší vrstvy a komunikaci s business vrstvou. V případě požadavku na dynamicky generovaný obsah nebo službu je zaslán požadavek na aplikační server. Webový server může využívat cachování a tím počet požadavků na business vrstvu minimalizovat, to je žádoucí především proto, aby se uživateli stránky zobrazovaly co nejrychleji. Na webovém serveru se také velice často nachází serverový certifikát, kterým server prokazuje svou identitu klientovi. S webovým serverem též klient navazuje šifrované SSL/TLS spojení. Obvykle je to jediná vrstva, která má veřejnou IP adresu a je přímo dostupná z internetu.
Business tier
Tato vrstva někdy také nazývaná jako business logic tier nebo domain tier se nachází na aplikačním serveru, kterým může být např. Tomcat, GlassFish nebo Websphere. Pokud je jako architektonický vzor použit MVC, nachází se zde Model. Tato vrstva sousedí s prezentační a integrační vrstvou. Na této vrstvě se provádí kromě samotných výpočtů a vyhodnocování i autentizace (authentication), autorizace (authorization) uživatele a případně i personalizace (personalization) jeho profilu. Aplikační servery mohou být kvůli rozložení zátěže (load balancing) zapojeny v clusteru.
Integration tier
Tato vrstva, nazývaná někdy také jako data access tier sousedí s vrstvou business a enterprise. Jejím cílem je zajistit business tier přístup k datům, aniž by se musela vyšší vrstva starat o to, jaká DB byla použita. Díky této vrstvě resp. jejímu obecnému rozhraní může být databáze změněna, aniž by musela být změněna business vrstva. Ta bude s integrační vrstvou komunikovat pořád stejně a integrační vrstva zajistí, že data budou zapsána nebo načtena správně.
Enterprise tier
Tato vrstva nazývaná někdy též jako data tier nebo persistence tier, bývá často označována jako nejnižší vrstva a obsahuje data v podobě nějaké relační databáze (RDBMS), objektové databáze (ODBMS) nebo prostého souboru (file). Může se jednat o MySQL, MS SQL, Oracle, ale i textové soubory ve formátu CSV, ASC, XML. Enterprise tier přijímá požadavky od vyšší vrstvy (integration tier) na čtení, zápis nebo mazání a stará se uložení a poskytování dat.
HW a OS tier
O následujících 2 vrstvách se literatura věnující se vývoji vícevrstvých aplikací příliš často nezmiňuje. A tak není divu, že otázka výběru vhodného operačního systému a HW bývá dost často při vývoji vícevrstvé aplikace podceňována a nezřídka se tak zákazník dočká nepříjemného překvapení, protože v jeho produkčním prostředí aplikace nefunguje stejně jako v testovacím prostředí dodavatele.
OS tier
Je třeba si uvědomit, že každá vrstva musí běžet na nějakém operačním systému a ten může být dokonce na každé vrstvě v jiné verzi nebo se dokonce může jednat i OS poskytovaný různými výrobci. V takové situaci jsme potom nuceni spravovat skutečně heterogenní prostředí, ve kterém běží několik různých verzí MS Windows, Unix. Linux.
HW tier
Každý operační systém musí běžet na nějakém hardwaru a ten může být též od různých výrobců. V takovém heterogenním prostředí tak můžeme najít 32bitové i 64bitové stroje, RISC i CISC architekturu využívající symetrický i paralelní multiprocessing.
Poznámka: Webový i aplikační server mohou běžet na jednom fyzickém serveru, potom ale není možné hovořit o presentation a business tier neboť fyzické hranice mezi nimi se stírají. Nezřídka se na jednom serveru nachází presentation, business i integration vrstva, takový tier se poté označuje jako application a dostáváme se tak na 3-vrstvou architekturu. Pokud je vícevrstvá aplikace postavena nad mainframem, přidává se mezi presentation logic layer a business logic layer tzv. assembling logic layer, která se stará o navázání a udržení spojení s mainframem.
PCI DSS: konkrétní bezpečnostní opatření
V tomto příspěvku se dozvíte, co je to PCI DSS, pro koho je závazný, jaký si klade cíl a především jak chce tohoto cíle dosáhnout.
Cílem PCI DSS (The Payment Card Industry Data Security Standard) je zamezit karetním podvodům a to zavedením vhodných bezpečnostních opatření u společností, které data držitele karty zpracovávají, přenášejí nebo uchovávají. Ač PCI Security Standards Council skromně uvádí, že se jedná jen o 12 požadavků, jde ve skutečnosti o soubor 197 naprosto konkrétních bezpečnostních opatření, u kterých je navíc i uvedeno, jakým způsobem ověřit, že byly splněny.
Vzhledem k tomu, že tento obsáhlý soubor opatření je volně ke stažení na adrese www.pcisecuritystandards.org okomentuji zde stručně jen jednotlivé požadavky a do závorky uvedu, kolik opatření daný požadavek generuje.
Build and Maintain a Secure Network
Požadavek č. 1: „Install and maintain a firewall configuration to protect cardholder data“ požaduje, aby byly nainstalovány firewally, nastavena na nich odpovídající pravidla a byla vytvořena a udržována dokumentace popisující datové toky, nastavení pravidel, uvedena odpovědnost jednotlivých osob za správu firewallů a popsán proces provádění změn. Dále standard požaduje, aby kontrola nastavení firewallu byla prováděna minimálně každých 6 měsíců. (18 opatření)
Požadavek č. 2: „Do not use vendor-supplied defaults for system passwords and other security parameters“ požaduje, aby byla na všech systémech a zařízeních změněna defaultní hesla, zakázány nepoužívané služby a odinstalováno vše nepotřebné. Vpřípadě wireless zařízení by se měl místo defaultního WEP protokolu používat WPA nebo WPA2. Pokud ho zařízení nepodporuje, mělo by se upgradovat. Kromě toho by jednotlivé služby měly běžet na samostatných serverech. Ke konzoli serveru by se měl administrátor připojovat výhradně přes SSH nebo SSL. (9 opatření)
Protect Cardholder Data
Požadavek č. 3: „Protect stored cardholder data“ požaduje, aby do určeného a chráněného úložiště byly ukládány informace jen nezbytně nutné a uchovávány jen po nezbytně nutnou dobu. Měla by se používat pouze silná kryptografie, data by se měla šifrovat raději na úrovni disku než na úrovni souborového systému. Šifrovací klíče by měly být bezpečně distribuovány, ukládány, likvidovány, měly by se periodicky měnit a přístup k nim by měl být omezen. Dále je vyžadována segregace rolí a vícestupňová kontrola přístupu. Správa klíčů by měla být popsána. Pokud jde o zobrazování čísla karty, tak je povoleno zobrazovat maximálně jen prvních šest a poslední čtyři číslice. (18 opatření)
Požadavek č. 4: „Encrypt transmission of cardholder data across open, public network“, požaduje, aby byla nasazena silná kryptografie, SSL/TLS nebo IPSEC protokol a neměl by se v žádném případě používat WEP. Číslo karty by nemělo být posíláno mailem apod. (3 opatření)
Maintain a Vulnerability Management Program
Požadavek č. 5: „Use and regularly update anti-virus software or programs“ požaduje, aby byla nasazena ochrana proti malwaru a pokud možno na všech systémech a byl zajištěn automatický upgrade a vznikaly logy zaznamenávající činnost těchto antivirových prostředků. (3 opatření)
Požadavek č. 6: „Develop and maintain secure systems and applications“ – požaduje, aby byly nasazovány patche a to nejpozději do jednoho měsíce od jejich uvolnění. Společnost by si měla zajistit, že bude informována o nově objevených zranitelnostech, např. tím, že bude odebírat nějaký bulletin. Měl by být stanoven bezpečný proces vývoje SW. Mělo by se vyvíjet v souladu s metodikou OWASP a důkladně by se mělo i testovat. Mělo by být oddělené vývojové, testovací a produkční prostředí. Jedna osoba by neměla mít přístup do vývojového, testovacího a produkčního prostředí. K testování a vývoji by se neměla v žádném případě používat produkční data a před nasazením do produkce by měla být odstraněna testovací data a účty. (30 opatření)
Implement Strong Access Control Measures
Požadavek č. 7: „Restrict access to cardholder data by business need-to-know“ požaduje, aby přístup k datům byl řízen na principu need-to-know a uživatel v systému disponoval jen právy nezbytně nutnými k výkonu dané práce. (7 opatření)
Požadavek č. 8: „Assign a unique ID to each person with computer access“ požaduje, aby každé osobě bylo přiděleno jedinečné ID. Vzdálený přístup by se měl realizovat přes VPN a měla by být použita dvoufaktorová autentizace. Hesla by se měla měnit každých 90 dní, jejich minimální délka by měla být nastavena na 7 znaků a měla by obsahovat písmena a čísla. Historie hesel by měla být nastavena na hodnotu 4 a uživatel by měl mít k dispozici maximálně 6 pokusů o přihlášení, poté by mělo dojít k uzamčení účtu na 30 minut. (20 opatření)
Požadavek č. 9: „Restrict physical access to cardholder data“ požaduje, aby fyzický přístup k serverům a síťovým prvkům byl umožněn pouze vybraným osobám. Každá osoba by měla nosit viditelně visačku. Pohyb osob by měl být monitorován. Logy o návštěvnících by měly být uchovávány minimálně po dobu třech měsíců. Média by měla být bezpečně uchovávána, přepravována a skartována. (19 opatření)
Regularly Monitor and Test Networks
Požadavek č. 10: „Track and monitor all access to network resources and cardholder data“ požaduje, aby bylo dokumentováno, co se má logovat a jaké údaje má auditní záznam obsahovat. Čas na všech serverech musí být synchronizovaný. Musí být zajištěno, že auditní záznam nemůže být modifikován, proto by se měl log zálohovat na centrální server. Auditní záznamy by měly být k dispozici minimálně rok dozadu. Logy by měly být vyhodnocovány nejméně 1x denně. (22 opatření)
Požadavek č. 11: „Regularly test security systems and processes“ požaduje, aby se skenování zranitelností provádělo interně a externě a to minimálně každé 3 měsíce a po každé významné změně. Interní a externí penetrační testy by se měly provádět minimálně 1 ročně a též po každé významné změně. Funkce IDS/IPS by měla být též ověřována. (6 opatření)
Maintain an Information Security Policy
Požadavek č. 12: „Maintain a policy that addresses information security“ požaduje, aby byla vydána bezpečnostní politika, související bezpečností standardy a byli s nimi prokazatelně seznámeni všichni zaměstnanci. Ti by se měli též školit a minimálně ročně by měli být přezkušováni. (42 opatření)
Kromě těchto 12 požadavků obsahuje standard ještě přílohu, ve které jsou uvedeny další 4 opatření.
Vzhledem k tomu, že 201 opatření, které by měli obchodníci a další organizace implementovat, je opravdu dost a jejich zavedení může být pro mnohé z nich časově i finančně značně náročná záležitost, uvolnil PCI Security Standards Council spreadsheet, který umožňuje s jednotlivými opatřeními lépe pracovat. Nevím, co přesně vedlo PCI SSC k tomu, že všude uvádí jen 12 požadavků, když ve skutečnosti jich je mnohem více. Můžeme se jen domnívat, že nechtěl obchodníky a další organizace hned na začátku vystrašit.
Závěr: PCI DSS přináší soubor naprosto konkrétních a rozumných bezpečnostních opatření, která jsou navíc aplikovatelná i ve společnostech, pro které není tento standard primárně určen.
Test status report
Co je to test status report? Jednoduše řečeno, jedná se o zprávu o výsledcích testování, kterou zpravidla Test manager předkládá vlastníkovi.
Stejně jako všechny ostatní dokumenty, které v rámci testování vzniknou, i tento dokument by měl obsahovat jednoznačný identifikátor. Vzhledem k tomu, že ne vždy se povede plán testování dodržet, mělo by se ve výsledné zprávě objevit, co přesně se testovalo a kdo, kdy, kde a jak testování prováděl. Jedině tak je možné splnit podmínku opakovatelnosti a měřitelnosti.
Podmínka opakovatelnosti a měřitelnosti testů znamená, že jestliže bude test nad stejnými daty proveden znovu a podle stejných testovacích scénářů a za použití stejných testovacích skriptů, měli bychom dosáhnout velice podobných výsledků. Záměrně nepíši stejných, protože k jisté odchylce u určitých typů testů může dojít a nelze tuto skutečnost považovat za chybu. V test status reportu by měl být uveden odkaz na:
Pokud testovaný SW vykazoval nějaké odlišnosti od specifikace, mělo by se to v reportu objevit. V reportu by měly být též uvedeny odchylky od testovacího plánu, scénářů a skriptů. Stejně tak, pokud nějaké vlastnosti nebyly testovány, měl by být uveden důvod. Co je vůbec nejdůležitější a co každého zajímá asi ze všeho nejvíc, je počet a typ:
odhalených defektů,
opravených defektů a
neopravených defektů.
Po seznámení se s výsledky testování je na vlastníkovi, aby rozhodl o dalším postupu, např. zda je možné aplikaci nasadit do produkčního prostředí nebo ne. Ostatně toto rozhodnutí by měl vždy učinit vlastník, neboť on nese odpovědnost.
Rizika virtualizace
O virtualizaci serverů se v poslední době dost často mluví v souvislosti se snižováním nákladů. Ostatně není se čemu divit, protože pokud má na základě doporučení výrobců většina aplikací pro svůj běh vyhrazen samostatný server, jsou potom výpočetní střediska plná jednoúčelových serverů. Taková společnost pak má velké množství serverů, jejichž výpočetní kapacitu není schopna plně využít a také provoz těchto serverů je pro ni zbytečně nákladný. U každého takového serveru totiž musí řešit minimálně otázku jejich umístění, napájení a chlazení. To představuje náklady, které rozhodně nejsou zanedbatelné. Myšlenka snížit náklady prostřednictvím virtualizace je tedy vcelku logická, neboť je založena na předpokladu, že když na jednom fyzickém serveru poběží více virtuálních serverů, které budou efektivně využívat zdroje, kterými fyzický server disponuje, stačí otázku umístění, napajení a chlazení řešit jen pro tento server.
Druhy virtualiazace
Emulace – softwarově se emuluje hardwarová platforma, která není fyzicky dostupná. Vzhledem k tomu, že se musí kompletně emulovat hardwarová platforma, může dojít k viditelnému zpomalení systému, na kterém se emulátor spouští.
Plná virtualizace – není potřeba provádět žádné modifikace operačního systému ani aplikací, které mají běžet ve virtuálním serveru. Hostovaný OS je důsledně oddělený od HW. Vzhledem k tomu, že je nutné emulovat řadu operací jako je přístup k paměti, většinu instrukcí CPU, přístup na disk, není možné dosáhnout plného výkonu.
Paravirtualizace – vzhledem k tomu, že se simulace HW neprovádí, lze dosáhnout mnohem vyššího výkonu a s menší režií, je však nutné modifikovat jádro hostovaného OS.
Jak virtualizace funguje
Na fyzický server se nainstaluje nějaký virtualizační software, který je schopen přidělovat systémové prostředky jednotlivým virtuálním serverům podle potřeby a aktuálního zatížení. Základem virtualizačního SW je tzv. hypervizor, což je softwarová vrstva mezi hardwarem a virtualními servery, která se stará o přidělování prostředků jednotlivým virtuálním serverům. Důležité je, že virtuální server nikdy nepřistupuje k HW přímo, ale využívá služeb, které poskytuje hypervizor. Velikost hypervizoru se pohybuje v řádech několika málo KB až MB. Nabízí se tedy úvaha, že čím menší bude velikost hypervizoru, tím bude jednodušší a tedy i odolnější proti útokům.
Pokud se zamyslíte nad tím, jak virtuální server funguje, jistě sami přijdete na to, že asi nebude příliš dobrý nápad používat virtuální server pro takovou aplikaci, která provádí velký počet I/O operací. A to z toho důvodu, že ke sběrnici stejně jako k paměti nebo procesoru nemá váš virtuální server přímý přístup. Nezapomínejme na to, že všechny požadavky na přístup k HW musí jít vždy přes hypervizora, pokud se nejedná o virtualizaci na úrovni hardwaru nebo firmwaru, takže k určitému zpomalení, byť v mnoha případech nepodstatnému, zde přesto dochází.
Pro některé aplikace však toto zpomalení může být kritické. Nasazení do produkčního prostředí by proto měl předcházet důkladný performance test, jedině tak se lze vyhnout nepříjemnému překvapení. Po virtualizaci lze pozorovat pokles výkonu systému v řádech několika málo procent. Pozitivní ale je, že např. přenos dat mezi dvěma guesty na stejném hostu je výrazně rychlejší než mezi dvěma fyzickými systémy, protože nejste omezováni rychlostí přenosové soustavy.
Rizika virtualizace
Virtualizace bezesporu vede ke snížení nákladů, ale zároveň nějak musíme zvládat rizika, která jsme možná předtím, když každá aplikace běžela na svém vlastním fyzickém serveru, moc řešit nemuseli.
Zhoršení kvality poskytování služeb
ICT může podlehnout euforii a začít na stávajícím fyzickém serveru vytvářet další a další instance virtuálních serverů. Především proto, že vytvořit další virtuální server je mnohem jednodušší než zakoupit další fyzický server. Časem tak může dojít ke zprovoznění většího počtu virtuálních serverů než kolik jich je fyzický server schopen zvládnout a ICT nebude moci dostát svým závazkům. Na plánování nového virtuálního serveru by se proto měl podílet celý tým zahrnující správce systému, aplikace, databáze, sítě apod., tak jako jste to nejspíš dělali, když jste si pořizovali nový fyzický server.
Útok na fyzický server
Je třeba si uvědomit, že fyzický server, na kterém poběží několik virtuálních serverů, bude sice pořád čelit stejným hrozbám jako předtím, ale pravděpodobnost výskytu některých hrozeb bude spíše vyšší, než nižší. Především proto, že pro útočníka se stane tento server mnohem zajímavějším cílem. Když se mu totiž podaří tento server vyřadit z provozu, vyřadí tím z provozu i všechny virtuální servery, které na něm běží a způsobí tak mnohem větší škodu.
Útok na hypervizora
Hypervizor vytváří prostředí pro běh virtuálních strojů, izoluje je od sebe a zprostředkovává přístup k fyzickým zdrojům. Zranitelnost hypervizoru je velice nízká, stejně jako pravděpodobnost hrozby útoku. Avšak v okamžiku, kdy se útočníkovi podaří kompromitovat hypervizora, získá přístup ke všem běžícím virtuálním serverům a tedy i aplikacím a datům v nich zpracovávaných. Toto riziko je potřeba monitorovat, protože to, že zatím nebyl dokumentován úspěšný útok na hypervozora neznamená, že k němu nemůže v budoucnu někdy dojít.
Spuštění nezabezpečeného systému
Rychlost a snadnost, s jakou lze klonováním vytvářet nové virtuální stroje může vést k tomu, že dojde ke spuštění systému, který nebude obsahovat aktuální antivirové prostředky, patche a nebude splňovat bezpečnostní standardy. Takový systém pak bude zranitelný a útočník těchto zranitelností může zneužít např. k tomu, aby získal práva administrátora na tomto serveru.
Obnova neaktuální verze
Rychlost a snadnost s jakou lze provést obnovu systému v případě havárie může vést k obnově nějaké starší verze. A starší verze mohla např. obsahovat jinou business logiku. Toho si zpočátku nemusí nikdo všimnout, ale najednou se začnou objevovat staré chyby, které již byly jednou odstraněny. V okamžiku, kdy si těchto chyb někdo všimne, může již být pozdě.
Nedostatečné oddělení serverů
Virtualizace umožňuje snadno vytvořit síťová propojení mezi jednotlivými virtuálními servery, které byly dříve od sebe odděleny firewallem nebo se mezi nimi nacházel nějaký IDS/IPS.
Vyšší chybovost
Snadnost a rychlost s jakou lze provádět změny a přidávat další virtuální servery přináší i vyšší možnost zanesení chyby např. od značně přetíženého nebo nezkušeného správce.
Špatně nastavená práva
Mohou být špatně nastavena oprávnění pro manipulaci s virtuálními systémy.
Závěr: Ochraně serveru, na kterém běží mnoho virtuálních serverů, bychom měli věnovat zvýšenou pozornost a implementovat vhodná opatření vedoucí ke snížení rizik. Pokud se rozhodnete virtualizovat, volte takové řešení, které vám umožní provozovat virtualizaci nad více fyzickými stroji, především proto, aby bylo možné zakoupením a integrací dalšího fyzického stroje celkový výkon podle potřeby zvyšovat. V opačném případě budete, co se zvyšování výkonu týká, značně omezeni možnostmi stávajícího fyzického serveru. Dále doporučuji začít nejprve s virtualizací testovacího a vývojového prostředí. Poté můžete pokračovat s méně důležitými aplikacemi a teprve až když získáte dostatek zkušeností, můžete přistoupit k virtualizaci aplikací pro vás kritických.
Poznámka:Správa virtuálních serverů je časově podstatně méně náročná než správa klasických fyzických serverů. Rovněž doba pořízení a nasazení nového serveru se může zkrátit z několika měsíců nebo dnů až na několik málo hodin nebo minut. Z těchto důvodů se dá očekávat i snížení počtu zaměstnanců ICT, kteří mají správu serverů na starost.






