APT útoky
APT je zkratka Advanced Persistent Threat, tedy pokročilého profesionálně vedeného útoku, který se vyznačuje dlouhou dobou trvání, zpravidla v řádu měsíců až roků. APT útoky nejsou příležitostné či náhodné, ale cíl útoku je předem velice pečlivě nastudován. Útoky nejsou příležitostné či náhodné, ale cíl útoku je předem velice pečlivě nastudován. Co přesně APT útok je a čím se odlišuje od jiných typů sofistikovaných útoků, ještě není zcela ustáleno. Někteří považují APT útok pouze za poslední článek ve vývoji útoků, jiní je považují za úplně nový přístup. Základní definice společnosti ISACA je definuje jednoduše jako hrozbu, která je pokročilá a trvalá. Pokročilostí hrozby je myšleno použití netriviálních technik pro provedení útoku, trvalostí pak to, že APT útoky nejsou jednorázové akce, ale vyznačují se určitou delší dobou trvání. Útočníci se snaží dostat do cílového prostředí, kde setrvávají delší dobu a monitorují citlivé informace, nebo provádí jiné akce k dosažení svých cílů.
Cílem APT útoků se stávají nejčastěji velké organizace, kde mohou útočníci získat nejvíce ceněná data a nejčastější motivací je průmyslová či politická špionáž. Cílem však nemusí být jen data, ale také napadení nějaké služby a dokonce může také během probíhajícího útoku dojít ke změně cílů útočníka. Například může útočník usilovat o citlivé informace, po jejich získání je zneužije a dále sabotuje systémy napadeného… Pro zjištění cílů útočníků je potřeba vzít v úvahu kým útočníci jsou, nebo kým jsou sponzorováni, a o jaká aktiva mohou mít zájem. Útočníků může být celá škála od organizovaných skupin, kterým jde o finanční obohacení, až po armády a rozvědky nepřátelských států, kterým jde o strategické informace.
Klíčové charakteristiky útoku
Jednou z věcí, kterou se APT útoky odlišují, je míra jejich zacílení. Tyto útoky nebývají náhodné a ani nenapadají plošně příliš mnoho zařízení. Jsou zamířeny na předem důsledně vytipované cíle s úmyslem získat přístup k určitým informacím nebo zdrojům (například v případě počítačového červa The Stuxnet Worm tento obsahoval omezení, kterými limitoval své rozšíření na cílové systémy.). Útočník nejdříve detailně zmapuje zamýšlený cíl, což mu umožňuje vytipovat si slabá místa pro průnik do cílového systému a prová- dět i útoky typu social engineering, při kterém se zaměřuje na osoby a spoléhá na selhání lidského faktoru. Velmi často jsou APT útoky vícevektorové, tedy využívají více způsobů kompromitace za účelem získání přístupu, přičemž se snaží využít více slabin v cílovém systému.
APT útoky jsou prováděny zkušenými odborníky s velmi dobrou znalostí dnešních tech-nologií a představují většinou velmi pokročilé typy útoků využívající často zatím neznámých zranitelností (tzv. zero day), které útočníkům umožňují kompromitaci systémů a téměř se nedají odhalit pomocí tradičních postupů. Tradiční postupy založené na rozpoznávání signatur, tedy určitých sekvencí známých škodlivých programů, nemohou pro nově vyvinutý malware fungovat. Při úspěšné kompromitaci útočníci nasazují komplexní, často modulární, škodlivý software, který je schopen dále provádět velmi rozličné útočné akce v cílovém systému. Instalovaný software také může disponovat umělou inteligencí a často se snaží uniknout detekci, například přesouváním umístění škodlivého kódu nebo jeho šifrováním. Útočníci jsou schopni napadnout širokou škálu zařízení, o čemž svědčí například již zmíněný The Stuxnet Worm, který byl schopen infikovat i průmyslové počítače (PLC) ..
Zásadním rozdílem oproti běžným typům útoků je délka trvání útoku. Běžné útoky většinou po průniku do systému provedou požadovanou akci, jako je například získání informací, omezení funkčnosti služby, nebo nainstalování škodlivého programu a dále již útok neprobíhá. V případě instalace škodlivého programu může dojít k začlenění napadeného stroje do tzv. botnetu který může být útočníkem využit i později, ale zpravidla bývá napadený počítač konečným cílem a dále již k útoku nedochází. Naopak u APT útoků dochází v případě kompromitace k instalaci programů, které jsou pak vstupní branou pro automatizované i manuální útoky v cílovém systému. APT útoky jsou často velice dlouhodobě probíhající útoky, které kladou velký důraz na minimální riziko odhalení. Proto mohou APT útoky postupovat relativně pomalu a vyhnout se detekci pomocí skrývání komunikace v běžném provozu. Jako příklad si můžeme vzít napadení amerického úřadu pro personální management z června minulého roku, které probíhalo minimálně rok (od července 2014). U APT útoků se většinou jen velice obtížně zjišťuje doba, kdy byl systém infikován. Organizace jsou z kapacitních důvodů nuceny starší logy mazat a stává se tak, že detekovaný APT útok je vystopován až do počátku uložených logů a nelze stanovit dobu, kdy došlo k infikaci systému. Také rozsah útoku se vzhledem k jeho době trvání a velkým možnostem variability určuje jen ztěžka.
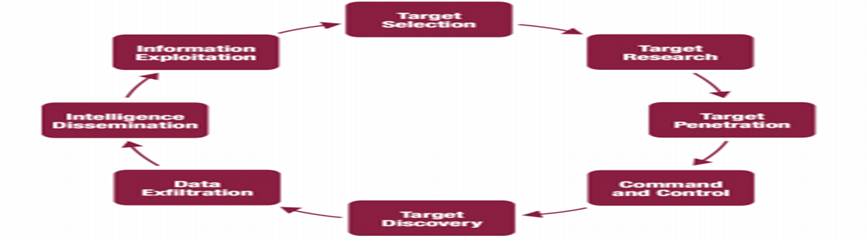
Životní cyklus útoku
Na obrázku 2.1 je znázorněn životní cyklus APT útoku s vyznačenými fázemi. Jak lze na první pohled vidět, je životní cyklus kruhový, protože po úspěšně provedeném primárním cíli útoku často nedochází k ukončení útoku, ale k vytipování dalších cílů s využitím znalostí získaných v předchozích krocích.
Fáze životního cyklu APT útoku
Výběr cíle (Target Selection) Výběr cílů bývá důkladný a jako cíl nejsou určeny pouze nějaká aktiva, ale mohou to být i podružné cíle, které útočníkům následně umožní další postup. Pokud se během probíhajícího útoku změní priority nebo se vyskytnou nové informace není neobvyklé, že se plán útoku, nebo i výběr cíle, změní.
Vnější zmapování cíle (Target Research) Před samotným APT útokem dochází k co nejúplnějšímu zmapování cíle s důrazem na infrastrukturu, identifikací vhodných zdrojů informací a hledání zranitelností, které by mohly sloužit k napadení cíle.
Kompromitace (Target Penetration) Kompromitace je první přímou fází útoku, kdy se útočníci pomocí informací získaných v předchozí fázi dostávají do systému. K tomu většinou nedochází na místech, které mají pro útočníky přímou hodnotu, jako jsou počítače vrcholových managerů organizace nebo přímo datová centra obsahující chtěné informace, protože ty bývají dobře zabezpečeny a přímý útok by byl velice nesnadný. Prvotní kompromitace se většinou vydává cestou nejmenšího odporu a zasahuje stroje zaměstnanců na nižších pozicích, nebo dokonce externích spolupracovníků. Přes tyto body se pak útočníci dostávají do systému, který pak mohou lépe prozkoumat zevnitř a postupně napadnout cílová zařízení.
Zavedení trvalého spojení (Command and Control) Když jsou útočníci v systému, instalují malware, který jim umožní přístup do vnitřní sítě a provádění útoků zevnitř. Malware se po instalaci typicky spojí s útočníky a zahájí monitorování, nebo čeká na případné další instrukce, přičemž se snaží zůstat nedetekován. Často bývá modulární. a po úspěšné infiltraci si stáhne dodatečné moduly, které rozšíří mož- nosti monitorování sítě a provádění útoků. Tento malware může fungovat do značné míry autonomně a odesílat citlivé informace útočníkům.
Zmapování vnitřní sítě (Target Discovery) Když má útočník k dispozici spojení do vnitřní sítě napadeného, dochází k automatickému či manuálnímu zmapování vnitř- ních struktur a instalaci dalších malwarů pro zajištění připojení i v případě odhalení a neutralizování původního spojení. S detailní znalostí vnitřních struktur a informací z vnitřní sítě (které mohou obsahovat samy o sobě citlivé informace, a dokonce i přístupové údaje) je možné detailně naplánovat další postup.
Filtrování informací (Data Exfiltration) Po zmapování vnitřní sítě lze účinně získat požadované informace. Tyto se většinou shromažďují na některém napadeném zařízení v síti oběti a jsou dále komprimovány a šifrovány.
Distribuce informací (Intelligence Dissemination) Jsou-li požadované informace k dispozici a připraveny na odeslání, nastává samotné odeslání těchto dat útočníkům. Pro minimalizaci pravděpodobnosti detekce jsou přenášená data obvykle skryta mezi legitimní komunikaci a pro případ odhalení nejsou data zasílána přímo útočníkům, ale cestují přes několik proxy serverů, které slouží ke skrytí útočníků.
Zneužití informací (Information Exploitation) Po získání informací je mohou útoč- níci využít ihned, nebo je pouze archivují pro vlastní potřebu. Pokud zjištěné informace vedou ke změně priorit či cílů, může být hned zahájen další útok, který bude nyní již operovat s mnohem detailnějšími informacemi o cílovém systému. Případem informace, která je pouze archivována, může být průmyslová, či politická špionáž, která nemá okamžité uplatnění, ale až v budoucnosti, po provedení určité akce (uvedení produktu na trh, válka).
Současné způsoby obrany
Jak již bylo zmíněno, je obrana proti APT útokům značně komplikovaná a organizace nejsou na tento typ útoků připraveny, což je výsledkem velkého počtu úspěšných útoků v poslední době. K bezpečnosti v oblasti IT se příliš dlouhou dobu přistupovalo velmi benevoletně a finanční prostředky vynakládané na zajištění bezpečnosti byly směšné v porovnání s prostředky vynakládanými na rozvoj software. Až kolem roku 2005 dochází ke zlomu, kdy se začaly organizace, v důsledku nárustu kyberkriminality, více zajímat o bezpečnost a více do ní investovat. V roce 2010 mělo 86% obětí kyberůtoků k dispozici důkazy o napadení, přesto pouze 61% z nich odhalilo kompromitaci vlastním přičiněním, zatímco ostatní byly upozorněny třetí stranou.
Vzhledem k tomu, že dnes existuje obrovské množství malware, a v APT útocích jsou navíc často používány zcela nové a na míru vyrobené programy, je detekce APT útoku velmi obtížná. Navíc vzhledem k dlouhé době trvání odhalení APT útoků je pravděpodobné, že nyní detekované způsoby jsou již zastaralé a útočníci využijí zkušeností z úspěšných útoků pro tvorbu nových, sofistikovanějších a ještě hůře detekovatelných postupů. V současné době nedochází k žádným speciálním akcím, kterými by organizace předchá- zely, nebo se bránily, APT útokům. Pro prevenci před těmito útoky jsou využity konvenční způsoby obrany, které zřídka bývají doplněny o určité heuristiky pro odhalování nových způsobů útoku nebo o nějakou formu umělé inteligence.
Jako první bývají nasazovány antivirové programy pro rozpoznávání nevyžádaných programů na jednotlivých počítačích. Tyto programy jsou schopny dobře rozpoznat známý malware a často nabízejí i doprovodné funkce pro předcházení kompromitace systému, jako je skenování souborů v sandboxovaném prostředí při stahování, varování uživatelů při pří- stupu na známé podvodné stránky a hlídání bezpečnostních aktualizací pro nainstalované programy. Mohou se snažit detekovat nové hrozby podle sledování chování procesů a sdílení veškerých poznatků v komunitě uživatelů.
Základní síťovou bezpečnost zajišťuje rozdělení sítě do logických celků a hlídání perimetru pomocí firewallu. Firewallů existuje více typů, jak hardwarové, tak i softwarové a jejich úkolem je podle nastavených pravidel povolit či zahodit síťovou komunikaci. Dříve jednoduché bezestavové systémy mohou dnes být dynamicky konfigurovány, udržují si svůj stav a dovolují relativně komplexní nastavení pravidel.
Pro monitorování síťového provozu se většinou používají systémy IDS (Intrusion Detection System) a IPS (Intrusion Prevention System). Tyto systémy analyzují události a hledají v nich hrozby porušující nastavené bezpečnostní politiky. Zatímco systémy IDS jsou pasivní a případné porušení pouze hlásí pověřeným osobám, IPS systémy umožňují na nalezené hrozby automaticky reagovat např. nastavením nových pravidel firewallu. Tyto systémy se většinou nasazují na sledování síťového provozu (tzv. network-based), mohou však být nasazeny na stanicích (tzv. host-based) a sledovat tak události nastávající na dané stanici, jako je například vytížení procesoru RAM.
IDS a IPS systémy většinou fungují na principu hloubkové analýzy paketů a popisu pravidel - signatur, podle kterých odhalují hrozby podobně, jako antivirové programy. Mohou být schopny detekovat přenášené soubory a odhalovat náhodné útoky na přihlašovací údaje (např. podle přihlašovacího jména guest, které bývá u méně sofistikovaných útoků často zkoušeno). Tyto systémy jsou relativně jednoduché na vytvoření a výkonné, ale trpí již dříve popsanými problémy s detekcí nových typů útoků, pro které zatím nebyly vytvořeny signatury.
Signatury. Jiným typem IDS a IPS systémů jsou ty, které využívají principů behaviorální analýzy a snaží se tak rozpoznat útočníka od legitimního uživatele podle anomálií v chování. Většina systémů hledá tyto anomálie v síťovém toku, ale dají se sledovat i anomálie dat obsažených v hlavičkách paketů. Do tohoto typu systémů spadají i systémy založené na stavové analýze protokolů, která používá modely chování jednotlivých protokolů specifikovaných tvůrci těchto protokolů a hlásí události v případě použití protokolu jiným způsobem. Velkým problémem IDS systémů fungujících na principu behaviorální analýzy je velké množství tzv. false positives, tedy upozornění na podezřelou aktivitu, která je však zcela nezávadná.
Vzhledem k velkému množství zdrojů bezpečnostních informací, jako jsou různé logy (systémové, aplikační) rozličných hlášení z firewallů a IDS/IPS, se ukázalo nezbytné zavést systém, který by je dokázal shromažďovat na jednom místě, agregovat a umožnit bezpečnostním analytikům zjednodušený pohled na celou síť. Takovým systémem je Security Information and Event Management (SIEM), který vznikl spojením Security Event Managementu (SEM), který se staral o shromažďování logů a jejich analýzu a Security Information Managementu (SIM), který analyzoval trendy a poskytoval analytikům vyšší abstrakci. Shromažďováním těchto informací na jednom místě a jejich korelací se dají rozpoznat vzory, které se odlišují od běžného provozu a tak rychle identifikovat, analyzovat a reagovat na bezpečnostní incidenty. Přestože v teorii by měly být tyto systémy schopny detekovat hrozby téměř v reálném čase i v rozsáhlých sítích, v praxi to selhává kvůli velkému množství dat, se kterými musí pracovat. Navíc tyto systémy nedetekují útoky, které se maskují v běžném provozu a nejsou tedy zachyceny žádnou sondou a proto se neobjeví v logu.
Návrh systému pro rozpoznání APT útoku
V rámci této kapitoly je navržen systém, který je po implementaci v cílovém prostředí schopen detekovat pokročilé ICT útoky včetně APT útoků. Nejprve je třeba identifikovat symptomy, které provází APT útoky, abychom byli schopni rozhodnout, které oblasti je třeba sledovat a pomocí čeho lze detekovat, jestli se organizace nachází pod APT útokem. Symptomem se v práci rozumí příznak či průvodní jev obtížně pozorovatelného děje, stavu nebo procesu, který slouží k rozpoznání útoku. U každého nalezeného symptomu je dále rozebráno, jak jej lze detekovat a nakonec je navržen obecný systém, který na základě sledování symptomů určí, zda se organizace nachází pod APT útokem.
Identifikace symptomů APT útoku
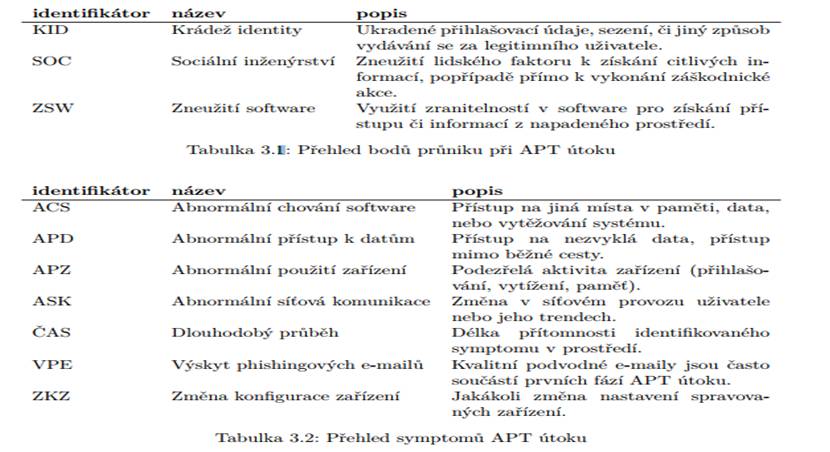
Na obrázku 3.1 je ilustrativně vyobrazeno typické prostředí organizace, ve kterém hrozí APT útok, s bezpečnostními aktivy, které se v daném prostředí vyskytují. Modrá kolečka identifikují body průniku, které jsou dále přiblíženy v tabulce 3.1, červená pak znázorňují výskyt symptomů, podle kterých lze rozpoznat APT útok. Přehled symptomů je pak uveden v tabulce 3.2. V následujícím odstavci je popsán obrázek z pohledu bezpečnostních aktiv na něm uvedených.
Vlevo na obrázku 3.1 je uvedena ikona oblaku, která symbolizuje vnější síť, ke které je organizace připojena. Kromě fyzického připojení firewallu lze pozorovat virtuální VPN spojení, které směřuje přímo do vnitřní sítě. Toto VPN spojení je podstatné, protože obchází firewall, kterým proteče jako šifrovaný kanál a v poslední době bývají VPN připojení velmi častým bodem průniku APT útoků. Pro zobrazení demilitarizované zóny (DMZ) byl zvolen třícestný firewall kvůli jednoduchosti jeho znázornění, přestože v praxi je DMZ obvykle řešena pomocí dvou firewallů. V DMZ je umístěn poštovní server, který reprezentuje různé servery nacházející se v DMZ. Velmi často využívají útočníci pro získání přístupu do sítě spear phishing, který přes tento server proudí, a pokud se útočníkům podaří kompromitovat poštovní server, mohou číst nešifrovanou firemní komunikaci. Směrem do vnitřní sítě je umístěn switch, který reprezentuje síťové prvky a na který směřuje VPN, která je tím zavedena přímo do vnitřní sítě.
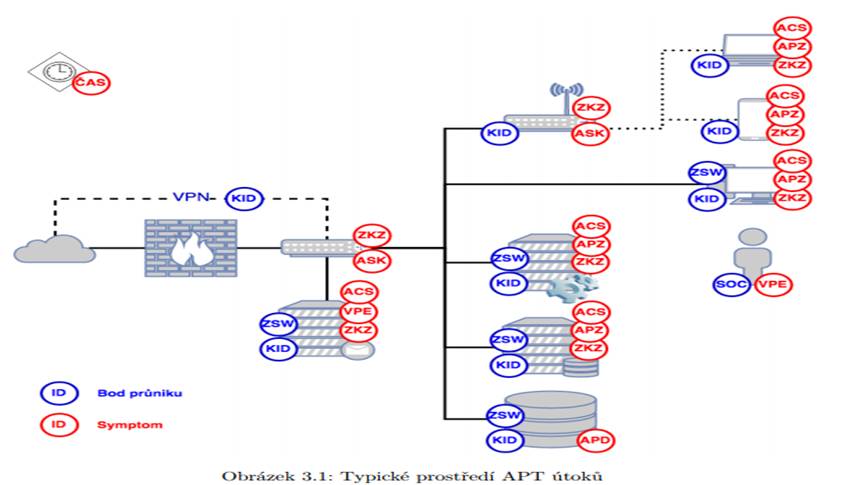
Do switche jsou pak zapojena další zařízení nacházející se ve vnitřní síti. Nahoře na obrázku je znázorněn bezdrátový přístupový bod (AP), pod ním běžná pracovní stanice, aplikační server, databázový server a datové úložiště. AP jsou důle-žitá místa v síti, protože umožňují bezdrátový přístup do vnitřní sítě, který mohou útočníci zneužít. Významným problémem jsou v podnikových sítích zejména nepovolené AP, které si uživatelé nainstalují sami bez vědomí síťového administrátora. Aplikační servery obsahují většinou podpůrné nástroje pro fungování organizace. Jejich napadením může útočník získat přístup k datům se kterými aplikace pracuje a také může sabotovat organizaci pomocí odepření služeb daného serveru, nebo dezinformacemi které danou aplikací šíří. Databázový server se stará o správu veškerých dat a jeho napadením získá útočník moc nad všemi daty, která jsou obsažena v celé databázi. Přímým přístupem do úložiště dat získá útočník veš- kerá surová data organizace, některá data je ale nutné správně interpretovat, což nemusí být triviální (např. datové soubory databází, vnitřní soubory aplikací). V nejpravějším sloupci jsou zobrazena zařízení, se kterými přímo pracuje uživatel, který je reprezentován ikonou nejníže. Uživatel sám o sobě může být jak terčem útoku (např. již zmíněný phishing nebo sociální inženýrství), tak i zdrojem útoku. Nezanedbatelná část útoků je vedena z vnitřní sítě pomocí zaměstnanců, kteří vědomě z osobních důvodů, např. kvůli vydírání či finanční odměně, kompromitují systémy a data zaměstnavatele. S uživatelem je spojena pevná pracovní stanice, mobilní zařízení a přenosný počítač, které jsou na obrázku znázorněny nad ikonou uživatele. S pevnou pracovní stanicí uživatel v kanceláři pracuje nejčastěji, tato stanice je zpravidla pod správou IT oddělení organizace, přesto může být napadena a využita pro potřeby útočníka. Přenosná zařízení představují vyšší formu rizika, jelikož jsou často pod správou jednotlivých uživatelů a mohou být snáze odcizena. Při odcizení či zneužití mobilního telefonu získá útočník relativně málo hodnotných údajů, může však zneužít zařízení pro ukradení identity uživatele a přihlášení se do podnikové sítě. U přenosných počítačů je rizikem kromě krádeže identity i krádež dat na daném zařízení, opět však platí, že není tolik důležitá jako krádež identity. Pokud útočník získá přenosný počítač s důvěrnými daty, jedná se většinou o několik málo dokumentů, jejichž zcizení může pro organizaci představovat citelnou finanční ztrátu, krádež identity ale může útočníka oprávnit ke všem důvěrným datům v organizaci, což je likvidační.
V dalších sekcích jsou blíže popsány jednotlivé symptomy, které indikují, že je organizace pod APT útokem.
Abnormální chování software
Pro získání přístupu do prostředí mohou být využity známé, ale i dosud neobjevené (takzvané zero-day) zranitelnosti v software, a to jak v aplikačním, tak i v serverovém software, či dokonce v nějaké součásti operačního systému. Nejčastěji dochází k napadení pomocí speciálního uživatelského vstupu, který není řádně ošetřen. Útočník pak může software využít například pro eskalaci svých práv a k získání kontroly nad cílovým zařízením. Kromě využití zranitelností pro přímý průnik lze zneužít software také ke sběru informací, kdy je útočník schopen přinutit software, aby mu zpřístupnil informace, na které nemá právo, nebo jej může dokonce útočník modifikovat tak, aby tyto informace sám sbíral a útočníkovi předal (například sledování bankovních údajů zadávaných ve webovém prohlížeči). Pokud se útočníkovi podaří upravit aplikaci tak, aby příjmala příkazy, které jí nějakým způsobem doručí, zajistí si útočník trvalý přístup k cílovému zařízení a může jej použít pro další průniky.
Abnormální přístup k datům
V dnešním informačním světě představují firemní data hodnotu, a proto se stávají terčem APT útoků téměř vždy. APT útoky jejichž cílem není krádež citlivých dat jsou spíše vý- jimkou. Získání citlivých údajů poskytuje útočníkovi kromě kompetitivní výhody také nové informace o cíli, které umožňují přesnější postup při dalším pokračování útoku. Vzhledem k důležitosti dat je nutné věnovat vyšší úsilí kontrole přístupu k nim a detekovat nejen pokusy o přístup k tajným datům, ale kontrolovat veškeré operace s těmito daty. Je důležité od sebe oddělit tajná data od dat veřejných a to jak logicky, tak i fyzicky. Tajná data by neměla nikdy opustit vnitřní síť organizace.
Abnormální použití zařízení
Po získání přístupu k zařízení na něm útočník zpravidla provádí operace odlišné od běžného chování uživatele. Velmi často se útočník pokouší převzít kontrolu nad zařízením, aby získal přístup ke všem informacím dostupným na daném zařízení a dalších zařízení, které napadenému zařízení důvěřují. Proto se na zařízení objevují pokusy o eskalaci práv, kterého je zpravidla dosaženo zneužitím zranitelnosti v software, jak bylo zmíněno výše. Abnormální použití zařízení lze rozpoznat změnami v přihlašování uživatele. Útočník nepřistupuje k zařízení stejným způsobem a lze tedy detekovat vzdálené přihlašování z neobvyklých adres, nebo dvojí přihlášení uživatele - lokálně a vzdáleně. Kromě způsobu přihlašování lze také pozorovat změny v době přihlášení, pokud je zařízení aktivní mimo standardní časový rámec, lze indikovat pravděpodobné napadení zařízení. Pokročilé APT útoky se však snaží skrýt své aktivity v běžném provozu zařízení a nezpůsobují tak výrazné změny, jako je připojení k zařízení v nestandardní době. Přes to však lze detekovat více menších symptomů, včetně vyššího vytížení zařízení, zaplňování paměti nebo zaplňování pevného disku.
Abnormální síťová komunikace
Naprostá většina útoků využívá toho, že jsou dnes počítače propojeny internetovou sítí. Ta poskytuje útočníkům způsob, jak vynést informace z napadené organizace a také, jak vzdá- leně útok řídit. Po prvotní kompromitaci systému je většinou instalován v cílovém prostředí software umožňující vzdálené ovládání a tento software se přihlásí do útočníkovy řídící sítě. V poslední době také často dochází ke zneužití stávající VPN linky organizace, což umožní útočníkům nerušený a šifrovaný přístup do vnitřní sítě. Útočník z počátku často nezná strukturu sítě v prostředí a tak je nucen ji nějakým způsobem odhalit, což se často skládá z různého skenování sítě. Skenování portů jako takové je pro APT útoky méně časté, jelikož je velice snadno odhalitelné. Pokud je však rozloženo v dostatečném časovém rozpětí, může klasické detekci uniknout. Protože je u APT útoků kladen velký důraz na skrytí všech aktivit, je obvykle komunikace s řídící sítí útočníka šifrovaná a odesílání nasbíraných dat probíhá po malých částech během delšího období, čímž se skryje v normální komunikaci. Je tedy zřejmé, že sledování síťového provozu a jeho analyzování je zásadní a nedílnou součástní jakéhokoli systému, který se zabývá detekcí moderních útoků v ICT prostředí.
Dlouhodobý průběh
Již v názvu APT je zmíněna perzistence a v kapitole 2.1 je popsáno, že se tyto útoky vyznačují dlouhou dobou trvání. Přes to, že se rozhodně jedná o určující prvek APT útoku, není samostatně měřitelný. Dlouhodobou povahu útoku lze detekovat pouze zpětně a je měřena pomocí ostatních symptomů. Pokud tedy výskyt symptomů indikuje podezření na APT útok, lze až zpětně pomocí analýzy zjistit délku trvání daného symptomu a podle ní indikovat, že se s pravděpodobností jedná o APT útok. Dlouhodobý průběh tedy můžeme chápat nikoli jako samostatný symptom APT útoku, ale jako charakteristiku u ostatních symptomů.
Výskyt phishingových e-mailů
Přesto, že podvodné e-maily nejsou specifikem pouze APT útoků a jsou jimi dnes zahlceny téměř všechny e-mailové schránky, velice se liší v důmyslnosti a zůstávají nejčastěji využívaným bodem pro průnik do cílového prostředí. Pokročilé útoky stylu APT používají velice kvalitně vypadající podvodné e-maily, které jsou téměř nerozpoznatelné od regulérní pošty. Tento typ podvodných e-mailů se nazývá spear phishing a útočník pro jejich vytvoření používá často detailní informace o napadeném prostředí a uživateli. Tato pošta pak snadno projde automatickými filtry a uživatel, který nepozná rozdíl od podnikové pošty, může nevědomky nainstalovat malware, nebo je přesměrován na podvodný web, který útočník nastražil.
Změna konfigurace zařízení
V podnikovém prostředí bývají zařízení pod správou IT oddělení, v poslední době se však rozmáhá princip BYOD (Bring Your Own Device). U zařízení, které spravuje IT oddělení, se předpokládá stabilní konfigurace, která se nemění. Jakákoli změna, jako je například instalace nového programu nebo otevření portu, indikuje narušení bezpečnosti. U pracovních stanic se může jednat o běžný virus, ale pokud se změní konfigurace síťových prvků, dá se předpokládat pokročilejší útok.
Po napadení zařízení často útočník instaluje backdoor, který mu umožní vzdálený pří- stup k systému, nebo modifikuje stávající aplikaci, aby plnila tento účel. Tyto změny se mohou projevit nasloucháním na novém síťovém portu, nebo přesměrováním běžné komunikace. Kromě pasivního čekání na pokyny dochází u těchto typů malware ke kontaktování útočníka a předání informace o úspěšné kompromitaci systému. Útočník však nemusí napadené zařízení kompromitovat pouze kvůli přístupu do sítě. Napadené zařízení může také pro útočníka po kompromitaci autonomně sbírat informace. Například má-li napadené zařízení vhodnou síťovou kartu, může sledovat veškerý provoz proudící přes ni i pokud není určen pro dané zařízení. V případě bezdrátové sítě se pak jedná o veškerý provoz v okolí. Jiným příkladem je sbírání informací z okolí napadeného zařízení pomocí jeho senzorů, jako je mikrofon, kamera nebo i GPS.
Kromě softwarové změny konfigurace je možná i změna konfigurace HW. Útočník může oběti nainstalovat přídavný hardware, nebo nahradit stávající tak, aby nepozorovaně plnil i jinou funkci. Nejznámějším využitím změny HW konfigurace je instalace keyloggeru, který zaznamenává veškeré stisky klávesnice a útočník je schopen pomocí něj zjistit hesla a jiné citlivé údaje o oběti.
Možnosti detekce jednotlivých symptomů
Jak vyplývá z kapitoly 2 je detekce APT útoků značně komplexní problém vzhledem k tomu, že jsou APT útoky vedeny profesionálně odborníky a s důrazem na skrývání svých aktivit. Přes to, že APT útoky lze teoreticky detekovat stejnými způsoby jako jakékoli jiné ICT útoky, profesionálně vedené APT útoky často zůstávají pod rozlišovacími schopnostmi stávajících bezpečnostních řešení. APT útoky nelze detekovat jednoduchým systémem či za- řízením, které by stačilo přidat do stávajícího systému v organizaci (jako např. IDS), pro umožnění detekce tohoto typu útoků je nutné zahrnout bezpečnost již do návrhu struktury systémů organizace. Pro identifikaci kritických míst je vhodné použít analýzu rizik, jejímž výstupem je seřazení zkoumaných prvků (aktiv) podle kritičnosti a pravděpodobnosti, že se útočník zaměří právě na toto místo. Návrh struktury s oddělením kritických prvků od méně kritických umožňuje zaměřit se při obraně na důležitá místa a neplýtvat energií a financemi jinde.
Mnoho symptomů sleduje abnormality v použití jednotlivých elementů, ať už se jedná o software, data nebo komunikaci. Sledování těchto informací lze abstrahovat do sledování množiny trojic použití, kde trojice použití je definována jako [Subjekt, Metoda, Objekt]. Subjekt je ta entita, která provádí nějakou akci s objektem a metoda pak popisuje způsob a typ prováděné akce. V případě přístupu k datům pak může být subjektem uživatel, popří- padě proces vyžadující data, metodou je pak volání nějakého rozhraní, nebo přímý přístup a objektem jsou ovlivněná data. V následujících sekcích jsou přiblíženy způsoby detekce jednotlivých symptomů.
Abnormální chování software
Pro sledování chování software jsou používány antivirové programy. Tyto programy prochází soubory přítomné na počítači a ověřují podle signatur, nejedná-li se o známý škodlivý software. V tomto základním pojetí jsou tyto programy schopny detekovat pouze ten malware, který je již znám a je pro něj vytvořena signatura a nejsou schopny odhalit nové hrozby a modifikaci či zneužití software. Pokročilejší antivirové programy jsou schopny detekovat podezřelé chování i podle pří- stupů aplikace k některým funkcím operačního systému nebo zdrojům, které nejsou běžně používány. Díky tomu jsou schopny rozpoznat i některé hrozby, pro které zatím není vytvo- řena signatura, pokud je jejich chování při těchto přístupech dostatečně podobné známému vzorci.
Pro detekci změn v software lze využít techniku podepisování, kdy je pro aplikaci spočten její otisk pomocí nějaké hashovací funkce a tento otisk je pak zašifrován soukromým klíčem vydavatele. Pomocí tohoto otisku pak lze detekovat nejen změny v software, protože dojde ke změně otisku, ale pokud máme ověřený veřejný klíč vydavatele, lze ověřit, že nainstalovaný software nebyl dodatečně modifikován. Toto ověřování je rozšířeno zejména u mobilních aplikací a Linuxových repozitářů, u aplikací pro Windows dochází k podepisování důležitých součástí systému, jako jsou ovladače, také. Problémem stále zůstává bezpečná distribuce veřejných klíčů vydavatelů, která bývá řešena pomocí centralizované správy software, jako jsou Linuxové repozitáře, Google Play store a úložiště ovladačů pro Windows. Pokud je software spravován centrálně, lze jej podepsat pomocí jednotného klíče a uživateli pak stačí mít k dispozici pouze jeden veřejný klíč.
Uzavírání aplikací do kontrolovaného prostředí, tzv. sandboxing, umožňuje kromě omezení přístupu aplikace také detekovat změny v chování. Aplikace je uzavřena ve svém prostředí, kde má přístup k datům a prostředkům, které potřebuje pro svůj běh, a všechny ostatní prostředky jsou jí skryty. Pokud detekujeme pokus aplikace přistoupit k datům mimo toto prostředí, je zde podezření, že byla napadena, protože při standardním použití by k podobným událostem nemělo docházet.
Abnormální přístup k datům
Pro detekci abnormalit přístupu k datům je nutné sledovat veškeré pokusy o načtení dat i jejich změny. Pro sledování těchto údajů však nestačí ukládat si informace v obslužném software, ale je potřeba součinnost operačního systému, který data spravuje. To z toho důvodu, že útočník může kromě přístupu pomocí standardních rozhraní využít i přímého přístupu k datům a zcela tak obejít obslužný software.
Protože sledování všech přístupů k datům je náročné, je potřeba data kategorizovat a oddělit od sebe citlivá data od těch, jejichž případný únik by neznamenal vážné bezpečnostní riziko. Kromě logického oddělení dat podle míry tajnosti je vhodné oddělit tato data i fyzicky. To umožňuje lepší správu přístupu k tajným datům a nasazení jiných politik pro přístupový systém. Pokud budou tajná data přístupná pouze přes dedikovaný přístupový server, je snažší nasadit na tento server bezpečný systém, který bude uchovávat větší množství informací o veškerých přístupech. Naproti tomu data, která jsou veřejná, budou umístěna na jiném zařízení, které nebude zbytečně zatíženo sbíráním informací o přístupu. Neoprávněné pokusy o přístup na tajná data jsou jednoznačným varováním, že by se mohlo jednat o útok.Kromě zamítnutých přístupů lze také sledovat způsob přístupu na data, jelikož útočníci se mohou často pokusit obejít standartní rozhraní ve snaze vyhnout se obranným mechanismům. Měla by tedy být kontrolována i integrita dat a ověřováno nejen kdo na data přistupuje, ale i jakým způsobem. Také lze detekovat, ke kterým datům uživatel přistupuje a sledovat, jestli se jeho chování nezmění a nezačne číst i data, která standartně nepotřebuje. Dobrou praktikou je povolit uživateli přístup pouze na ta data, která reálně potřebuje ke své činnosti.
Abnormální použití zařízení
Pro sledování používání zařízení je nutné uchovávat provozní informace o využití zařízení. Pro získávání těchto informací je nutná plná podpora operačního systému, který musí generovat auditní události. V Unixovém prostředí probíhá toto nastavení přes auditního démona auditd, v prostředí MS Windows je pak toto nastavení součástí služeb operačního systému pod názvem Security Auditing.
Mezi vhodné události, které by měl audit sledovat, patří přihlašování uživatelů. To umožní identifikovat přihlášení nestandartního uživatele, jako je například nepoužívaný účet guest, přihlášení nestandartním způsobem, což může být například vzdálené přihlášení k pracovní stanici, ke které se uživatel vždy přihlašuje lokálně, nebo přihlášení v nestandardní době. Jiným vhodným ukazatelem jsou běžící procesy a jejich nároky na RAM a vytížení CPU, které odhalí, zdali nedošlo ke spouštění neznámých procesů nebo nedošlo ke kompromitaci stávajících. Audit operačního systému umožňuje generovat i události související s prací se soubory a lze tedy detekovat vytváření, modifikace i čtení souborů. Pomocí sběru a sledování těchto dat lze vytvořit model popisující běžnou činnost zaří- zení, který může být pak použit pro porovnávání s aktuálním stavem a rozhodnutí, zdali je aktuální použití zařízení normální či nikoli.
Abnormální síťová komunikace
K detekci abnormální síťové komunikace lze přistoupit ze dvou zcela odlišných směrů. Prvním je sledování jednotlivých komunikačních toků a detekce podezřelého obsahu komunikace (například pokus o navázání spojení na neexistující uzel). Druhým přístupem je sledování chování jednotlivých účastníků, jejich komunikačních partnerů a vzorů chování a detekování podezřelého chování. Běžné firewally a IDS/IPS systémy používají první způsob. Firewally sledují, kdo se snaží komunikovat a jaký kanál (port) pro to chce využít a na základě sady pravidel rozhoduje zda je komunikace povolená, či nikoli. IDS/IPS systémy často fungují na principu hloubkové analýzy paketů, kdy se snaží zjistit obsah komunikace a reagují na takový obsah, který mají označen jako nežádoucí. Tyto systémy jsou schopny velmi efektivně rozpoznávat známé typy útoků podle komunikačních partnerů (skenování portů, přístupy na neaktivní adresy) nebo podle známého obsahu nebezpečných paketů. Nejsou však schopny rozpoznat novátorské přístupy a skrytí před těmito systémy nepředstavuje pro zkušeného útočníka příliš velký problém.
Druhým způsobem lze odhalit útočníka podle chování, které nějakým způsobem vybo- čuje z normálního vzoru komunikace. Sledujeme-li chování jednoho uživatele v síti a jsme-li schopni vysledovat vzory v jeho komunikaci, lze rozeznávat změny v těchto vzorech nebo detekovat podezřelé aktivity podle známých vzorů chování. Systémy založené na detekci chování jsou teoreticky schopny odhalit i zcela nové a zatím neznámé útoky a skrytí před nimi je složité. Proto je tento způsob detekce vhodnější pro APT útoky. Chceme-li sledovat chování uživatele v síti pro detekci APT útoků, je nutné analyzovat veškerou jeho komunikaci. Pokud sledujeme chování uživatelů, stačí nám analyzovat odchozí komunikaci, podle ní totiž jsme schopni pozorovat akce uživatele, příchozí zprávy jsou většinou pouze reakcí na ty odchozí. Útočníci mohou sice zasílat do sítě příkazy nainstalovanému malware, což je příchozí komunikace, ale tyto příkazy se jen velmi těžko detekují a navíc pokročilý malware používaný při APT útocích může pracovat do značné míry autonomně, bez nutnosti příchozí komunikace. Nejsnadněji lze odhalit odchozí komunikaci po infikaci, kdy se malware přihlašuje do řídící sítě a nebo když malware odesílá útočníkům nasbíraná data.
Útočník však také může obranné mechanismy postupem času naučit komunikaci mezi řídící sítí a malware považovat za normální, pokud dostatečně pomalu rozšiřuje normální chování uživatele o svou komunikaci tak, aby zůstal pod rozlišovací schopností detekčního mechanismu. Proto je vhodné kromě změn v chování na síti sledovat také dlouhodobější trendy například porovnáním aktuálního normálního chování uživatele s tím, jaké bylo před měsícem, či rokem.
Výskyt phishingových e-mailů
Odhalování spear phishingových e-mailů je velmi náročný až téměř nemožný úkol vzhledem k důmyslnosti, se kterou jsou vytvořeny. Standardní součástí každého e-mailového serveru by měl být antiphishingový filtr. Tyto filtry jsou nejčastěji založeny na metodách strojového učení a rozpoznávají podvodné e-maily podle jejich struktury, zpracování přirozeného jazyka, kontrolou zpětného DNS záznamu zdrojového serveru a vznikají i protokoly pro ověřování autentičnosti e-mailů.
Pro napadení zařízení bývají v podvodných e-mailech nejčastěji využívány infikované přílohy, alternativně se útočníci snaží uživatele pomocí falešného odkazu přinutit navštívit podvrženou webovou stránku a malware si nevědomky nainstalovat. Malware připojený k e-mailu má zřídka formu spustitelného souboru, který bývá téměř vždy odhalen, ale častěji dochází k infikování ZIP či RAR archivu nebo souborů běžně používaných v organizaci (jako jsou tabulky v programu Excel nebo PDF soubory). Mnoho antivirů umožňuje prozkoumat přílohy e-mailů a pokusit se detekovat přítomný malware.
Protože však spear phishingové e-maily často díky své důmyslnosti překonají antiphishingové filtry, nezbývá než upozornit na tato rizika uživatele a před otevřením příloh podezřelých e-mailů vždy ověřovat nezávisle jejich autentičnost a na případné nesrovnalosti upozornit. Pokud se v organizaci vyskytnou kvalitní spear phishingové e-maily, které obsahují firemní informace, je riziko, že se organizace nachází pod APT útokem, velmi vysoké. Pokud se však podaří odhalit APT útok díky detekci phishingových e-mailů, došlo tak v prvních fázích útoku a útok tedy zatím pravděpodobně nezpůsobil velké ztráty.
Změna konfigurace zařízení
Pro sledování změn konfigurace zařízení je nutné vytvořit systém, který bude sledovat vybrané konfigurace a upozorní na jejich změnu. V případě zařízení firmy Cisco s operačním systémem IOS stačí sledovat dva konfigurační soubory - startup-config a running-config. U počítačů je ale situace komplikovanější, vzhledem k jejich komplexitě totiž neexistuje jednotný konfigurační soubor. Je tedy nutné pomocí nějakého nástroje sledovat důležitá konfigurační nastavení a ověřovat, jestli nedošlo v běžícím systému k dynamické změně konfigurace. Pro sledování integrity systému lze také použít TPM čip (Trusted Platform Module). Tento čip byl vyvinut jako bezpečnostní modul pro počítače a jednou z jeho funkcí může být i sledování, zda nedošlo k porušení integrity operačního systému. Na základě podpisů jednotlivých konfiguračních souborů a hardwarové konfigurace by tento čip měl být schopen detekovat neoprávněné změny.
Návrh architektury systému pro detekci útoků
V předchozí kapitole byly navrženy způsoby detekování jednotlivých symptomů. Pokud chceme na základě těchto symptomů usuzovat, zdali je organizace pod APT útokem, je nutné zpracovat informace z detektorů jednotlivých symptomů a pomocí vhodné agregace detekovaných hodnot rozhodnout, s jakou mírou indikují symptomy, že se organizace nachází pod APT útokem.
Jednotlivé detektory ale nepracují s jednotnou metrikou, transformací jejich výstupů na společnou metriku definující míru pravděpodobnosti napadení bychom ztratili příliš mnoho informací, což by se negativně projevilo na citlivosti celého systému. Například detekce abnormálního přístupu na data by mohla využívat jako metriku vektor popisující citlivost dat, které byly tímto ovlivněny, na stupnici o třech úrovních - tajná, podniková a veřejná data a míru abnormality přístupu k nim. Pokud bychom chtěli tyto informace převést na skalární hodnotu udávající míru napadení, došlo by ke ztrátě informace, která by v kombinaci s jiným symptomem (například detekování abnormální síťové komunikace a odesílání většího objemu dat) mohla být významná. Proto je nutné zpracovávat výstupy jednotlivých detektorů v rámci jejich vlastních metrik.
Na základě informací naměřených na jednotlivých detektorech lze pak pomocí nastavených pravidel vhodného interferenčního mechanismu rozhodnout, zda se organizace pravděpodobně nachází pod APT útokem, či nikoli. Vzhledem k povaze jednotlivých symptomů a mírám nejistoty při jejich kombinacích je nutné využít fuzzy logiku. Pro vytváření pravidel interferenčního mechanismu je nutné vzít v úvahu fakt, že závaž- nost jednotlivých symptomů je závislá nejen na výstupu detektoru, ale i na jeho umístění. Pokud je hlášena změna konfigurace u kancelářského počítače, nejedná se o natolik významnou událost, jako když je stejná změna detekována v konfiguraci klíčového síťového prvku. Proto je nutné jednotlivá aktiva na kterých probíhá detekce hierarchicky kategorizovat a reflektovat toto v navrhovaných pravidlech.
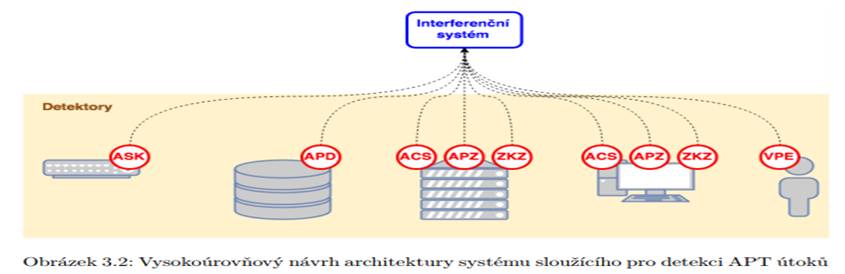
Na obrázku 3.2 je zobrazena architektura navrhovaného systému, který sestává z mno- žiny detektorů a interferenčního mechanismu. Architektura zahrnuje:
∙ detektor ASK (abnormální síťová komunikace),
∙ detektor APD (abnormální přístup k datům),
∙ detektor ACS (abnormální chování software),
∙ detektor APZ (abnormální použití zařízení),
∙ detektor ZKZ (změna konfigurace zařízení),
∙ detekce VPE (výskyt phishingových e-mailů),
které jsou vzájemně provázány interferenčním systémem. Interferenční systém na zá- kladě informací z detektorů pomocí fuzzy logiky rozhoduje, zda došlo k APT útoku. Podle zadání diplomové práce je dále detailněji rozebrán a navržen detektor symptomu „abnormální síťová komunikace“, jako demonstrace tvorby jednotlivých detektorů.
Detekce abnormalit v síťové komunikaci
Jak je uvedeno v kapitole 3.1.4, je sledování síťové komunikaci nutné, chceme-li odhalit moderní útoky na ICT systémy. Z kapitoly 3.2.4 pak dále vyplývá, že pro detekci APT útoků je nevhodnější použít analýzu chování uživatelů v síti. Tato kapitola se zabývá návrhem, implementací a otestováním detektoru abnormalit v síťové komunikaci. Nejprve je popsána analýza chování se zaměřením na síťové prostředí a její aktuální využívání v praxi. Následuje návrh koncepce detektoru, ve kterém je definováno, jakým způsobem lze sledovat síťovou komunikaci, které údaje z ní je třeba sledovat a jsou zde specifikovány vlastnosti, které má mít navrhovaný detektor. Další kapitola se zabývá návrhem samotného detektoru a jeho částí, je zde detailně popsána struktura detektoru včetně modelu, který detektor využívá pro rozpoznání normálního chování uživatele. Kapitola 4.4 obsahuje bližší informace o implementování základních součástí navrhovaného detektoru a poslední kapitola pak popisuje, co bylo při práci s detektorem zjištěno.
Behaviorální analýza
Behaviorální analýza popisuje obecně analýzu chování určitého subjektu. V ICT bývá pozorovaným subjektem zpravidla nějaký systém, či uživatel. Pokud je sledovaným subjektem uživatel, dá se behaviorální analýza považovat za dynamický biometrický systém, který se zabývá rozpoznáním vzorů chování v čase. Diplomová práce je zaměřena na analýzu síťové komunikace, která bývá označována jako NBA (Network Behavior Analysis). NBA slouží k rozpoznávání vzorů v proudech paketů, jimiž je tvořen síťový provoz za účelem identifikace hrozeb. V zásadě existují dva přístupy, jak odhalit podezřelé chování, a to buď rozpoznáváním chování útočníka v síti podle známých způsobů chování útočníků - tzv. signature-based, nebo podle odchylek ve standardním chování sledovaného subjektu - tzv. anomaly-based.
Signature-based analýzy využívají databázi pravidel tzv. signatur, podle kterých rozpoznají přítomnost hrozby. Při sledování chování v síti tedy dochází k porovnání aktuálního provozu s databází signatur a pokud je nalezena shoda, hlásí systém možnou hrozbu. Vzorový příklad: Typicky se útočník po získání přístupu k síti snaží zmapovat služby, které zde běží pomocí skenování portů. To se vyznačuje velkým množstvím krátkých spojení, v databázi signatur tedy bude pravidlo, že pokud se na síti objeví více než x krátkých spojení v krátkém čase, je zde podezření na potenciálně nebezpečnou aktivitu skenování portů a systém zobrazí hlášení. Tento typ analýzy je v principu relativně snadný, i když signatury mohou být i značně komplexní, a výkonný. Je však limitován známými signaturami, pokud tedy útočník použije novátorský přístup, tento typ analýzy jej nezachytí. Pro vyhnutí se detekci tedy stačí útočníkovi zvolit takový způsob, který není obecně známý, nebo imituje normální komunikaci.
Anomaly-based analýzy využívají profil chování uživatele. K problému vytvoření profilu normálního chování lze přistoupit dvěma způsoby. První možností je manuálně definovat, jak se daný uživatel chová a reálné chování porovnávat s tímto stavem. Manuálně vytvořit tento normální profil je však možné v zásadě jen pro silně omezený a zjednodušený provoz. Příkladem může být nasazení anomaly-based analýzy na sledování pouze jediného protokolu v síťovém provozu. Profil normálního chování pak může být odvozen z definice protokolu a hlášení anomálií potom upozorňuje na nestandartní užití protokolu. Druhou možností je rozdělení funkce systému na dvě fáze - v první fázi se nic nedetekuje a systém se pouze učí jak vypadá normální komunikace a tvoří si její profil, v druhé fázi pak porovnává aktuální provoz s profilem a pokud se výrazněji odlišuje, upozorní na možnou hrozbu.
Systémy většinou fungují tak, že sledují určité charakteristiky a pomocí statistických metod je porovnávají s nastaveným prahem. Mezi vhodné charakteristiky patří například množství přenesených dat v rámci jednoho spojení nebo počty komunikačních partnerů. Příkladem jiné charakteristiky může být podíl webových služeb na síťovém provozu. Pokud je standardně 13% a běžně se liší až o 10%, ale během sledování najednou dosahuje 40%, varuje systém před podezřelou aktivitou. Vzhledem k tomu, že anomaly-based analýzy neznají chování při specifických typech útoků, je varování vždy obecné a nemohou pojmenovat typ podezřelého chování, na rozdíl od signature-based, které mohou pojmenovat chování podle signatury, která mu odpovídá (například zmíněné skenování portů). Anomaly-based systémy jsou vhodné i pro dosud neznámé typy útoků a vyhnutí se detekci je velice obtížné a nutí útočníka sledovat bežnou komunikaci a skrývat v ní své akce velmi složitým způsobem. Problémem tohoto způsobu je ale velké množství hlášení v případech nízkého prahu a při vysokém prahu zase naopak příliš velká tolerance, což dává útočníkovi prostor ke skrytí své aktivity.
Analýza chování poskytuje vyšší míru abstrakce než klasické nástroje založené na hloubkovém analyzování paketů. Místo práce s velkým množstvím jednotlivých paketů pracují systémy pro analýzu chování s datovými toky (označovanými anglicky flow), což je struktura charakterizující skupinu paketů, které mezi sebou mají určitou vazbu. Většinou jsou za jeden tok považovány pakety, které mají společnou zdrojovou a cílovou IP adresu, zdrojový a cílový port a číslo protokolu. Kromě těchto informací obsahuje abstrakce datového toku také čas vzniku, délku trvání, počet přenesených paketů a bytů a může obsahovat i další údaje o daném toku.

Podle analýzy chování se dá také do jisté míry rozlišit, jaké akce uživatel zrovna provádí a to bez nutnosti analýzy dat, lze tedy detekovat akce uživatele i při použití šifrované komunikace. Podle metadat síťového toku pak můžeme například určit, jestli uživatel aktuálně prohlíží webové stránky (podle cílové IP by se teoreticky dalo zjistit i jaké), chatuje, nebo třeba odesílá soubory (pochopitelně bez analýzy dat se nedá zjistit jaké).
Velkou výhodou behaviorální analýzy je nekonfliktnost s jinými systémy, ať už bezpeč- nostními či jinými, na síti. Vzhledem k tomu, že pasivně zpracovává síťové údaje a nijak do komunikace aktivně nezasahuje, lze ji použít v libovolném produkčním prostředí. Navíc pracuje NBA jen s metadaty síťového provozu a proto ji lze využít i pro šifrovanou komunikaci. Pochopitelně použití tunelovaného spojení jako VPN nebo IPsec efektivně skryje vnitřní komunikaci a ta se pro NBA tváří jako jeden tok, to však nebrání detekci nových koncových uzlů tunelů v síti a vyhodnocení vzniku nového tunelu jako potenciální hrozby. V diplomové práci je pro detektor APT útoků v prostředí počítačové sítě zvolena anomaly-based analýza, která umožňuje zachytit i dosud neznámé typy útoků.
Aktuální využití v praxi
Behaviorální analýza se dnes používá jako doplňková služba k běžným způsobům založeným na ochraně perimetru pomocí firewallů a monitorování sítě pomocí IDS/IPS. Obvyklý způ- sob zapojení je zobrazen na obrázku 4.2, kde je síťový provoz nejprve filtrován firewallem, poté analyzován běžnými IDS/IPS a následně ještě analyzován pomocí NBA. Hlášení o potenciálních hrozbách je dále agregováno v SIEM systému.

Komerční nástroje pro zajištění bezpečnosti ve velkých korporacích již obsahují nějaké formy behaviorální analýzy a nebo nabízejí rozšiřující moduly, které tuto funkcionalitu přidávají. Nejčastěji fungují na principu rozeznávání chování útočníka v síťovém provozu, ale objevují se i systémy využívající anomaly-based analýzy. Detailní informace o fungování jednotlivých systémů jsou však kvůli zachování kompetitivní výhody nedostupné a nedá se tedy přesně říci, jakých principů jednotlivé společnosti využívají a co přesně pro detekci hrozeb využívají.
Příkladem může být společnost AdvaICT, která vyvíjela systém pro rozpoznávání útoků podle specifického chování útočníka. Toto chování bylo specifikováno množinou atributů toku spojených logickými podmínkami AND a OR, pokud se pak vyskytlo na síti podobné chování, rozhodoval se systém podle nastavitelných prahů zdali se jedná o hrozbu, či nikoli. Tato společnost byla později skoupena společností INVEA-TECH a její NBA začleněna do produktu FlowMon, který již ale nabízí i detekci hrozeb podle anomálií v chování. Jiným příkladem je McAfee Network Threat Behavior Analysis (NTBA), která je sou- částí McAfee Network Security Platform. NTBA zřejmě využívá anomaly-based behaviorální analýzu pro deketci hrozeb.
V současnosti jsou systémy využívající NBA dostupné v zásadě jen velkým společnostem a jsou považovány za nadstandardní vybavení. Vzhledem k tomu, že se jedná o technologii uvedenou do praxe relativně nedávno a zatím ne zcela spolehlivou, používá se vždy jen jako doplňek ke stávajícím technologiím založeným na signaturách a hloubkové analýze paketů. Do budoucna se však předpokládá velký vývoj technologií založených na analýze chování a zaujmutí až 80% trhu pro detekci útoků v síťovém provozu na úkor analýzy obsahu paketů. Proto se v diplomové práci zabývám vytvořením detektoru anomálií provozu v počítačových sítích, který využívá anomaly-based analýzu obdobně jako podle dostupných informací činí NTBA.
Návrh koncepce detektoru
Z předchozích kapitol vychází, že nejvhodnějším způsobem detekce tohoto typu útoků je sledování síťové aktivity a detekce odchylek v běžném provozu. Je tedy třeba definovat, jakým způsobem bude síťová aktivita sledována, jak bude vytvářen model chování v síti a na základě čeho bude rozhodováno o tom, zdali je sledovaná aktivita abnormální.
K analýze chování lze přistoupit dvěma způsoby, a to buď rozpoznáváním chování útoč- níka v síťovém provozu, nebo ve sledování normálního provozu a hlášením anomálií. Druhý přístup je ze své podstaty mnohem obecnější a pokryje tak velkou škálu hrozeb včetně těch, které zatím neznáme a neumíme popsat. Proto je mnohem vhodnější pro odhalování APT útoků které velmi často využívají všech dostupných prostředků včetně na míru sestavených řešení k dosažení cíle. Protože jedním z význačných rysů APT útoků je, že probíhají v del- ším časovém období a snaží se o minimální možnost detekce, je třeba sledovat i relativně malé odchylky v síťovém provozu. To s sebou však nese problém jak zabránit, aby systém nevykazoval příliš velké množství potenciálních hrozeb a nezahlcoval tak bezpečnostní analytiky velkým množstvím převážně false-positive hlášeními.
V NBA nástrojích bývá síťový provoz reprezentován jako množina síťových toků. Profil chování může být tvořen pro síť jako celek, výsledný profil je pak však příliš obecný a tím poskytuje prostor pro skrytí útočných aktivit. Mnohem vhodnější je vytvářet profily chování jednotlivých zařízení, jelikož chování zařízení lze modelovat mnohem přesněji. Pro rozlišení zařízení se většinou používá zdrojová IP adresa, ta však není příliš spolehlivá. Vzhledem k rozšířenosti DHCP může docházet k tomu, že stejná IP adresa bude odpovídat různým zařízením s odlišnými profily chování. Vhodnější identifikátor pro rozlišení jednotlivých zařízení je linková MAC adresa, při použití MAC adresy je však třeba mít na paměti, že při cestě v síti nezůstává konstantní a při přechodu paketů routery se mění. Pro použití MAC adresy je tedy nutné získávat síťová data ze všech segmentů sítě.
Abstrakce síťového provozu pomocí datových toků je sice vhodnější než množiny paketů, pro lepší analýzu chování by však bylo vhodné dále seskupit tyto toky podle uživatelů jimž náleží. Vytvářením profilu pro dvojici [uživatel, zařízení] by bylo možné dále zpřesnit profil chování a tím detekovat i menší odchylky, navíc je z bezpečnostního pohledu vhodnější identifikovat přímo uživatele zodpovědného za vzniklou hrozbu. Přiřazení toku uživateli je však komplikovaný úkol, neboť se nedá vyřešit pouze na základě síťových dat. Je nutná kooperace se systémem pro zajištění správy identit a účtování a zjistit, který uživatel v daném okamžiku využívá které zařízení. Příkladem takového systému může být RADIUS server ve spojení s LDAP či NIS. Pokud se v síti využívá kontrola přístupu k síti například pomocí IEEE 802.1X, měla by být identita uživatele dohledatelná. Jiné proprietární řešení pro rozšíření bezpečnosti o určení uživatele poskytuje společnost Cyberoam s technologií označovanou jako Identity-based security, která rozšiřuje síťový model ISO/OSI o novou vrstvu L8 s identifikací uživatele.
Sběr dat
Ke sbírání dat z internetového provozu lze použít sondy, které sledují datový provoz a zasílají o něm informace pro další zpracování. Tyto informace mohou sestávat z kompletního přepisu síťového provozu, nebo z nějaké abstrakce nad ním.
Surová data Pro kompletní záznamy síťového provozu se používá najčastěji formát pcap, což je zkrácenina z packet capture. Tento formát obsahuje pakety, které se na síti vyskytly, včetně veškerých dat.
Datové toky Nejčastější abstrakce nad datovým provozem jsou tzv. datové toky popsané v kapitole 4.1. V rámci toku jsou k dispozici statistické informace o reprezentovaných paketech, ale nejsou k dispozici data v nich obsažená. Tyto informace mohou poskytovat sondy pomocí IPFIX protokolu, který je určen právě pro přenos informací o tocích a specifikovaný organizací IETF. IPFIX vychází z NetFlow verze 9, což je proprietární řešení firmy Cisco, a sjednocuje přenos těchto informací ze zařízení různých výrobců. Vzhledem k tomu, že analýza chování nepotřebuje přístup k datům v paketech a pracuje se statistickými metodami, je mnohem vhodnější získávat informace o tocích. Pokud však chceme identifikovat zařízení podle MAC adres, nemůžeme použít standardní definici toků, jelikož ta zachycuje L3 vrstvu a vyšší. Až NetFlow verze 9 a z něj vycházející IPFIX umožňují pomocí šablon definovat obsah informací o toku a tím získat i MAC adresy účastníků.
Identifikace zařízení
V systémech pro sledování síťových dat se k identifikaci zařízení v naprosté většině pří- padů používá IP adresa. Výhodou IP adresy je její dobrá dostupnost, protože je přítomna v každém IP paketu a v rámci sítě je unikátní. Nevýhodou je však snadná zaměnitelnost a nestálost. S rozvojem mobilních zařízení dochází k tomu, že se do sítě přihlašují uživatelská zařízení dynamicky a aby mohly komunikovat bývá jim přiřazena IP adresa pomocí DHCP protokolu, v případě IPv6 si pak mohou IP adresu dokonce sami vygenerovat. IP adresa nám tedy sice identifikuje unikátně jedno zařízení, ale pouze během jednoho sezení. Budeme-li identifikovat zařízení podle IP adresy a vytvoříme pro něj model chování, může se stát, že při příštím sezení bude tato IP adresa přidělena jinému zařízení a model chování nebude odpovídat. Chceme-li tedy použít IP adresu pro identifikaci, musíme zajistit, aby každé zařízení mělo svou pevnou a neměnnou IP adresu
Jinou možností je využít MAC adresy, což je fyzická adresa síťového rozhraní, která je zcela unikátní pro zařízení a nezávislá na síťové vrstvě a použitých protokolech. Použití této adresy řeší problémy identifikace přenosných zařízení, přináší však problém dostupnosti. Zatímco IP adresa je při komunikaci v rámci sítě zpravidla konstantní a k přepisu dochází pouze na vnějším rozhraní sítě pokud je použit NAT, MAC adresa je přepsána nejbližším síťovým prvkem. Chceme-li tedy použít MAC adresu pro identifikaci, je nutné sbírat data ve všech segmentech sítě.
Kromě standardních síťových identifikátorů lze využít skutečnosti, že zařízení v podnikové síti bývají autentizována. Pokud síť vyžaduje autentizaci podle standardu IEEE 802.1X, je zařízení ověřováno vůči autentizačnímu serveru. Autentizační server tedy má 26 přístup k MAC adrese identifikující zařízení a může mít přístup i k identitě uživatele, pokud má každý uživatel unikátní přístupové údaje. Identifikaci zařízení by tedy bylo možné získat dotazem na autentizační server, problém však nastává v otázce mapování síťového toku na záznam uložený v autentizačním serveru. U IPv4 adres by bylo možné, pokud by autentizační server fungoval zároveň jako DHCP, vytvářet trojice: [uživatel, MAC zařízení, přidělená IP], díky kterým by se zařízení dalo pomocí IP adresy jednoznačně identifikovat. Autentizační server by ale musel udržovat historii sezení, aby bylo možné zpětně ověřit tyto hodnoty při pozdějším zpracování. Při použití IPv6 však má zařízení více IP adres a některé si volí samo a toto mapování pro něj není vhodné.
Tato práce používá pro identifikaci MAC adresu spolu s IP adresou. Díky této kombinaci lze využít jednoznačné identifikaci zařízení pomocí zcela unikátní MAC adresy a rozpoznat síťové prvky od koncových zařízení podle toho, že se na jednom fyzickém zařízení nachází více IPv4 adres.
Klíčové charakteristiky
Pro sledování chování síťového provozu je třeba definovat dvojí typ charakteristik. Prvním typem jsou definující charakteristiky, které definují daný síťový provoz a umožňují jej kategorizovat. Druhým typem jsou pak statistické charakteristiky, pomocí kterých lze popsat dění v síťovém provozu a na kterých lze detekovat anomálie
Definující charakteristiky
Pokud chceme vytvořit co nejpřesnější profil chování, je vhodné jej specifikovat pro dvojici [zařízení, uživatel], jak bylo zmíněno dříve v rámci této kapitoly. Zařízení budeme identifikovat pomocí dvojice [MAC adresa, IP adresa], identitu uživatele je pak nutné získat externě. Dále je vhodné rozdělit profil podle užitého protokolu transportní vrstvy a u nejčastějších protokolů TCP a UDP lze dále sledovat chování jednotlivých aplikací podle cílového portu. Sledováním cílového portu lze rozpoznat ke které službě klient při odesílání požadavku přistupuje, u serveru pozbývá tato informace smysl, protože klientské aplikace často volí své porty náhodně. Problémem při sledování aktivit aplikací dle cílových portů jsou zejména P2P aplikace, které navazují četná spojení s mnoha protistranami na náhodných portech. V rámci jedné aplikace je pak třeba rozlišovat mezi protistranami se kterými probíhá komunikace, což se dá sledovat podle cílové IP adresy (MAC adresu nelze použít při spojeních mezi různými segmenty sítě). Každá unikátní MAC adresa koncového zařízení, které se vyskytuje v síti, by měla mít svůj profil v modelu. Pokud bychom neodlišili koncové zařízení od síťových prvků, docházelo by k tomu, že by model chování pro routery oddělující segmenty sítě zahrnoval komunikaci celého segmentu sítě a nikoli pouze daného zařízení.
Statistické charakteristiky
U definujících charakteristik lze sledovat jejich rozptyl a hlásit, pokud nastane nějaký výkyv. Například každý výskyt nového zařízení, uživatele či použití nového protokolu transportní vrstvy by měl být zcela jistě detekován, protože se jedná o značně konstantní prvky. U portů a IP adres však může docházet k používání unikátních či náhodných hodnot a tím podstatně širšímu rozptylu. U portů to bude nastávat při sledování odchozí komunikace serverů, protože klienti většinou využívají náhodné porty. U IP adres může být příkladem vyhledávání na webu, během kterého uživatel navštíví různé IP adresy včetně těch, na které ještě nikdy nepřistoupil. I zde se však není rozložení zcela uniformní a dájí se rozlišit shluky rozsahů s vyšší pravděpodobností přístupu. V rámci jednotlivých toků pak lze sledovat jejich četnost a rozptyl v čase a to podle doby zahájení a trvání. Pro detekci přenosu většího množství dat je pak též vhodné sledovat velikost přenesených dat v rámci jednotlivých toků.
Šifrovaná spojení
Nejčastěji používané je šifrování na aplikační úrovni a jsou tedy šifrovaná pouze data, veškeré charakteristiky popsané výše jsou dostupné a pro detekci chování tedy nepředstavují žádný problém. Při použití šifrování na úrovni síťové, jako je například IPsec, jsou šifrované veškeré vyšší vrstvy včetně transportní a nedá se tedy rozlišit mezi aplikacemi. Je tedy nutné tato šifrovaná spojení sledovat zvlášť jako speciální typ aplikace.
Obecná specifikace detektoru
Navrhovaný systém pro rozpoznávání APT útoků sestává ze síťových sond, které sledují síťový provoz a odesílají o něm informace na server, kde dochází k porovnání aktuálního provozu s uloženým modelem. Jako sondy lze využít dedikovaná zařízení, stejnou funkcionalitu však nabízí i některé síťové prvky jako routery a switche. Pokud použijeme sondu, která podporuje agregaci síťového provozu do toků, je nutné využít taková zařízení, která statistiky o tocích vytváří ze všech paketů, a ne zařízení, která příchozí pakety vzorkují a zakládají statistiky na těchto vzorcích, protože ty pak nejsou přesnou statistikou provozu (je to způsobeno tím, že zahrnují pouze vzorky s danou vzorkovací frekvencí). Při použití sond bez možností agregace do toků je nutné před dalším zpracováváním tuto agregaci provést na straně serveru.
Serverová část se stará o zpracování dat ze sond v reálném čase - tedy tak, jak ze sond přijdou bez zbytečných prodlev. Přijatá data jsou klasifikována dle definujících charakteristik, které určují profil chování. Při nalezení odpovídajícího profilu lze další chování serveru rozlišit do dvou fází podle stavu profilu. Pokud je profil nekompletní, tedy při uvedení systému do provozu nebo přidání nového prvku (nová n-tice definujících charekteristik), použijí se data k vytvoření profilu chování daného prvku. Přidání nového prvku tedy neovlivní stá- vající profily, ale pouze vedou k vytvoření nového profilu pro daný prvek, který se nachází ve fázi vytváření profilu. Po uběhnutí určitého časového období je profil považován za kompletní a práce s ním přechází do fáze dvě, kde se detekují odchylky. Pomocí klasifikátoru je určena míra podobnosti dat ze sond s uloženým profilem. Pokud je tato míra podobnosti větší než nastavený práh, jsou data ze sondy použita pro aktualizaci profilu, je-li však tato hodnota nižší než práh, systém vyhodnotí chování jako podezřelé a zobrazí upozornění. Zobrazené upozornění musí obsahovat informace o zaznamenané odchylce a uživatel musí mít možnost toto chování označit za bezproblémové a rozšířit o ně profil.
Systém musí ukládat profily sítě permanentně, tedy tak, aby při restartu nedošlo k jejich ztrátě. Při startu systému pak musí být načteny všechny existující profily tak, aby se s nimi dalo pracovat stejně jako před ukončením běhu. Pokud by tento požadavek nebyl splněn, stačilo by útočníkovi způsobit restart systému a při vytváření nových profilů by již byl brán útočník jako normální provoz, což je nepřijatelné.
Návrh softwarové architektury
Popis komponent
Na obrázku 4.3 je uveden vysokoúrovňový návrh architektury rozlišující sondu sloužící pro získávání dat a serverovou část aplikace sloužící ke zpracování dat včetně výstupu.
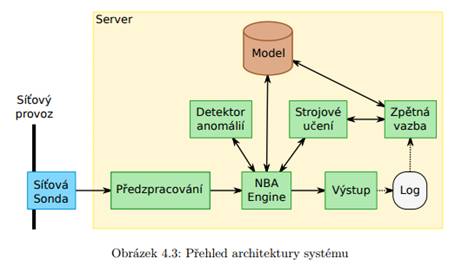
Následující popis objasňuje účel jednotlivých modulů a komunikaci mezi nimi.
Síťová sonda Tato sonda je umístěna na vhodném místě v síti, monitoruje provoz sítě a informace zasílá na serverovou část. Výhodné je jako sondy využít síťové prvky jako jsou směrovače a přepínače, pokud umožňují odesílání informací o síťovém provozu. Neumožňují-li odesílání těchto informací, je nutné využít speciální zařízení. Na server jsou pak podle možností sondy zasílány informace o tocích, nebo informace o paketech proudících v síti, pokud sonda agregaci do toků neumožňuje.
Předzpracování Modul předzpracování zajišťuje přijmutí dat ze sond a jejich transformaci do vnitřních struktur. Protože pro behaviorální analýzu nejsou důležité obsahy jednotlivých paketů, ale trendy v používání sítě, obsahují vnitřní struktury informace o tocích. Pokud sonda neumí informace z paketů agregovat do toků, zajišťuje agregaci tento modul. Každý identifikovaný tok je pak předán NBA Engine pro zpracování.
NBA Engine Hlavní modul zajíšťující behaviorální analýzu. Dostává vždy právě jeden tok z předzpracování, načte pro něj odpovídající profil z modelu a pokud je profil kompletní, zajistí porovnání daného toku s profilem a detekci anomálií. Pokud byl tok porovnán a bylo usouzeno, že se jedná o normální tok, zajistí aby byl profil aktualizován. Pokud byla detekována anomálie, k aktualizování profilu nedojde a jsou místo toho odeslány informace na modul výstupu. Pokud nebyl profil kompletní, NBA Engine pouze zajistí, aby byl daný tok zahrnut do profilu.
Model Obsahuje uložené profily jednotlivých aplikací a zajišťuje k nim přístup. Uložené modely musí být persistentní a musí být tedy průběžně ukládány na disk, aby v pří- padě přerušení běhu systému nedošlo ke ztrátě profilů.
Detektor anomálií Tento modul slouží k určení míry podobnosti mezi tokem a jeho profilem. Pokud NBA Engine nalezne odpovídající profil k toku, zašle tok a jeho profil detektoru anomálií, který pomocí klasifikátoru určí míru podobnosti, kterou zašle zpět do NBA enginu.
Strojové učení Sada metod pro vytváření a aktualizaci profilů. Modul je využíván NBA Enginem, odkud přichází požadavky na začlenění toku do modelu, nebo aktualizaci modelu. Využívá jej také modul zpětné vazby pro explicitní začlenění toku do modelu.
Výstup Pokud byla detekována anomálie, modul výstupu transformuje údaje o nalezené anomálii - včetně míry podobnosti detekovaného toku s profilem - na zprávu pro uživatele. Zajistí pak také zobrazení zprávy vhodným způsobem, jako například výpis v textovém formátu do logu anomálií.
Zpětná vazba Modul zpětné vazby umožňuje uživatelům explicitně ovlivňovat profily v modelu. Pokud je v logu anomálií hlášen incident, ale uživatel po ověření usoudí, že se jedná o normální stav, který není ojedinělý a měl by být začleněn do profilu, může toho pomocí tohoto modulu dosáhnout.
Model chování uživatele
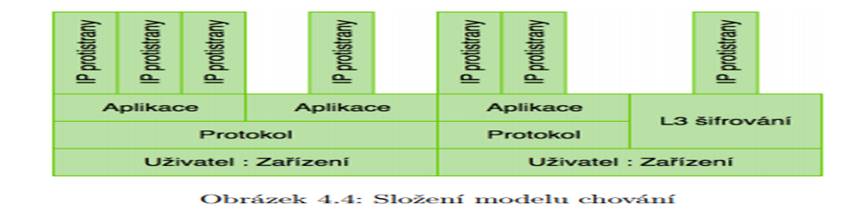
Jak lze vidět na obrázku 4.4, je model chování rozdělen do vrstev ve stromové struktuře. Každá z nich obsahuje informace o užším pásmu komunikace až na detailní úroveň komunikace dvou uzlů. V každé z vrstev jsou uloženy údaje o identitě vrstvy, které popisují, která část komunikace v ní je zachycena, veškeré podvrstvy a statistické údaje popisující danou vrstvu. V případě protokolové vrstvy u TCP protokolu bude kromě podvrstev s používanými aplikacemi uložena i informace o počtu aplikací a jejich rozptylu, což umožňuje sledovat přístupy na nové aplikace a také doba poslední aktualizace modelu pro předejití stárnutí. Pokud uživatel přestal nějakou aplikaci používat, je nutné to pomocí těchto dat rozpoznat a model chování dané aplikace odebrat.
Uživatel : Zařízení je dvojice určující základní dělení modelu. Zařízení je jednoznačně určeno MAC adresou, uživatel je pak získán z identitního systému. Pomocí této dvojice lze filtrovat síťový provoz na komunikaci jediného účastníka na jediném zařízení.
Protokol omezuje sledovaný provoz na jediný IP protokol. Nejčastěji se jedná o TCP a UDP protokoly, ale je nutné sledovat i ostatní protokoly, jelikož např. přes ICMP protokol lze tunelovat libovolné spojení a lze zde rozeznat VPN podle protokolů jako IPsec a GRE.
Aplikace je určena podle cílového portu u TCP a UDP protokolů. Protože je sledována odchozí komunikace, lze podle cílového portu rozlišit jednotlivé služby, ke kterým zařízení přistupuje.
Protistrana je určena cílovou IP adresou. V této vrstvě je zachycen model komunikace dvou uzlů v rámci aplikace.
Klasifikace datového provozu
Smyslem detektoru je klasifikovat provoz do dvou tříd - normální provoz a abnormální provoz. Tuto klasifikaci lze provést pomocí statistických metod, metod strojového učení, teorie her nebo jejich kombinací. Statistické metody shromažďují statistická data o provozu a model je tvořen průměrným vzorkem a prahem určujícím maximální povolenou odchylku. Pokud se potom testovaná data liší o více než zadaný práh, jsou klasifikována jako abnormální, jinak jsou považována za normální. U metod strojového učení je obvykle model tvořen jejich metodami, tento model je poté pomocí trénovacích dat zformován pro klasifikaci do potřebných tříd. Bohužel při hledání odchylek od normálního provozu máme k dispozici pouze zástupce jedné třídy a proto většina klasických metod strojového učení selhává. Pro tyto potřeby jsou použitelné jen některé algoritmy označované jako algoritmy pro hledání odchylek (ang. „outlier“), nejznámější jsou potom algoritmy K-nearest neighbor a Local Outlier Factor (LOF).
K-nearest neighbor
K-nearest neighbor algoritmus (označovaný většinou jen jako k-NN) je jeden ze základních algoritmů pro klasifikaci. Tento algoritmus chápe data jako množinu n-tic (matematicky vektorů), ve kterých hledá pro testovaný vzorek určitý počet nejbližších sousedů. Počet těchto sousedů je zadán parametrem k a vzdálenosti mezi n-ticemi jsou dány libovolnou distanční funkcí, nejčastěji je využívána Euclidovská vzdálenost definovaná jako:
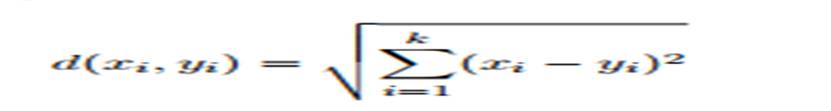
kde x a y jsou porovnávané vektory[32]. V těchto nalezených sousedech porovná algoritmus příslušnost do tříd a zařadí vzorek do té třídy, jejíž četnost je mezi sousedy nejvyšší. Při použití pro detekci anomálií zkoumá tento algorimus místo tříd sousedů pouze vzdálenost od jednotlivých sousedů, pokud je tato vzdálenost větší, než je obvyklé, je detekována anomálie. Na obrázku 4.5 je zobrazen model se shluky vzorků a testovaný vzorek, který je přiřazen do nejbližšího shluku.
Tento algoritmus, ač je v principu značně jednoduchý, je poměrně komplikované vhodně implementovat. Jeho spolehlivost je totiž velmi závislá na použité distanční funkci a testovacích datech. Použití Euclidovské vzdálenosti jako distanční funkce předpokládá stejný význam a stejnou metriku pro všechny dimenze, v reálných datech se ale často stupnice pro jednotlivé dimenze diametrálně liší a některé dimenze mohou být dokonce určeny i textem. Tento problém přetrvává i při použití jiných distančních funkcí jako například Hammingovy vzdálenosti nebo Minkowskiho metriky a je obecně platný pro různé klasifikační algoritmy. Proto je vhodné jednotlivé hodnoty transformovat a převést je na společnou metriku. Pro transformaci hodnot lze použít různých metod jako je například Z-skóre
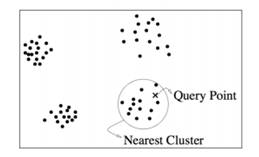
Obrázek 4.5: Klasifikace vzorku do shluku podle nejbližších sousedů, převzato z
přemapovávající hodnoty podle jejich standartních odchylek na hodnoty se středem v 0 a maximální odchylce 1 podle vzorce:
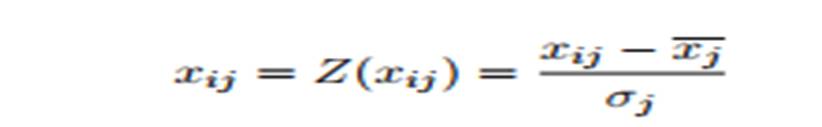
kde 𝑥𝑗 označuje průměrnou hodnotu parametru 𝑗 a 𝜎𝑗 jeho standartní odchylku[26]. Jinou možností je přemapovat hodnoty metodou min-max x do intervalu kde 0 označuje minimální hodnotu a 1 maximální pomocí vzorce:
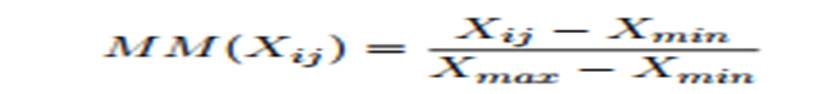
kde 𝑋𝑚𝑎𝑥 je maximální a 𝑋𝑚𝑖𝑛 minimální hodnota.
Kromě problémů s různými metrikami u dimenzí se jako problematický jeví i samotný počet dimenzí. Zdánlivě by se mohlo zdát, že čím více dimenzí použijeme, tím přesnějších výsledků bude algoritmus dosahovat, ale při testování na reálných datech se prokázalo, že zvolení správného počtu dimenzí je netriviální úkol a po saturaci dochází k poklesu přesnosti. Tento jev se nazývá Curse of Dimensionality. Pro redukci nadbytečných dimenzí lze využít speciálních metod, jako je například Principal Component Analysis (PCA), které procházejí trénovací data a odstraňují dimenze mající minimální vliv na klasifikaci[28]. Tyto metody jsou však často vysoce výpočetně náročné, protože musí porovnat celý tré- novací soubor s výsledky klasifikátoru a určit míru s jakou se která dimenze projevila do cílové klasifikace.
Algoritmus k-NN používá jako svůj model celou trénovací množinu a testovací vzorky porovnává se vzorky z ní. Protože však trénovací množina může být dosti obsáhlá a pokud budeme chtít, aby se algoritmus s postupem času adaptoval na změny v datech, je nutné tuto množinu redukovat. Jedním z algoritmů redukce trénovacích dat je Condensed Nearest Neighbor (CNN), který se snaží vytvořit pro shluky jednotlivých vzorků prototypy, kterými lze v modelu celý shluk nahradit[37].
Specifickým problémem algoritmu k-NN je nalezení vhodného k, tedy počtu soustedů, kteří mají být porovnáváni. Parametr k je velmi závislý na použitých datech a zásadním způsobem ovlivňuje přesnost algoritmu. Speciálním případem je 𝑘 = 1, kdy je porovnáván pouze nejbližší soused a na jeho základě je vzorek klasifikován. Použitím malých hodnot k dochází k rozdělení modelu na mnoho drobných oblastí podle jednotlivých trénovacích vzorků. Pokud však použijeme vyšší hodnoty k, je algoritmus schopen rozpoznat abnormální vzorky v trénovacím souboru, které leží mimo oblasti hlavního shluku daných vzorků a tyto se pak ve výsledném modelu neprojeví. Zvyšováním hodnoty k tedy snižujeme vliv chyb v trénovacím souboru na cílový model, ale snižujeme tím také rozlišovací schopnosti modelu.
Implementace detektoru abnormálního chování
Předzpracování
Přestože se jako nejvýhodnější pro sběr dat jeví IPFIX, popřípadě NetFlow, jejich použití v testovacích podmínkách se ukázalo jako nesnadné pro nutnost použití síťové infrastruktury, složité nastavení sondy a nutnost implementace kolektoru do modulu předzpracování. Dalším problémem sběru toků v testovacím prostředí jsou implementace sond, které sbí- raná data shromažďují a zasílají je na kolektor ve shlucích. Proto byl zvolen sběr surových síťových dat ve formátu pcap a z nich jsou poté v předzpracování tvořeny datové toky obsahující statistické informace.
Předzpracování je implementováno jako samostatný program pcap2flow, který umí na- číst pcap soubor a zpracovat jej na CSV soubor s datovými toky. Tento program je vytvořen v jazyce Python 2.7 a pro práci s pcap soubory používá knihovnu Scapy. Program je pak tvořen zejména třídou FlowParser, která umožňuje iterovat nad toky v pcap souboru a strukturou Flow reprezentující jeden datový tok. Pro vnitřní zpracování se využívají struktury FlowHeader obsahující hlavičku jednoho toku a FlowStats, kde se kumulují statistická data jednoho toku.
Hlavní program se provede, pokud je skript spuštěn jako program, tedy pokud je speciální proměnná __name__ nastavena na __main__. Dojde ke zpracování argumentů pomocí standartní knihovny argparse a pokud byl zadán pcap soubor, dojde k jeho zpracování a vypsání nalezených toků ve formátu CSV. Každý řádek výstupu, kromě prvního, který obsahuje nadpisy sloupců, reprezentuje jeden nalezený tok a ve sloupcích jsou pak údaje o daném toku.
Namedtuple Flow je struktura obsahující popis jednoho datového toku. Jako datový typ byl zvolen namedtuple, protože se jedná o uspořádanou n-tici hodnot a namedtuple nám umožní si pojmenovat jednotlivé dimenze.
Namedtuple FlowHeader je struktura definující hlavičku datového toku, stejně jako u celého toku je i hlavička reprezentována datovým typem nameduple. Pro každý paket je vytvořena z jeho dat hlavička toku a porovnáno, jestli již tok se stejnou hlavičkou neexistuje. Pokud ano, je pouze aktualizován o statistická data z daného paketu, v opačném případě musí být vytvořen. Hlavička toku je tvořena MAC adresou odesílatele, IP adresami odesílatele i příjemce, použitým protokolem L4 vrstvy, IP Type of Service a zdrojovým a cílovým portem.
Třída FlowStats obsahuje statistické informace o jednom datovém toku. Na rozdíl od předchozích reprezentací informací o datovém toku bylo nutno vytvořit samostatnou třídu, protože datový typ namedtuple je neměnný a statistické informace je třeba aktualizovat s každým paketem spadajícím do daného toku
Třída FlowParser zajišťuje zpracování toků ze souboru paketů. Chová se při tom jako iterátor a lze ji tedy využít ve smyčce, kde třída vrací postupně nalezené toky. V případě, že preferujeme zpracování celého souboru a vrácení pole toků, lze zavolat metodu read_all. Dále obsahuje třída metodu next pro načtení následujícího toku a privátní metody pro zpracování paketů - _processTCPpacket, _processUDPpacket, _processICMPpacket, pro uzavření toku - _closeFlow a pro převod FlowHeader a FlowStats na Flow.
FlowParser::next je metoda, které nalezne následující tok a vrátí o něm informace. Tato metoda načítá postupně pakety a ukládá si informace o nalezených tocích, jakmile je nějaký tok kompletní vrátí jej. Pokud již není na vstupu žádný paket, uzavře postupně všechny neukončené toky a vrací je. Bylo rozhodnuto, že pro potřeby této práce postačuje zpracování pouze TCP/IP paketů, proto je ostatní provoz touto metodou ignorován.
FlowParser::_processTCPpacket zpracovává jeden TCP paket. Nejprve je z dat obsažených v paketu zkonstruována hlavička toku a je ověřeno, zda obsahuje SYN příznak. Pokud ano, znamená to, že se jedná o nový tok a pokud je tok s danou hlavičkou nalezen jako otevřený, je uzavřen. Pokud se jedná o nový tok, je vytvořena jeho reprezentace v otevřených tocích a jsou do ní zaneseny statistické údaje o paketu, pokud je již nalezen otevřený tok se stejnou hlavičkou, jsou pouze statistické hodnoty aktualizovány.
FlowParser::_closeFlow odstraní tok ze seznamu otevřených toků a vrátí jeho reprezentaci jako Flow objekt.
Klasifikace
Pro implementaci klasifikátoru pro rozpoznávání anomálií byla zvolena softwarová platforma RapidMiner, která je určena pro strojové učení, analýzu a práci s daty. Základní verze je navíc dostupná pod otevřenou licencí AGPL-3.0 a lze ji tedy použít a upravovat podle potřeb. Tato platforma umožňuje získat data z různých zdrojů, provádět nad nimi skupiny operací, které nazývá proces, a zobrazit a interpretovat jejich výsledky. Pro tvorbu a práci poskytuje platforma grafické rozhraní, k výpočetnímu jádru se ale dá připojit i pomocí API a začlenit jej tak do libovolného programu. Základní verze umožňuje načítání z Open Source databází, Excelovských sešitů a souborů ve formátu CSV. Právě díky podpoře CSV a jednoduchosti tohoto formátu byl tento zvolen pro přenos dat mezi předzpracováním v Pythonu a klasifikátorem v RapidMineru. Proces je pak tvořen posloupností operátorů, což jsou bloky provádějící určitou činnost, které mají definovány vstupy, výstupy, prováděnou transformaci vstupů na výstupy a parametry této transformace.
V rámci klasifikace byly implementovány dva moduly z návrhu v kapitole 4.3, a to NBA Engine a samotný Detektor anomálií. Protože metoda k-NN používá jako model množinu prvků, načítá NBA Engine seznam toků z CSV souborů, ze kterých vybere pouze ty, které jsou pro daný model platné a ty pak dále upraví na formu vhodnou pro detektor anomálií. Detektor anomálií pak pro jednotlivé toky spočte míru anomality a zpřístupní výsledky výstupnímu zpracování RapidMineru, který umožňuje jejich zobrazení a interpretaci. Na obrázku 4.6 je zobrazen celý proces, který se skládá z obou těchto modulů.

NBA Engine
NBA Engine je tvořen dvěma subprocesy - Model data selection a Data transformation, kde se první subproces stará o výběr pouze těch toků a informací v nich, které jsou pro daný model relevantní a druhý proces se stará o transformaci těchto dat do podoby vhodné pro výpočet Euclidovské vzdálenosti v metodě k-NN.
Model data selection je tvořen operátory Filter Examples, umožňující definovat filtr, který bude aplikován na vstupní data a výstupem operátoru budou pouze ta data, která splňují zadaná pravidla. Pomocí posloupnosti těchto operátorů, která je uvedena na obrázku 4.7, omezí tento podproces zpracovávaná data na jediný model komunikace dvou zařízení podle vrstev uvedených v kapitole 4.3.2.
Po vyfiltrování pouze těchto toků je, kvůli vyhnutí se Curse of Dimensionality popsané v kapitole 4.3.3, nutné vybrat z toků pouze ty dimenze, které mají dopad na určení třídy. Pro výběr pouze některých dimenzí ze vzorku je použit operátor Select Attributes, který umožňí definovat, které dimenze se mají objevit na výstupu a které nikoli. Do modelových dat nebyly zahrnuty hodnoty použité k jejich filtrování, jelikož jsou u všech vzorků totožné, ani zdrojový port, který bývá u odchozí komunikace z klientských stanic většinou volen ná- hodně. Zahrnuta také nebyla informace o IP Type of Service, která byla u všech testovaných položek shodná a nepřispívá tedy ke klasifikaci.

Data transformation slouží k vyřešení problému s různými metrikami dimenzí popsaném v kapitole 4.3.3 tím, že je transformuje na jednotnou metriku. To je provedeno pomocí operátoru Normalize. Tento operátor umožňuje tranformovat původní metriky dimenzí na nové pomocí jedné ze 4 metod - Z-transformací, transformací rozsahu, proporční transformací a interkvartilním rozsahem. Z-tranformace odpovídá Z-skóre popsanému v kapitole 4.3.3 a transormace rozsahu je min-max metoda popsaná tamtéž. Protože metoda min-max transformuje hodnoty na rozsah < 0; 1 >, který lze přirozeněji interpretovat například jako hodnotu ve fuzzy logice, byla zvolena tato transformace, po jejímž provedení jsou data připravena pro metodu k-NN.
Detektor anomálií
V základní verzi RapidMineru je implementován klasifikátor k-NN, který slouží k zařazení dat do tříd. Německé výzkumné středisko umělé inteligence (DFKI[2]) zveřejnilo rozšiřující modul pro RapidMiner, který obsahuje mimo jiné použití k-NN pro detekci anomálií. Základní verze RapidMineru sice neumožňuje instalaci rozšíření pomocí GUI rozhraní a repozitáře RapidMiner Marketplace, ale modul lze doinstalovat manuální cestou. Po instalaci je možné použít operátor k-NN Global Anomaly Score, který příjmá data, u kterých spočte míru anomality, což je průměrná vzdálenost od k nejbližších sousedů. Kromě průměrování vzdálenosti lze tento operátor také nastavit pro nalezení n-tého nejbližšího souseda a skóre pak nastavit podle něj. Pro výpočty vzdáleností je implementováno mnoho metod včetně Euclidovské a Manhatanské vzdálenosti. Protože při k-NN je nejvíce času spotřebováno na výpočet vzdá- leností od ostatních vzorků, aby mohly být vypočteni nejbližší sousedi, umožňuje tento operátor vypočtené hodnoty uchovat jako model a znovu je pak načíst.
Operátor použitý při implementaci detektoru anomálií byl nastaven na výpočet vzdáleností pomocí Euclidovy metody, pro kterou byla data optimalizována. Počet porovnávaných sousedů byl nastaven na hodnotu 2, která byla zvolena jako vhodná vzhledem k testovacím datům. Nastavení nízké hodnoty je problematické, protože při výskytu více anomálních toků může dojít pouze k jejich porovnání navzájem a výsledná vzdálenost není vypovídající. U vyšších počtů kontrolovaných sousedů je zapotřebí více dat v modelu, aby byla detekce možná.