
"ChatGPT users should regularly review the memories the system stores about them, for suspicious or incorrect ones and clean them up," Rehberger said.
ChatGPT macOS Flaw Could've Enabled Long-Term Spyware via Memory Function
25.9.24 AI The Hacker News
A now-patched security vulnerability in OpenAI's ChatGPT app for macOS could have made it possible for attackers to plant long-term persistent spyware into the artificial intelligence (AI) tool's memory.
The technique, dubbed SpAIware, could be abused to facilitate "continuous data exfiltration of any information the user typed or responses received by ChatGPT, including any future chat sessions," security researcher Johann Rehberger said.
The issue, at its core, abuses a feature called memory, which OpenAI introduced earlier this February before rolling it out to ChatGPT Free, Plus, Team, and Enterprise users at the start of the month.
What it does is essentially allow ChatGPT to remember certain things across chats so that it saves users the effort of repeating the same information over and over again. Users also have the option to instruct the program to forget something.
"ChatGPT's memories evolve with your interactions and aren't linked to specific conversations," OpenAI says. "Deleting a chat doesn't erase its memories; you must delete the memory itself."
The attack technique also builds on prior findings that involve using indirect prompt injection to manipulate memories so as to remember false information, or even malicious instructions, thereby achieving a form of persistence that survives between conversations.
"Since the malicious instructions are stored in ChatGPT's memory, all new conversation going forward will contain the attackers instructions and continuously send all chat conversation messages, and replies, to the attacker," Rehberger said.
"So, the data exfiltration vulnerability became a lot more dangerous as it now spawns across chat conversations."
In a hypothetical attack scenario, a user could be tricked into visiting a malicious site or downloading a booby-trapped document that's subsequently analyzed using ChatGPT to update the memory.
The website or the document could contain instructions to clandestinely send all future conversations to an adversary-controlled server going forward, which can then be retrieved by the attacker on the other end beyond a single chat session.
Following responsible disclosure, OpenAI has addressed the issue with ChatGPT version 1.2024.247 by closing out the exfiltration vector.
"ChatGPT users should regularly review the memories the system stores about them, for suspicious or incorrect ones and clean them up," Rehberger said.
"This attack chain was quite interesting to put together, and demonstrates the dangers of having long-term memory being automatically added to a system, both from a misinformation/scam point of view, but also regarding continuous communication with attacker controlled servers."
The disclosure comes as a group of academics has uncovered a novel AI jailbreaking technique codenamed MathPrompt that exploits large language models' (LLMs) advanced capabilities in symbolic mathematics to get around their safety mechanisms.
"MathPrompt employs a two-step process: first, transforming harmful natural language prompts into symbolic mathematics problems, and then presenting these mathematically encoded prompts to a target LLM," the researchers pointed out.
The study, upon testing against 13 state-of-the-art LLMs, found that the models respond with harmful output 73.6% of the time on average when presented with mathematically encoded prompts, as opposed to approximately 1% with unmodified harmful prompts.
It also follows Microsoft's debut of a new Correction capability that, as the name implies, allows for the correction of AI outputs when inaccuracies (i.e., hallucinations) are detected.
"Building on our existing Groundedness Detection feature, this groundbreaking capability allows Azure AI Content Safety to both identify and correct hallucinations in real-time before users of generative AI applications encounter them," the tech giant said.
Ireland's Watchdog Launches Inquiry into Google's AI Data Practices in Europe
13.9.24 AI The Hacker News
The Irish Data Protection Commission (DPC) has announced that it has commenced a "Cross-Border statutory inquiry" into Google's foundational artificial intelligence (AI) model to determine whether the tech giant has adhered to data protection regulations in the region when processing the personal data of European users.
"The statutory inquiry concerns the question of whether Google has complied with any obligations that it may have had to undertake an assessment, pursuant to Article 35[2] of the General Data Protection Regulation (Data Protection Impact Assessment), prior to engaging in the processing of the personal data of E.U./E.E.A. data subjects associated with the development of its foundational AI model, Pathways Language Model 2 (PaLM 2)," the DPC said.
PaLM 2 is Google's state-of-the-art language model with improved multilingual, reasoning, and coding capabilities. It was unveiled by the company in May 2023.
With Google's European headquarters based in Dublin, the DPC acts as the primary regulator responsible for making sure the company abides by the bloc's stringent data privacy rulebook.
The DPC said an inquiry is crucial to ensure that individuals' fundamental rights and freedoms are safeguarded, especially when processing of such data when developing AI systems can lead to a "high risk."
The development comes weeks after social media platform X permanently agreed not to train its AI chatbot, Grok, using the personal data it collected from European users without obtaining prior consent. Back in August, the DPC said X consented to suspend its "processing of the personal data contained in the public posts of X's E.U./E.E.A. users which it processed between 7 May 2024 and 1 August 2024."
Meta, which recently admitted to scraping every Australian adult Facebook user's public data to train its Llama AI models without giving them an opt-out, has paused its plans to use content posted by European users following a request from the DPC over privacy concerns. It has also suspended the use of generative AI (GenAI) in Brazil after the country's data protection authority issued a preliminary ban objecting to its new privacy policy.
Last year, Italy's data privacy regulator also temporarily banned OpenAI's ChatGPT because of concerns that its practices are in violation of data protection laws in the region.
OpenAI Blocks Iranian Influence Operation Using ChatGPT for U.S. Election Propaganda
17.8.24 AI The Hacker News
OpenAI on Friday said it banned a set of accounts linked to what it said was an Iranian covert influence operation that leveraged ChatGPT to generate content that, among other things, focused on the upcoming U.S. presidential election.
"This week we identified and took down a cluster of ChatGPT accounts that were generating content for a covert Iranian influence operation identified as Storm-2035," OpenAI said.
"The operation used ChatGPT to generate content focused on a number of topics — including commentary on candidates on both sides in the U.S. presidential election – which it then shared via social media accounts and websites."
The artificial intelligence (AI) company said the content did not achieve any meaningful engagement, with a majority of the social media posts receiving negligible to no likes, shares, and comments. It further noted it had found little evidence that the long-form articles created using ChatGPT were shared on social media platforms.
The articles catered to U.S. politics and global events, and were published on five different websites that posed as progressive and conservative news outlets, indicating an attempt to target people on opposite sides of the political spectrum.
OpenAI said its ChatGPT tool was used to create comments in English and Spanish, which were then posted on a dozen accounts on X and one on Instagram. Some of these comments were generated by asking its AI models to rewrite comments posted by other social media users.
"The operation generated content about several topics: mainly, the conflict in Gaza, Israel's presence at the Olympic Games, and the U.S. presidential election—and to a lesser extent politics in Venezuela, the rights of Latinx communities in the U.S. (both in Spanish and English), and Scottish independence," OpenAI said.
"They interspersed their political content with comments about fashion and beauty, possibly to appear more authentic or in an attempt to build a following."
Storm-2035 was also one of the threat activity clusters highlighted last week by Microsoft, which described it as an Iranian network "actively engaging U.S. voter groups on opposing ends of the political spectrum with polarizing messaging on issues such as the US presidential candidates, LGBTQ rights, and the Israel-Hamas conflict."
Some of the phony news and commentary sites set up by the group include EvenPolitics, Nio Thinker, Savannah Time, Teorator, and Westland Sun. These sites have also been observed utilizing AI-enabled services to plagiarize a fraction of their content from U.S. publications. The group is said to be operational from 2020.
Microsoft has further warned of an uptick in foreign malign influence activity targeting the U.S. election over the past six months from both Iranian and Russian networks, the latter of which have been traced back to clusters tracked as Ruza Flood (aka Doppelganger), Storm-1516, and Storm-1841 (aka Rybar).
"Doppelganger spreads and amplifies fabricated, fake or even legitimate information across social networks," French cybersecurity company HarfangLab said. "To do so, social networks accounts post links that initiate an obfuscated chain of redirections leading to final content websites."
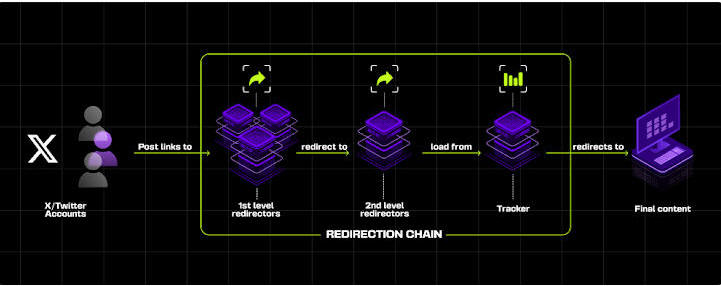
However, indications are that the propaganda network is shifting its tactics in response to aggressive enforcement, increasingly using non-political posts and ads and spoofing non-political and entertainment news outlets like Cosmopolitan, The New Yorker and Entertainment Weekly in an attempt to evade detection, per Meta.
The posts contain links that, when tapped, redirects users to a Russia war- or geopolitics-related article on one of the counterfeit domains mimicking entertainment or health publications. The ads are created using compromised accounts.
The social media company, which has disrupted 39 influence operations from Russia, 30 from Iran, and 11 from China since 2017 across its platforms, said it uncovered six new networks from Russia (4), Vietnam (1), and the U.S. (1) in the second quarter of 2024.
"Since May, Doppelganger resumed its attempts at sharing links to its domains, but at a much lower rate," Meta said. "We've also seen them experiment with multiple redirect hops including TinyURL's link-shortening service to hide the final destination behind the links and deceive both Meta and our users in an attempt to avoid detection and lead people to their off-platform websites."
The development comes as Google's Threat Analysis Group (TAG) also said this week that it had detected and disrupted Iranian-backed spear-phishing efforts aimed at compromising the personal accounts of high-profile users in Israel and the U.S., including those associated with the U.S. presidential campaigns.
The activity has been attributed to a threat actor codenamed APT42, a state-sponsored hacking crew affiliated with Iran's Islamic Revolutionary Guard Corps (IRGC). It's known to share overlaps with another intrusion set known as Charming Kitten (aka Mint Sandstorm).
"APT42 uses a variety of different tactics as part of their email phishing campaigns — including hosting malware, phishing pages, and malicious redirects," the tech giant said. "They generally try to abuse services like Google (i.e. Sites, Drive, Gmail, and others), Dropbox, OneDrive and others for these purposes."
The broad strategy is to gain the trust of their targets using sophisticated social engineering techniques with the goal of getting them off their email and into instant messaging channels like Signal, Telegram, or WhatsApp, before pushing bogus links that are designed to collect their login information.
The phishing attacks are characterized by the use of tools like GCollection (aka LCollection or YCollection) and DWP to gather credentials from Google, Hotmail, and Yahoo users, Google noted, highlighting APT42's "strong understanding of the email providers they target."
"Once APT42 gains access to an account, they often add additional mechanisms of access including changing recovery email addresses and making use of features that allow applications that do not support multi-factor authentication like application-specific passwords in Gmail and third-party app passwords in Yahoo," it added.
Researchers Uncover Vulnerabilities in AI-Powered Azure Health Bot Service
13.8.24 AI The Hacker News
Cybersecurity researchers have discovered two security flaws in Microsoft's Azure Health Bot Service that, if exploited, could permit a malicious actor to achieve lateral movement within customer environments and access sensitive patient data.
The critical issues, now patched by Microsoft, could have allowed access to cross-tenant resources within the service, Tenable said in a new report shared with The Hacker News.
The Azure AI Health Bot Service is a cloud platform that enables developers in healthcare organizations to build and deploy AI-powered virtual health assistants and create copilots to manage administrative workloads and engage with their patients.
This includes bots created by insurance service providers to allow customers to look up the status of a claim and ask questions about benefits and services, as well as bots managed by healthcare entities to help patients find appropriate care or look up nearby doctors.
Tenable's research specifically focuses on one aspect of the Azure AI Health Bot Service called Data Connections, which, as the name implies, offers a mechanism for integrating data from external sources, be it third parties or the service providers' own API endpoints.
While the feature has built-in safeguards to prevent unauthorized access to internal APIs, further investigation found that these protections could be bypassed by issuing redirect responses (i.e., 301 or 302 status codes) when configuring a data connection using an external host under one's control.
By setting up the host to respond to requests with a 301 redirect response destined for Azure's metadata service (IMDS), Tenable said it was possible to obtain a valid metadata response and then get hold of an access token for management.azure[.]com.
The token could then be used to list the subscriptions that it provides access to by means of a call to a Microsoft endpoint that, in turn, returns an internal subscription ID, which could ultimately be leveraged to list the accessible resources by calling another API.
Separately, it was also discovered that another endpoint related to integrating systems that support the Fast Healthcare Interoperability Resources (FHIR) data exchange format was susceptible to the same attack as well.
Tenable said it reported its findings to Microsoft in June and July 2024, following which the Windows maker began rolling out fixes to all regions. There is no evidence that the issue was exploited in the wild.
"The vulnerabilities raise concerns about how chatbots can be exploited to reveal sensitive information," Tenable said in a statement. "In particular, the vulnerabilities involved a flaw in the underlying architecture of the chatbot service, highlighting the importance of traditional web app and cloud security in the age of AI chatbots."
The disclosure comes days after Semperis detailed an attack technique called UnOAuthorized that allows for privilege escalation using Microsoft Entra ID (formerly Azure Active Directory), including the ability to add and remove users from privileged roles. Microsoft has since plugged the security hole.
"A threat actor could have used such access to perform privilege elevation to Global Administrator and install further means of persistence in a tenant," security researcher Eric Woodruff said. "An attacker could also use this access to perform lateral movement into any system in Microsoft 365 or Azure, as well as any SaaS application connected to Entra ID."
This AI-Powered Cybercrime Service Bundles Phishing Kits with Malicious Android Apps
27.7.24 AI The Hacker News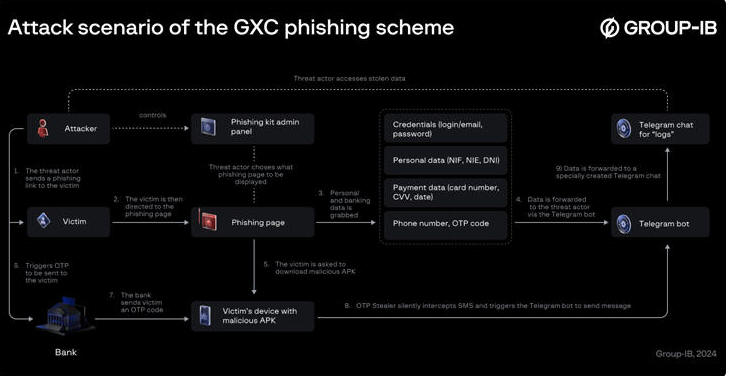
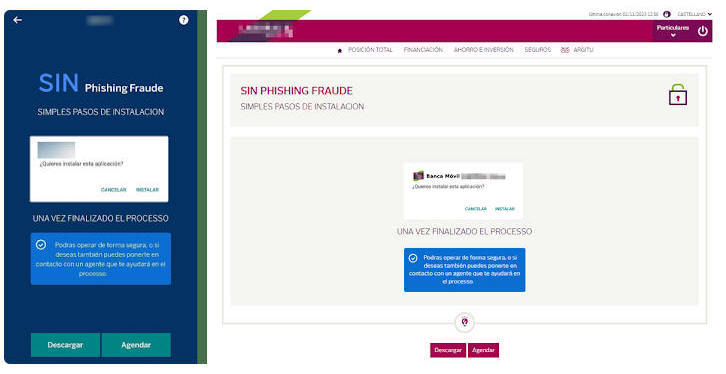
A Spanish-speaking cybercrime group named GXC Team has been observed bundling phishing kits with malicious Android applications, taking malware-as-a-service (MaaS) offerings to the next level.
Singaporean cybersecurity company Group-IB, which has been tracking the e-crime actor since January 2023, described the crimeware solution as a "sophisticated AI-powered phishing-as-a-service platform" capable of targeting users of more than 36 Spanish banks, governmental bodies, and 30 institutions worldwide.
The phishing kit is priced anywhere between $150 and $900 a month, whereas the bundle including the phishing kit and Android malware is available on a subscription basis for about $500 per month.
Targets of the campaign include users of Spanish financial institutions, as well as tax and governmental services, e-commerce, banks, and cryptocurrency exchanges in the United States, the United Kingdom, Slovakia, and Brazil. As many as 288 phishing domains linked to the activity have been identified to date.
Also part of the spectrum of services offered are the sale of stolen banking credentials and custom coding-for-hire schemes for other cybercriminal groups targeting banking, financial, and cryptocurrency businesses.
"Unlike typical phishing developers, the GXC Team combined phishing kits together with an SMS OTP stealer malware pivoting a typical phishing attack scenario in a slightly new direction," security researchers Anton Ushakov and Martijn van den Berk said in a Thursday report.
What's notable here is that the threat actors, instead of directly making use of a bogus page to grab the credentials, urge the victims to download an Android-based banking app to prevent phishing attacks. These pages are distributed via smishing and other methods.
Once installed, the app requests for permissions to be configured as the default SMS app, thereby making it possible to intercept one-time passwords (OTPs) and other messages and exfiltrate them to a Telegram bot under their control.
"In the final stage the app opens a genuine bank's website in WebView allowing users to interact with it normally," the researchers said. "After that, whenever the attacker triggers the OTP prompt, the Android malware silently receives and forwards SMS messages with OTP codes to the Telegram chat controlled by the threat actor."
Among the other services advertised by the threat actor on a dedicated Telegram channel are AI-infused voice calling tools that allow its customers to generate voice calls to prospective targets based on a series of prompts directly from the phishing kit.
These calls typically masquerade as originating from a bank, instructing them to provide their two-factor authentication (2FA) codes, install malicious apps, or perform other arbitrary actions.
"Employing this simple yet effective mechanism enhances the scam scenario even more convincing to their victims, and demonstrates how rapidly and easily AI tools are adopted and implemented by criminals in their schemes, transforming traditional fraud scenarios into new, more sophisticated tactics," the researchers pointed out.
In a recent report, Google-owned Mandiant revealed how AI-powered voice cloning have the capability to mimic human speech with "uncanny precision," thus allowing for more authentic-sounding phishing (or vishing) schemes that facilitate initial access, privilege escalation, and lateral movement.
"Threat actors can impersonate executives, colleagues, or even IT support personnel to trick victims into revealing confidential information, granting remote access to systems, or transferring funds," the threat intelligence firm said.
"The inherent trust associated with a familiar voice can be exploited to manipulate victims into taking actions they would not normally take, such as clicking on malicious links, downloading malware, or divulging sensitive data."
Phishing kits, which also come with adversary-in-the-middle (AiTM) capabilities, have become increasingly popular as they lower the technical barrier to entry for pulling off phishing campaigns at scale.
Security researcher mr.d0x, in a report published last month, said it's possible for bad actors to take advantage of progressive web apps (PWAs) to design convincing login pages for phishing purposes by manipulating the user interface elements to display a fake URL bar.
What's more, such AiTM phishing kits can also be used to break into accounts protected by passkeys on various online platforms by means of what's called an authentication method redaction attack, which takes advantage of the fact that these services still offer a less-secure authentication method as a fallback mechanism even when passkeys have been configured.
"Since the AitM can manipulate the view presented to the user by modifying HTML, CSS, and images, or JavaScript in the login page, as it is proxied through to the end user, they can control the authentication flow and remove all references to passkey authentication," cybersecurity company eSentire said.
The disclosure comes amid a recent surge in phishing campaigns embedding URLs that are already encoded using security tools such as Secure Email Gateways (SEGs) in an attempt to mask phishing links and evade scanning, according to Barracuda Networks and Cofense.
Social engineering attacks have also been observed resorting to unusual methods wherein users are enticed into visiting seemingly legitimate-but-compromised websites and are then asked to manually copy, paste, and execute obfuscated code into a PowerShell terminal under the guise of fixing issues with viewing content in a web browser.
Details of the malware delivery method have been previously documented by ReliaQuest and Proofpoint. McAfee Labs is tracking the activity under the moniker ClickFix.
"By embedding Base64-encoded scripts within seemingly legitimate error prompts, attackers deceive users into performing a series of actions that result in the execution of malicious PowerShell commands," researchers Yashvi Shah and Vignesh Dhatchanamoorthy said.
"These commands typically download and execute payloads, such as HTA files, from remote servers, subsequently deploying malware like DarkGate and Lumma Stealer."
SAP AI Core Vulnerabilities Expose Customer Data to Cyber Attacks
18.7.24 AI The Hacker News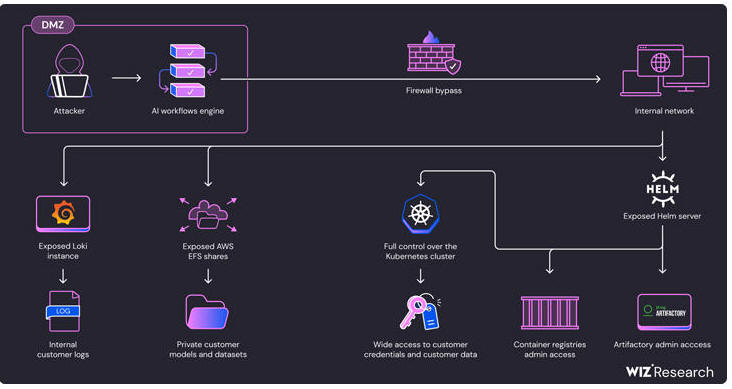
Cybersecurity researchers have uncovered security shortcomings in SAP AI Core cloud-based platform for creating and deploying predictive artificial intelligence (AI) workflows that could be exploited to get hold of access tokens and customer data.
The five vulnerabilities have been collectively dubbed SAPwned by cloud security firm Wiz.
"The vulnerabilities we found could have allowed attackers to access customers' data and contaminate internal artifacts – spreading to related services and other customers' environments," security researcher Hillai Ben-Sasson said in a report shared with The Hacker News.
Following responsible disclosure on January 25, 2024, the weaknesses were addressed by SAP as of May 15, 2024.
In a nutshell, the flaws make it possible to obtain unauthorized access to customers' private artifacts and credentials to cloud environments like Amazon Web Services (AWS), Microsoft Azure, and SAP HANA Cloud.
They could also be used to modify Docker images on SAP's internal container registry, SAP's Docker images on the Google Container Registry, and artifacts hosted on SAP's internal Artifactory server, resulting in a supply chain attack on SAP AI Core services.
Furthermore, the access could be weaponized to gain cluster administrator privileges on SAP AI Core's Kubernetes cluster by taking advantage of the fact that the Helm package manager server was exposed to both read and write operations.
"Using this access level, an attacker could directly access other customer's Pods and steal sensitive data, such as models, datasets, and code," Ben-Sasson explained. "This access also allows attackers to interfere with customer's Pods, taint AI data and manipulate models' inference."
Wiz said the issues arise due to the platform making it feasible to run malicious AI models and training procedures without adequate isolation and sandboxing mechanisms.
"The recent security flaws in AI service providers like Hugging Face, Replicate, and SAP AI Core highlight significant vulnerabilities in their tenant isolation and segmentation implementations," Ben-Sasson told The Hacker News. "These platforms allow users to run untrusted AI models and training procedures in shared environments, increasing the risk of malicious users being able to access other users' data."
"Unlike veteran cloud providers who have vast experience with tenant-isolation practices and use robust isolation techniques like virtual machines, these newer services often lack this knowledge and rely on containerization, which offers weaker security. This underscores the need to raise awareness of the importance of tenant isolation and to push the AI service industry to harden their environments."
As a result, a threat actor could create a regular AI application on SAP AI Core, bypass network restrictions, and probe the Kubernetes Pod's internal network to obtain AWS tokens and access customer code and training datasets by exploiting misconfigurations in AWS Elastic File System (EFS) shares.
"People should be aware that AI models are essentially code. When running AI models on your own infrastructure, you could be exposed to potential supply chain attacks," Ben-Sasson said.
"Only run trusted models from trusted sources, and properly separate between external models and sensitive infrastructure. When using AI services providers, it's important to verify their tenant-isolation architecture and ensure they apply best practices."
The findings come as Netskope revealed that the growing enterprise use of generative AI has prompted organizations to use blocking controls, data loss prevention (DLP) tools, real-time coaching, and other mechanisms to mitigate risk.
"Regulated data (data that organizations have a legal duty to protect) makes up more than a third of the sensitive data being shared with generative AI (genAI) applications — presenting a potential risk to businesses of costly data breaches," the company said.
They also follow the emergence of a new cybercriminal threat group called NullBulge that has trained its sights on AI- and gaming-focused entities since April 2024 with an aim to steal sensitive data and sell compromised OpenAI API keys in underground forums while claiming to be a hacktivist crew "protecting artists around the world" against AI.
"NullBulge targets the software supply chain by weaponizing code in publicly available repositories on GitHub and Hugging Face, leading victims to import malicious libraries, or through mod packs used by gaming and modeling software," SentinelOne security researcher Jim Walter said.
"The group uses tools like AsyncRAT and XWorm before delivering LockBit payloads built using the leaked LockBit Black builder. Groups like NullBulge represent the ongoing threat of low-barrier-of-entry ransomware, combined with the evergreen effect of info-stealer infections."
Meta Halts AI Use in Brazil Following Data Protection Authority's Ban
18.7.24 AI The Hacker News
Meta has suspended the use of generative artificial intelligence (GenAI) in Brazil after the country's data protection authority issued a preliminary ban objecting to its new privacy policy.
The development was first reported by news agency Reuters.
The company said it has decided to suspend the tools while it is in talks with Brazil's National Data Protection Authority (ANPD) to address the agency's concerns over its use of GenAI technology.
Earlier this month, ANPD halted with immediate effect the social media giant's new privacy policy that granted the company access to users' personal data to train its GenAI systems.
The decision stems from "the imminent risk of serious and irreparable damage or difficult-to-repair damage to the fundamental rights of the affected data subjects," the agency said.
It further set a daily fine of 50,000 reais (about $9,100 as of July 18) in case of non-compliance. Last week, it gave Meta "five more days to prove compliance with the decision."
In response, Meta said it was "disappointed" by ANPD's decision and that the move constitutes "a step backwards for innovation, competition in AI development and further delays bringing the benefits of AI to people in Brazil."
The use of personal data to train AI systems without their express consent or knowledge has raised privacy concerns, forcing U.S.-based tech giants to pause the rollout of their tools in regions with stricter data privacy laws, such as the European Union.
The Human Rights Watch reported in June how personal photos of Brazilian children have found their way to image caption datasets like LAION-5B, exposing them to further exploitation and harm through the facilitation of malicious deepfakes.
Apple, which announced a new AI system called Apple Intelligence last month, has said it won't be bringing the features to Europe this year due to the prevailing regulatory concerns arising from the Digital Markets Act (DMA).
"We are concerned that the interoperability requirements of the DMA could force us to compromise the integrity of our products in ways that risk user privacy and data security," Apple was quoted as saying to The Wall Street Journal.
Meta has since confirmed to Axios that it will also be withholding its upcoming multimodal AI models from customers in the region because of the "unpredictable nature of the European regulatory environment."
U.S. Seizes Domains Used by AI-Powered Russian Bot Farm for Disinformation
12.7.24 AI The Hacker News
The U.S. Department of Justice (DoJ) said it seized two internet domains and searched nearly 1,000 social media accounts that Russian threat actors allegedly used to covertly spread pro-Kremlin disinformation in the country and abroad on a large scale.
"The social media bot farm used elements of AI to create fictitious social media profiles — often purporting to belong to individuals in the United States — which the operators then used to promote messages in support of Russian government objectives," the DoJ said.
The bot network, comprising 968 accounts on X, is said to be part of an elaborate scheme hatched by an employee of Russian state-owned media outlet RT (formerly Russia Today), sponsored by the Kremlin, and aided by an officer of Russia's Federal Security Service (FSB), who created and led an unnamed private intelligence organization.
The developmental efforts for the bot farm began in April 2022 when the individuals procured online infrastructure while anonymizing their identities and locations. The goal of the organization, per the DoJ, was to further Russian interests by spreading disinformation through fictitious online personas representing various nationalities.
The phony social media accounts were registered using private email servers that relied on two domains – mlrtr[.]com and otanmail[.]com – that were purchased from domain registrar Namecheap. X has since suspended the bot accounts for violating its terms of service.
The information operation -- which targeted the U.S., Poland, Germany, the Netherlands, Spain, Ukraine, and Israel -- was pulled off using an AI-powered software package dubbed Meliorator that facilitated the "en masse" creation and operation of said social media bot farm.
"Using this tool, RT affiliates disseminated disinformation to and about a number of countries, including the United States, Poland, Germany, the Netherlands, Spain, Ukraine, and Israel," law enforcement agencies from Canada, the Netherlands, and the U.S. said.
Meliorator includes an administrator panel called Brigadir and a backend tool called Taras, which is used to control the authentic-appearing accounts, whose profile pictures and biographical information were generated using an open-source program called Faker.
Each of these accounts had a distinct identity or "soul" based on one of the three bot archetypes: Those that propagate political ideologies favorable to the Russian government, like already shared messaging by other bots, and perpetuate disinformation shared by both bot and non-bot accounts.
While the software package was only identified on X, further analysis has revealed the threat actors' intentions to extend its functionality to cover other social media platforms.
Furthermore, the system slipped through X's safeguards for verifying the authenticity of users by automatically copying one-time passcodes sent to the registered email addresses and assigning proxy IP addresses to AI-generated personas based on their assumed location.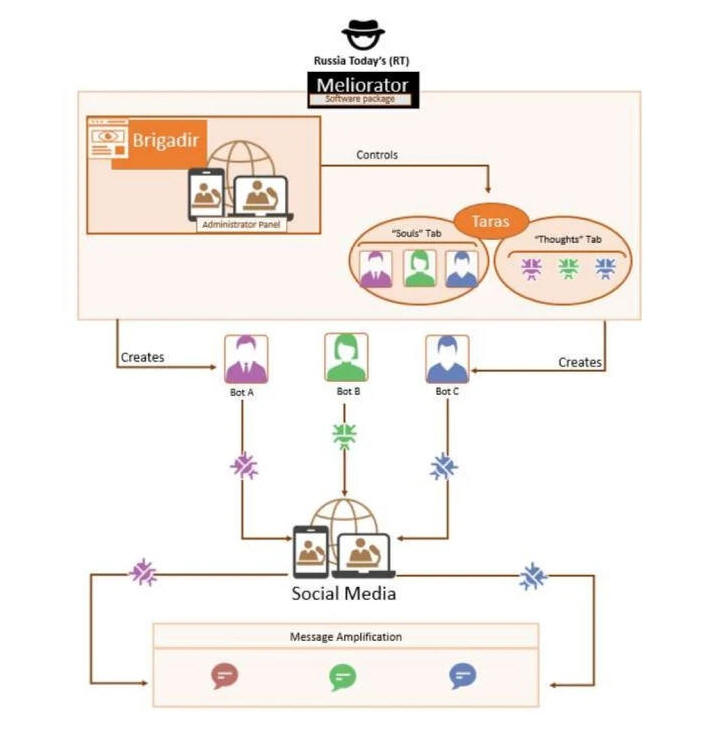
"Bot persona accounts make obvious attempts to avoid bans for terms of service violations and avoid being noticed as bots by blending into the larger social media environment," the agencies said. "Much like authentic accounts, these bots follow genuine accounts reflective of their political leanings and interests listed in their biography."
"Farming is a beloved pastime for millions of Russians," RT was quoted as saying to Bloomberg in response to the allegations, without directly refuting them.
The development marks the first time the U.S. has publicly pointed fingers at a foreign government for using AI in a foreign influence operation. No criminal charges have been made public in the case, but an investigation into the activity remains ongoing.
Doppelganger Lives On#
In recent months Google, Meta, and OpenAI have warned that Russian disinformation operations, including those orchestrated by a network dubbed Doppelganger, have repeatedly leveraged their platforms to disseminate pro-Russian propaganda.
"The campaign is still active as well as the network and server infrastructure responsible for the content distribution," Qurium and EU DisinfoLab said in a new report published Thursday.
"Astonishingly, Doppelganger does not operate from a hidden data center in a Vladivostok Fortress or from a remote military Bat cave but from newly created Russian providers operating inside the largest data centers in Europe. Doppelganger operates in close association with cybercriminal activities and affiliate advertisement networks."
At the heart of the operation is a network of bulletproof hosting providers encompassing Aeza, Evil Empire, GIR, and TNSECURITY, which have also harbored command-and-control domains for different malware families like Stealc, Amadey, Agent Tesla, Glupteba, Raccoon Stealer, RisePro, RedLine Stealer, RevengeRAT, Lumma, Meduza, and Mystic.
What's more, NewsGuard, which provides a host of tools to counter misinformation, recently found that popular AI chatbots are prone to repeating "fabricated narratives from state-affiliated sites masquerading as local news outlets in one third of their responses."
Influence Operations from Iran and China#
It also comes as the U.S. Office of the Director of National Intelligence (ODNI) said that Iran is "becoming increasingly aggressive in their foreign influence efforts, seeking to stoke discord and undermine confidence in our democratic institutions."
The agency further noted that the Iranian actors continue to refine their cyber and influence activities, using social media platforms and issuing threats, and that they are amplifying pro-Gaza protests in the U.S. by posing as activists online.
Google, for its part, said it blocked in the first quarter of 2024 over 10,000 instances of Dragon Bridge (aka Spamouflage Dragon) activity, which is the name given to a spammy-yet-persistent influence network linked to China, across YouTube and Blogger that promoted narratives portraying the U.S. in a negative light as well as content related to the elections in Taiwan and the Israel-Hamas war targeting Chinese speakers.
In comparison, the tech giant disrupted no less than 50,000 such instances in 2022 and 65,000 more in 2023. In all, it has prevented over 175,000 instances to date during the network's lifetime.
"Despite their continued profuse content production and the scale of their operations, DRAGONBRIDGE achieves practically no organic engagement from real viewers," Threat Analysis Group (TAG) researcher Zak Butler said. "In the cases where DRAGONBRIDGE content did receive engagement, it was almost entirely inauthentic, coming from other DRAGONBRIDGE accounts and not from authentic users."
Brazil Halts Meta's AI Data Processing Amid Privacy Concerns
4.7.24 AI The Hacker News
Brazil's data protection authority, Autoridade Nacional de Proteção de Dados (ANPD), has temporarily banned Meta from processing users' personal data to train the company's artificial intelligence (AI) algorithms.
The ANPD said it found "evidence of processing of personal data based on inadequate legal hypothesis, lack of transparency, limitation of the rights of data subjects, and risks to children and adolescents."
Cybersecurity
The decision follows the social media giant's update to its terms that allow it to use public content from Facebook, Messenger, and Instagram for AI training purposes.
A recent report published by Human Rights Watch found that LAION-5B, one of the largest image-text datasets used to train AI models, contained links to identifiable photos of Brazilian children, putting them at risk of malicious deepfakes that could place them under even more exploitation and harm.
Brazil has about 102 million active users, making it one of the largest markets. The ANPD noted the Meta update violates the General Personal Data Protection Law (LGBD) and has "the imminent risk of serious and irreparable or difficult-to-repair damage to the fundamental rights of the affected data subjects."
Meta has five working days to comply with the order, or risk facing daily fines of 50,000 reais (approximately $8,808).
In a statement shared with the Associated Press, the company said the policy "complies with privacy laws and regulations in Brazil," and that the ruling is "a step backwards for innovation, competition in AI development and further delays bringing the benefits of AI to people in Brazil."
Cybersecurity
The social media firm has received similar pushback in the European Union (E.U.), forcing it to pause plans to train its AI models using data from users in the region without getting explicit consent from users.
Last week, Meta's president of global affairs, Nick Clegg, said that the E.U. was losing "fertile ground for innovation" by coming down too hard on tech companies.
Prompt Injection Flaw in Vanna AI Exposes Databases to RCE Attacks
28.6.24 AI The Hacker News
Cybersecurity researchers have disclosed a high-severity security flaw in the Vanna.AI library that could be exploited to achieve remote code execution vulnerability via prompt injection techniques.
The vulnerability, tracked as CVE-2024-5565 (CVSS score: 8.1), relates to a case of prompt injection in the "ask" function that could be exploited to trick the library into executing arbitrary commands, supply chain security firm JFrog said.
Vanna is a Python-based machine learning library that allows users to chat with their SQL database to glean insights by "just asking questions" (aka prompts) that are translated into an equivalent SQL query using a large language model (LLM).
The rapid rollout of generative artificial intelligence (AI) models in recent years has brought to the fore the risks of exploitation by malicious actors, who can weaponize the tools by providing adversarial inputs that bypass the safety mechanisms built into them.
One such prominent class of attacks is prompt injection, which refers to a type of AI jailbreak that can be used to disregard guardrails erected by LLM providers to prevent the production of offensive, harmful, or illegal content, or carry out instructions that violate the intended purpose of the application.
Cybersecurity
Such attacks can be indirect, wherein a system processes data controlled by a third party (e.g., incoming emails or editable documents) to launch a malicious payload that leads to an AI jailbreak.
They can also take the form of what's called a many-shot jailbreak or multi-turn jailbreak (aka Crescendo) in which the operator "starts with harmless dialogue and progressively steers the conversation toward the intended, prohibited objective."
This approach can be extended further to pull off another novel jailbreak attack known as Skeleton Key.
"This AI jailbreak technique works by using a multi-turn (or multiple step) strategy to cause a model to ignore its guardrails," Mark Russinovich, chief technology officer of Microsoft Azure, said. "Once guardrails are ignored, a model will not be able to determine malicious or unsanctioned requests from any other."
Skeleton Key is also different from Crescendo in that once the jailbreak is successful and the system rules are changed, the model can create responses to questions that would otherwise be forbidden regardless of the ethical and safety risks involved.
"When the Skeleton Key jailbreak is successful, a model acknowledges that it has updated its guidelines and will subsequently comply with instructions to produce any content, no matter how much it violates its original responsible AI guidelines," Russinovich said.
"Unlike other jailbreaks like Crescendo, where models must be asked about tasks indirectly or with encodings, Skeleton Key puts the models in a mode where a user can directly request tasks. Further, the model's output appears to be completely unfiltered and reveals the extent of a model's knowledge or ability to produce the requested content."
The latest findings from JFrog – also independently disclosed by Tong Liu – show how prompt injections could have severe impacts, particularly when they are tied to command execution.
CVE-2024-5565 takes advantage of the fact that Vanna facilitates text-to-SQL Generation to create SQL queries, which are then executed and graphically presented to the users using the Plotly graphing library.
This is accomplished by means of an "ask" function – e.g., vn.ask("What are the top 10 customers by sales?") – which is one of the main API endpoints that enables the generation of SQL queries to be run on the database.
Cybersecurity
The aforementioned behavior, coupled with the dynamic generation of the Plotly code, creates a security hole that allows a threat actor to submit a specially crafted prompt embedding a command to be executed on the underlying system.
"The Vanna library uses a prompt function to present the user with visualized results, it is possible to alter the prompt using prompt injection and run arbitrary Python code instead of the intended visualization code," JFrog said.
"Specifically, allowing external input to the library's 'ask' method with 'visualize' set to True (default behavior) leads to remote code execution."
Following responsible disclosure, Vanna has issued a hardening guide that warns users that the Plotly integration could be used to generate arbitrary Python code and that users exposing this function should do so in a sandboxed environment.
"This discovery demonstrates that the risks of widespread use of GenAI/LLMs without proper governance and security can have drastic implications for organizations," Shachar Menashe, senior director of security research at JFrog, said in a statement.
"The dangers of prompt injection are still not widely well known, but they are easy to execute. Companies should not rely on pre-prompting as an infallible defense mechanism and should employ more robust mechanisms when interfacing LLMs with critical resources such as databases or dynamic code generation."
Google Introduces Project Naptime for AI-Powered Vulnerability Research
25.6.24 AI The Hacker News
Google has developed a new framework called Project Naptime that it says enables a large language model (LLM) to carry out vulnerability research with an aim to improve automated discovery approaches.
"The Naptime architecture is centered around the interaction between an AI agent and a target codebase," Google Project Zero researchers Sergei Glazunov and Mark Brand said. "The agent is provided with a set of specialized tools designed to mimic the workflow of a human security researcher."
The initiative is so named for the fact that it allows humans to "take regular naps" while it assists with vulnerability research and automating variant analysis.
The approach, at its core, seeks to take advantage of advances in code comprehension and general reasoning ability of LLMs, thus allowing them to replicate human behavior when it comes to identifying and demonstrating security vulnerabilities.
It encompasses several components such as a Code Browser tool that enables the AI agent to navigate through the target codebase, a Python tool to run Python scripts in a sandboxed environment for fuzzing, a Debugger tool to observe program behavior with different inputs, and a Reporter tool to monitor the progress of a task.
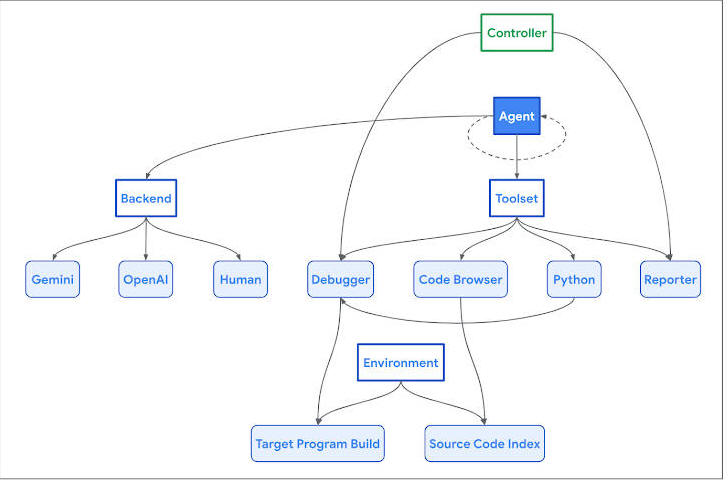
Google said Naptime is also model-agnostic and backend-agnostic, not to mention be better at flagging buffer overflow and advanced memory corruption flaws, according to CYBERSECEVAL 2 benchmarks. CYBERSECEVAL 2, released earlier this April by researchers from Meta, is an evaluation suite to quantify LLM security risks.
In tests carried out by the search giant to reproduce and exploit the flaws, the two vulnerability categories achieved new top scores of 1.00 and 0.76, up from 0.05 and 0.24, respectively for OpenAI GPT-4 Turbo.
"Naptime enables an LLM to perform vulnerability research that closely mimics the iterative, hypothesis-driven approach of human security experts," the researchers said. "This architecture not only enhances the agent's ability to identify and analyze vulnerabilities but also ensures that the results are accurate and reproducible."
U.S. Government Releases New AI Security Guidelines for Critical Infrastructure
30.4.24 AI The Hacker News
The U.S. government has unveiled new security guidelines aimed at bolstering critical infrastructure against artificial intelligence (AI)-related threats.
"These guidelines are informed by the whole-of-government effort to assess AI risks across all sixteen critical infrastructure sectors, and address threats both to and from, and involving AI systems," the Department of Homeland Security (DHS) said Monday.
In addition, the agency said it's working to facilitate safe, responsible, and trustworthy use of the technology in a manner that does not infringe on individuals' privacy, civil rights, and civil liberties.
The new guidance concerns the use of AI to augment and scale attacks on critical infrastructure, adversarial manipulation of AI systems, and shortcomings in such tools that could result in unintended consequences, necessitating the need for transparency and secure by design practices to evaluate and mitigate AI risks.
Specifically, this spans four different functions such as govern, map, measure, and manage all through the AI lifecycle -
Establish an organizational culture of AI risk management
Understand your individual AI use context and risk profile
Develop systems to assess, analyze, and track AI risks
Prioritize and act upon AI risks to safety and security
"Critical infrastructure owners and operators should account for their own sector-specific and context-specific use of AI when assessing AI risks and selecting appropriate mitigations," the agency said.
"Critical infrastructure owners and operators should understand where these dependencies on AI vendors exist and work to share and delineate mitigation responsibilities accordingly."
The development arrives weeks after the Five Eyes (FVEY) intelligence alliance comprising Australia, Canada, New Zealand, the U.K., and the U.S. released a cybersecurity information sheet noting the careful setup and configuration required for deploying AI systems.
"The rapid adoption, deployment, and use of AI capabilities can make them highly valuable targets for malicious cyber actors," the governments said.
"Actors, who have historically used data theft of sensitive information and intellectual property to advance their interests, may seek to co-opt deployed AI systems and apply them to malicious ends."
The recommended best practices include taking steps to secure the deployment environment, review the source of AI models and supply chain security, ensure a robust deployment environment architecture, harden deployment environment configurations, validate the AI system to ensure its integrity, protect model weights, enforce strict access controls, conduct external audits, and implement robust logging.
Earlier this month, the CERT Coordination Center (CERT/CC) detailed a shortcoming in the Keras 2 neural network library that could be exploited by an attacker to trojanize a popular AI model and redistribute it, effectively poisoning the supply chain of dependent applications.
Recent research has found AI systems to be vulnerable to a wide range of prompt injection attacks that induce the AI model to circumvent safety mechanisms and produce harmful outputs.
"Prompt injection attacks through poisoned content are a major security risk because an attacker who does this can potentially issue commands to the AI system as if they were the user," Microsoft noted in a recent report.
One such technique, dubbed Crescendo, has been described as a multiturn large language model (LLM) jailbreak, which, like Anthropic's many-shot jailbreaking, tricks the model into generating malicious content by "asking carefully crafted questions or prompts that gradually lead the LLM to a desired outcome, rather than asking for the goal all at once."
LLM jailbreak prompts have become popular among cybercriminals looking to craft effective phishing lures, even as nation-state actors have begun weaponizing generative AI to orchestrate espionage and influence operations.
Even more concerningly, studies from the University of Illinois Urbana-Champaign has discovered that LLM agents can be put to use to autonomously exploit one-day vulnerabilities in real-world systems simply using their CVE descriptions and "hack websites, performing tasks as complex as blind database schema extraction and SQL injections without human feedback."
AI-as-a-Service Providers Vulnerable to PrivEsc and Cross-Tenant Attacks
7.4.24 AI The Hacker News
New research has found that artificial intelligence (AI)-as-a-service providers such as Hugging Face are susceptible to two critical risks that could allow threat actors to escalate privileges, gain cross-tenant access to other customers' models, and even take over the continuous integration and continuous deployment (CI/CD) pipelines.
"Malicious models represent a major risk to AI systems, especially for AI-as-a-service providers because potential attackers may leverage these models to perform cross-tenant attacks," Wiz researchers Shir Tamari and Sagi Tzadik said.
"The potential impact is devastating, as attackers may be able to access the millions of private AI models and apps stored within AI-as-a-service providers."
The development comes as machine learning pipelines have emerged as a brand new supply chain attack vector, with repositories like Hugging Face becoming an attractive target for staging adversarial attacks designed to glean sensitive information and access target environments.
The threats are two-pronged, arising as a result of shared inference infrastructure takeover and shared CI/CD takeover. They make it possible to run untrusted models uploaded to the service in pickle format and take over the CI/CD pipeline to perform a supply chain attack.
The findings from the cloud security firm show that it's possible to breach the service running the custom models by uploading a rogue model and leverage container escape techniques to break out from its own tenant and compromise the entire service, effectively enabling threat actors to obtain cross-tenant access to other customers' models stored and run in Hugging Face.
"Hugging Face will still let the user infer the uploaded Pickle-based model on the platform's infrastructure, even when deemed dangerous," the researchers elaborated.
This essentially permits an attacker to craft a PyTorch (Pickle) model with arbitrary code execution capabilities upon loading and chain it with misconfigurations in the Amazon Elastic Kubernetes Service (EKS) to obtain elevated privileges and laterally move within the cluster.
"The secrets we obtained could have had a significant impact on the platform if they were in the hands of a malicious actor," the researchers said. "Secrets within shared environments may often lead to cross-tenant access and sensitive data leakage.
To mitigate the issue, it's recommended to enable IMDSv2 with Hop Limit so as to prevent pods from accessing the Instance Metadata Service (IMDS) and obtaining the role of a Node within the cluster. The research also found that it's possible to achieve remote code execution via a specially crafted Dockerfile when running an application on the Hugging Face Spaces service, and use it to pull and push (i.e., overwrite) all the images that are available on an internal container registry. Hugging Face, in coordinated disclosure, said it has addressed all the identified issues. It's also urging users to employ models only from trusted sources, enable multi-factor authentication (MFA), and refrain from using pickle files in production environments. "This research demonstrates that utilizing untrusted AI models (especially Pickle-based ones) could result in serious security consequences," the researchers said. "Furthermore, if you intend to let users utilize untrusted AI models in your environment, it is extremely important to ensure that they are running in a sandboxed environment." The disclosure follows another research from Lasso Security that it's possible for generative AI models like OpenAI ChatGPT and Google Gemini to distribute malicious (and non-existant) code packages to unsuspecting software developers. In other words, the idea is to find a recommendation for an unpublished package and publish a trojanized package in its place in order to propagate the malware. The phenomenon of AI package hallucinations underscores the need for exercising caution when relying on large language models (LLMs) for coding solutions. AI company Anthropic, for its part, has also detailed a new method called "many-shot jailbreaking" that can be used to bypass safety protections built into LLMs to produce responses to potentially harmful queries by taking advantage of the models' context window. "The ability to input increasingly-large amounts of information has obvious advantages for LLM users, but it also comes with risks: vulnerabilities to jailbreaks that exploit the longer context window," the company said earlier this week. The technique, in a nutshell, involves introducing a large number of faux dialogues between a human and an AI assistant within a single prompt for the LLM in an attempt to "steer model behavior" and respond to queries that it wouldn't otherwise (e.g., "How do I build a bomb?").
GitHub Launches AI-Powered Autofix Tool to Assist Devs in Patching Security Flaws
21.3.24 AI The Hacker News
GitHub on Wednesday announced that it's making available a feature called code scanning autofix in public beta for all Advanced Security customers to provide targeted recommendations in an effort to avoid introducing new security issues.
"Powered by GitHub Copilot and CodeQL, code scanning autofix covers more than 90% of alert types in JavaScript, Typescript, Java, and Python, and delivers code suggestions shown to remediate more than two-thirds of found vulnerabilities with little or no editing," GitHub's Pierre Tempel and Eric Tooley said.
The capability, first previewed in November 2023, leverages a combination of CodeQL, Copilot APIs, and OpenAI GPT-4 to generate code suggestions. The Microsoft-owned subsidiary also said it plans to add support for more programming languages, including C# and Go, in the future.
Code scanning autofix is designed to help developers resolve vulnerabilities as they code by generating potential fixes as well as providing a natural language explanation when an issue is discovered in a supported language.
These suggestions could go beyond the current file to include changes to several other files and the dependencies that should be added to rectify the problem.
"Code scanning autofix lowers the barrier of entry to developers by combining information on best practices with details of the codebase and alert to suggest a potential fix to the developer," the company said.
"Instead of starting with a search for information about the vulnerability, the developer starts with a code suggestion that demonstrates a potential solution for their codebase."
That said, it's left to the developer to evaluate the recommendations and determine if it's the right solution and ensure that it does not deviate from its intended behavior. GitHub also emphasized the current limitations of the autofix code suggestions, making it imperative that developers carefully review the changes and the dependencies before accepting them - Suggest fixes that are not syntactically correct code changes
Suggest fixes that are syntactically correct code but are suggested at the incorrect location
Suggest fixes that are syntactically valid but that change the semantics of the program
Suggest fixes that are fail to address the root cause, or introduce new vulnerabilities
Suggest fixes that only partially resolve the underlying flaw
Suggest unsupported or insecure dependencies
Suggest arbitrary dependencies, leading to possible supply chain attacks
"The system has incomplete knowledge of the dependencies published in the wider ecosystem," the company noted. "This can lead to suggestions that add a new dependency on malicious software that attackers have published under a statistically probable dependency name."
From Deepfakes to Malware: AI's Expanding Role in Cyber Attacks
19.3.24 AI The Hacker News
Large language models (LLMs) powering artificial intelligence (AI) tools today could be exploited to develop self-augmenting malware capable of bypassing YARA rules.
"Generative AI can be used to evade string-based YARA rules by augmenting the source code of small malware variants, effectively lowering detection rates," Recorded Future said in a new report shared with The Hacker News.
The findings are part of a red teaming exercise designed to uncover malicious use cases for AI technologies, which are already being experimented with by threat actors to create malware code snippets, generate phishing emails, and conduct reconnaissance on potential targets.
The cybersecurity firm said it submitted to an LLM a known piece of malware called STEELHOOK that's associated with the APT28 hacking group, alongside its YARA rules, asking it to modify the source code to sidestep detection such the original functionality remained intact and the generated source code was syntactically free of errors.
Armed with this feedback mechanism, the altered malware generated by the LLM made it possible to avoid detections for simple string-based YARA rules.
There are limitations to this approach, the most prominent being the amount of text a model can process as input at one time, which makes it difficult to operate on larger code bases.
Besides modifying malware to fly under the radar, such AI tools could be used to create deepfakes impersonating senior executives and leaders and conduct influence operations that mimic legitimate websites at scale.
Furthermore, generative AI is expected to expedite threat actors' ability to carry out reconnaissance of critical infrastructure facilities and glean information that could be of strategic use in follow-on attacks.
"By leveraging multimodal models, public images and videos of ICS and manufacturing equipment, in addition to aerial imagery, can be parsed and enriched to find additional metadata such as geolocation, equipment manufacturers, models, and software versioning," the company said.
Indeed, Microsoft and OpenAI warned last month that APT28 used LLMs to "understand satellite communication protocols, radar imaging technologies, and specific technical parameters," indicating efforts to "acquire in-depth knowledge of satellite capabilities."
It's recommended that organizations scrutinize publicly accessible images and videos depicting sensitive equipment and scrub them, if necessary, to mitigate the risks posed by such threats.
The development comes as a group of academics have found that it's possible to jailbreak LLM-powered tools and produce harmful content by passing inputs in the form of ASCII art (e.g., "how to build a bomb," where the word BOMB is written using characters "*" and spaces).
The practical attack, dubbed ArtPrompt, weaponizes "the poor performance of LLMs in recognizing ASCII art to bypass safety measures and elicit undesired behaviors from LLMs."
Third-Party ChatGPT Plugins Could Lead to Account Takeovers
15.3.24 AI The Hacker News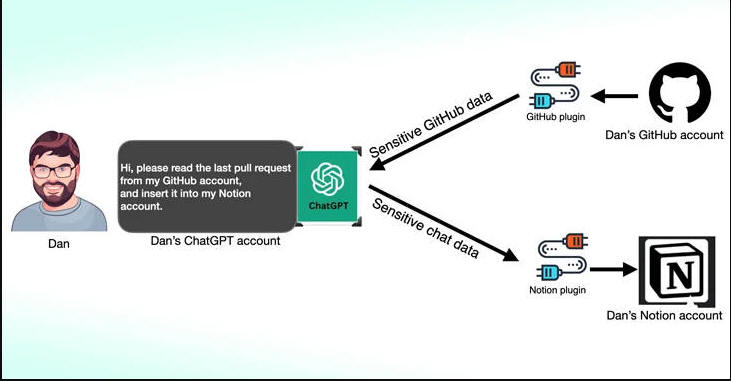
Cybersecurity researchers have found that third-party plugins available for OpenAI ChatGPT could act as a new attack surface for threat actors looking to gain unauthorized access to sensitive data.
According to new research published by Salt Labs, security flaws found directly in ChatGPT and within the ecosystem could allow attackers to install malicious plugins without users' consent and hijack accounts on third-party websites like GitHub.
ChatGPT plugins, as the name implies, are tools designed to run on top of the large language model (LLM) with the aim of accessing up-to-date information, running computations, or accessing third-party services.
OpenAI has since also introduced GPTs, which are bespoke versions of ChatGPT tailored for specific use cases, while reducing third-party service dependencies. As of March 19, 2024, ChatGPT users will no longer be able to install new plugins or create new conversations with existing plugins.
One of the flaws unearthed by Salt Labs involves exploiting the OAuth workflow to trick a user into installing an arbitrary plugin by taking advantage of the fact that ChatGPT doesn't validate that the user indeed started the plugin installation.
This effectively could allow threat actors to intercept and exfiltrate all data shared by the victim, which may contain proprietary information.
The cybersecurity firm also unearthed issues with PluginLab that could be weaponized by threat actors to conduct zero-click account takeover attacks, allowing them to gain control of an organization's account on third-party websites like GitHub and access their source code repositories.
"'auth.pluginlab[.]ai/oauth/authorized' does not authenticate the request, which means that the attacker can insert another memberId (aka the victim) and get a code that represents the victim," security researcher Aviad Carmel explained. "With that code, he can use ChatGPT and access the GitHub of the victim."
The memberId of the victim can be obtained by querying the endpoint "auth.pluginlab[.]ai/members/requestMagicEmailCode." There is no evidence that any user data has been compromised using the flaw.
Also discovered in several plugins, including Kesem AI, is an OAuth redirection manipulation bug that could permit an attacker to steal the account credentials associated with the plugin itself by sending a specially crafted link to the victim.
The development comes weeks after Imperva detailed two cross-site scripting (XSS) vulnerabilities in ChatGPT that could be chained to seize control of any account.
In December 2023, security researcher Johann Rehberger demonstrated how malicious actors could create custom GPTs that can phish for user credentials and transmit the stolen data to an external server.
New Remote Keylogging Attack on AI Assistants# "LLMs generate and send responses as a series of tokens (akin to words), with each token transmitted from the server to the user as it is generated," a group of academics from the Ben-Gurion University and Offensive AI Research Lab said. "While this process is encrypted, the sequential token transmission exposes a new side-channel: the token-length side-channel. Despite encryption, the size of the packets can reveal the length of the tokens, potentially allowing attackers on the network to infer sensitive and confidential information shared in private AI assistant conversations." This is accomplished by means of a token inference attack that's designed to decipher responses in encrypted traffic by training an LLM model capable of translating token-length sequences into their natural language sentential counterparts (i.e., plaintext). In other words, the core idea is to intercept the real-time chat responses with an LLM provider, use the network packet headers to infer the length of each token, extract and parse text segments, and leverage the custom LLM to infer the response. To counteract the effectiveness of the side-channel attack, it's recommended that companies that develop AI assistants apply random padding to obscure the actual length of tokens, transmit tokens in larger groups rather than individually, and send complete responses at once, instead of in a token-by-token fashion. "Balancing security with usability and performance presents a complex challenge that requires careful consideration," the researchers concluded.
The findings also follow new research published this week about an LLM side-channel attack that employs token-length as a covert means to extract encrypted responses from AI Assistants over the web.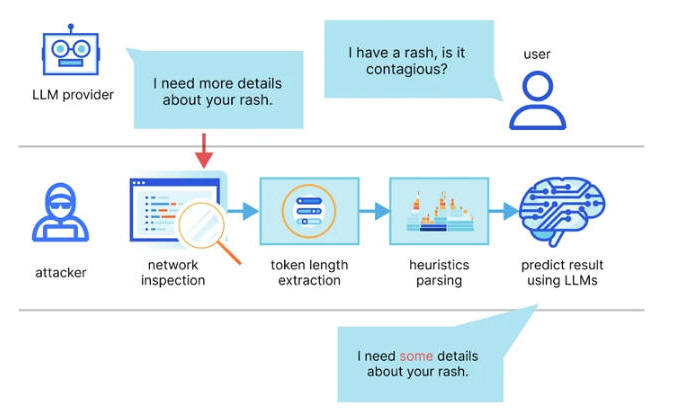
Two key prerequisites to pulling off the attack are an AI chat client running in streaming mode and an adversary who is capable of capturing network traffic between the client and the AI chatbot.
Researchers Highlight Google's Gemini AI Susceptibility to LLM Threats
13.3.24 AI The Hacker News
Google's Gemini large language model (LLM) is susceptible to security threats that could cause it to divulge system prompts, generate harmful content, and carry out indirect injection attacks.
The findings come from HiddenLayer, which said the issues impact consumers using Gemini Advanced with Google Workspace as well as companies using the LLM API.
The first vulnerability involves getting around security guardrails to leak the system prompts (or a system message), which are designed to set conversation-wide instructions to the LLM to help it generate more useful responses, by asking the model to output its "foundational instructions" in a markdown block.
"A system message can be used to inform the LLM about the context," Microsoft notes in its documentation about LLM prompt engineering.
"The context may be the type of conversation it is engaging in, or the function it is supposed to perform. It helps the LLM generate more appropriate responses."
This is made possible due to the fact that models are susceptible to what's called a synonym attack to circumvent security defenses and content restrictions.
A second class of vulnerabilities relates to using "crafty jailbreaking" techniques to make the Gemini models generate misinformation surrounding topics like elections as well as output potentially illegal and dangerous information (e.g., hot-wiring a car) using a prompt that asks it to enter into a fictional state.
Also identified by HiddenLayer is a third shortcoming that could cause the LLM to leak information in the system prompt by passing repeated uncommon tokens as input.
"Most LLMs are trained to respond to queries with a clear delineation between the user's input and the system prompt," security researcher Kenneth Yeung said in a Tuesday report.
"By creating a line of nonsensical tokens, we can fool the LLM into believing it is time for it to respond and cause it to output a confirmation message, usually including the information in the prompt."
Another test involves using Gemini Advanced and a specially crafted Google document, with the latter connected to the LLM via the Google Workspace extension.
The instructions in the document could be designed to override the model's instructions and perform a set of malicious actions that enable an attacker to have full control of a victim's interactions with the model.
The disclosure comes as a group of academics from Google DeepMind, ETH Zurich, University of Washington, OpenAI, and the McGill University revealed a novel model-stealing attack that makes it possible to extract "precise, nontrivial information from black-box production language models like OpenAI's ChatGPT or Google's PaLM-2."
That said, it's worth noting that these vulnerabilities are not novel and are present in other LLMs across the industry. The findings, if anything, emphasize the need for testing models for prompt attacks, training data extraction, model manipulation, adversarial examples, data poisoning and exfiltration.
"To help protect our users from vulnerabilities, we consistently run red-teaming exercises and train our models to defend against adversarial behaviors like prompt injection, jailbreaking, and more complex attacks," a Google spokesperson told The Hacker News. "We've also built safeguards to prevent harmful or misleading responses, which we are continuously improving."
The company also said it's restricting responses to election-based queries out of an abundance of caution. The policy is expected to be enforced against prompts regarding candidates, political parties, election results, voting information, and notable office holders.
Ex-Google Engineer Arrested for Stealing AI Technology Secrets for China
7.3.24 AI The Hacker News
The U.S. Department of Justice (DoJ) announced the indictment of a 38-year-old Chinese national and a California resident of allegedly stealing proprietary information from Google while covertly working for two China-based tech companies.
Linwei Ding (aka Leon Ding), a former Google engineer who was arrested on March 6, 2024, "transferred sensitive Google trade secrets and other confidential information from Google's network to his personal account while secretly affiliating himself with PRC-based companies in the AI industry," the DoJ said.
The defendant is said to have pilfered from Google over 500 confidential files containing artificial intelligence (AI) trade secrets with the goal of passing them on to two unnamed Chinese companies looking to gain an edge in the ongoing AI race.
"While Linwei Ding was employed as a software engineer at Google, he was secretly working to enrich himself and two companies based in the People's Republic of China," said U.S. Attorney Ismail Ramsey.
"By stealing Google's trade secrets about its artificial intelligence supercomputing systems, Ding gave himself and the companies that he affiliated with in the PRC an unfair competitive advantage."
Ding, who joined Google as a software engineer in 2019, has been accused of siphoning proprietary information related to the company's supercomputing data center infrastructure used for running AI models, the Cluster Management System (CMS) software for managing the data centers, and the AI models and applications they supported.
The theft happened from May 21, 2022, until May 2, 2023, to a personal Google Cloud account, the indictment alleged, adding Ding secretly affiliated himself with two tech companies based in China.
This included one firm in which he was offered the position of chief technology officer sometime around June 2022 and another company founded by Ding himself by no later than May 30, 2023, acting as its chief executive officer.
"Ding's company touted the development of a software platform designed to accelerate machine learning workloads, including training large AI models," the DoJ said.
"A document related to Ding's startup company stated, 'we have experience with Google's ten-thousand-card computational power platform; we just need to replicate and upgrade it – and then further develop a computational power platform suited to China's national conditions.'"
But in an interesting twist, Ding took steps to conceal the theft of trade secrets by purportedly copying the data from Google source files into the Apple Notes application on his company-provided MacBook and then converting the notes to PDF files before uploading them to their Google account.
Furthermore, Ding allegedly allowed another Google employee in December 2023 to use his Google-issued access badge to scan into the entrance of a Google building, giving the impression that he was working from his U.S. Google office when, in fact, he was in China. He resigned from Google on December 26, 2023.
Ding has been charged with four counts of theft of trade secrets. If convicted, he faces a maximum penalty of 10 years in prison and up to a $250,000 fine for each count.
The development comes days after the DoJ arrested and indicted David Franklin Slater, a civilian employee of the U.S. Air Force assigned to the U.S. Strategic Command (USSTRATCOM), of transmitting classified information on a foreign online dating platform between February and April 2022.
The information included National Defense Information (NDI) pertaining to military targets and Russian military capabilities relating to Russia's invasion of Ukraine. It's said to have been sent to a co-conspirator, who claimed to be a female living in Ukraine, via the dating website's messaging feature.
"Slater willfully, improperly, and unlawfully transmitted NDI classified as 'SECRET,' which he had reason to believe could be used to the injury of the United States or to the advantage of a foreign nation, on a foreign online dating platform to a person not authorized to receive such information," the DoJ said.
Slater, 63, faces up to 10 years in prison, three years of supervised release, and a maximum monetary penalty of $250,000 for each count of conspiracy to transmit and the transmission of NDI. No details are known about the motives or the real identity of the individual posing as a Ukrainian woman.
Over 225,000 Compromised ChatGPT Credentials Up for Sale on Dark Web Markets
5.3.24 AI The Hacker News
More than 225,000 logs containing compromised OpenAI ChatGPT credentials were made available for sale on underground markets between January and October 2023, new findings from Group-IB show.
These credentials were found within information stealer logs associated with LummaC2, Raccoon, and RedLine stealer malware.
"The number of infected devices decreased slightly in mid- and late summer but grew significantly between August and September," the Singapore-headquartered cybersecurity company said in its Hi-Tech Crime Trends 2023/2024 report published last week.
Between June and October 2023, more than 130,000 unique hosts with access to OpenAI ChatGPT were infiltrated, a 36% increase over what was observed during the first five months of 2023. The breakdown by the top three stealer families is below -
LummaC2 - 70,484 hosts
Raccoon - 22,468 hosts
RedLine - 15,970 hosts
"The sharp increase in the number of ChatGPT credentials for sale is due to the overall rise in the number of hosts infected with information stealers, data from which is then put up for sale on markets or in UCLs," Group-IB said.
The development comes as Microsoft and OpenAI revealed that nation-state actors from Russia, North Korea, Iran, and China are experimenting with artificial intelligence (AI) and large language models (LLMs) to complement their ongoing cyber attack operations.

Stating that LLMs can be used by adversaries to brainstorm new tradecraft, craft convincing scam and phishing attacks, and improve operational productivity, Group-IB said the technology could also speed up reconnaissance, execute hacking toolkits, and make scammer robocalls.
"In the past, [threat actors] were mainly interested in corporate computers and in systems with access that enabled movement across the network," it noted. "Now, they also focus on devices with access to public AI systems.
"This gives them access to logs with the communication history between employees and systems, which they can use to search for confidential information (for espionage purposes), details about internal infrastructure, authentication data (for conducting even more damaging attacks), and information about application source code."
Abuse of valid account credentials by threat actors has emerged as a top access technique, primarily fueled by the easy availability of such information via stealer malware.
"The combination of a rise in infostealers and the abuse of valid account credentials to gain initial access has exacerbated defenders' identity and access management challenges," IBM X-Force said.
"Enterprise credential data can be stolen from compromised devices through credential reuse, browser credential stores or accessing enterprise accounts directly from personal devices."
New Hugging Face Vulnerability Exposes AI Models to Supply Chain Attacks
28.2.24 AI The Hacker News
Cybersecurity researchers have found that it's possible to compromise the Hugging Face Safetensors conversion service to ultimately hijack the models submitted by users and result in supply chain attacks.
"It's possible to send malicious pull requests with attacker-controlled data from the Hugging Face service to any repository on the platform, as well as hijack any models that are submitted through the conversion service," HiddenLayer said in a report published last week.
This, in turn, can be accomplished using a hijacked model that's meant to be converted by the service, thereby allowing malicious actors to request changes to any repository on the platform by masquerading as the conversion bot.
Hugging Face is a popular collaboration platform that helps users host pre-trained machine learning models and datasets, as well as build, deploy, and train them.
Safetensors is a format devised by the company to store tensors keeping security in mind, as opposed to pickles, which has been likely weaponized by threat actors to execute arbitrary code and deploy Cobalt Strike, Mythic, and Metasploit stagers.
It also comes with a conversion service that enables users to convert any PyTorch model (i.e., pickle) to its Safetensor equivalent via a pull request.
HiddenLayer's analysis of this module found that it's hypothetically possible for an attacker to hijack the hosted conversion service using a malicious PyTorch binary and compromise the system hosting it.
What's more, the token associated with SFConvertbot – an official bot designed to generate the pull request – could be exfiltrated to send a malicious pull request to any repository on the site, leading to a scenario where a threat actor could tamper with the model and implant neural backdoors.
"An attacker could run any arbitrary code any time someone attempted to convert their model," researchers Eoin Wickens and Kasimir Schulz noted. "Without any indication to the user themselves, their models could be hijacked upon conversion."
Should a user attempt to convert their own private repository, the attack could pave the way for the theft of their Hugging Face token, access otherwise internal models and datasets, and even poison them.
Complicating matters further, an adversary could take advantage of the fact that any user can submit a conversion request for a public repository to hijack or alter a widely used model, potentially resulting in a considerable supply chain risk.
"Despite the best intentions to secure machine learning models in the Hugging Face ecosystem, the conversion service has proven to be vulnerable and has had the potential to cause a widespread supply chain attack via the Hugging Face official service," the researchers said.
"An attacker could gain a foothold into the container running the service and compromise any model converted by the service."
The development comes a little over a month after Trail of Bits disclosed LeftoverLocals (CVE-2023-4969, CVSS score: 6.5), a vulnerability that allows recovery of data from Apple, Qualcomm, AMD, and Imagination general-purpose graphics processing units (GPGPUs).
The memory leak flaw, which stems from a failure to adequately isolate process memory, enables a local attacker to read memory from other processes, including another user's interactive session with a large language model (LLM).
"This data leaking can have severe security consequences, especially given the rise of ML systems, where local memory is used to store model inputs, outputs, and weights," security researchers Tyler Sorensen and Heidy Khlaaf said.
Google Open Sources Magika: AI-Powered File Identification Tool
17.2.24 AI The Hacker News
Google has announced that it's open-sourcing Magika, an artificial intelligence (AI)-powered tool to identify file types, to help defenders accurately detect binary and textual file types.
"Magika outperforms conventional file identification methods providing an overall 30% accuracy boost and up to 95% higher precision on traditionally hard to identify, but potentially problematic content such as VBA, JavaScript, and Powershell," the company said.
The software uses a "custom, highly optimized deep-learning model" that enables the precise identification of file types within milliseconds. Magika implements inference functions using the Open Neural Network Exchange (ONNX).
Google said it internally uses Magika at scale to help improve users' safety by routing Gmail, Drive, and Safe Browsing files to the proper security and content policy scanners.
In November 2023, the tech giant unveiled RETVec (short for Resilient and Efficient Text Vectorizer), a multilingual text processing model to detect potentially harmful content such as spam and malicious emails in Gmail.
Amid an ongoing debate on the risks of the rapidly developing technology and its abuse by nation-state actors associated with Russia, China, Iran, and North Korea to boost their hacking efforts, Google said deploying AI at scale can strengthen digital security and "tilt the cybersecurity balance from attackers to defenders."
It also emphasized the need for a balanced regulatory approach to AI usage and adoption in order to avoid a future where attackers can innovate, but defenders are restrained due to AI governance choices.
"AI allows security professionals and defenders to scale their work in threat detection, malware analysis, vulnerability detection, vulnerability fixing and incident response," the tech giant's Phil Venables and Royal Hansen noted. "AI affords the best opportunity to upend the Defender's Dilemma, and tilt the scales of cyberspace to give defenders a decisive advantage over attackers."
Concerns have also been raised about generative AI models' use of web-scraped data for training purposes, which may also include personal data.
"If you don't know what your model is going to be used for, how can you ensure its downstream use will respect data protection and people's rights and freedoms?," the U.K. Information Commissioner's Office (ICO) pointed out last month.
What's more, new research has shown that large language models can function as "sleeper agents" that may be seemingly innocuous but can be programmed to engage in deceptive or malicious behavior when specific criteria are met or special instructions are provided.
"Such backdoor behavior can be made persistent so that it is not removed by standard safety training techniques, including supervised fine-tuning, reinforcement learning, and adversarial training (eliciting unsafe behavior and then training to remove it), researchers from AI startup Anthropic said in the study.
Microsoft, OpenAI Warn of Nation-State Hackers Weaponizing AI for Cyber Attacks
17.2.24 AI The Hacker News
Nation-state actors associated with Russia, North Korea, Iran, and China are experimenting with artificial intelligence (AI) and large language models (LLMs) to complement their ongoing cyber attack operations.
The findings come from a report published by Microsoft in collaboration with OpenAI, both of which said they disrupted efforts made by five state-affiliated actors that used its AI services to perform malicious cyber activities by terminating their assets and accounts.
"Language support is a natural feature of LLMs and is attractive for threat actors with continuous focus on social engineering and other techniques relying on false, deceptive communications tailored to their targets' jobs, professional networks, and other relationships," Microsoft said in a report shared with The Hacker News.
While no significant or novel attacks employing the LLMs have been detected to date, adversarial exploration of AI technologies has transcended various phases of the attack chain, such as reconnaissance, coding assistance, and malware development.
"These actors generally sought to use OpenAI services for querying open-source information, translating, finding coding errors, and running basic coding tasks," the AI firm said.
For instance, the Russian nation-state group tracked as Forest Blizzard (aka APT28) is said to have used its offerings to conduct open-source research into satellite communication protocols and radar imaging technology, as well as for support with scripting tasks.
Some of the other notable hacking crews are listed below -
Emerald Sleet (aka Kimusky), a North Korean threat actor, has used LLMs to identify experts, think tanks, and organizations focused on defense issues in the Asia-Pacific region, understand publicly available flaws, help with basic scripting tasks, and draft content that could be used in phishing campaigns.
Crimson Sandstorm (aka Imperial Kitten), an Iranian threat actor who has used LLMs to create code snippets related to app and web development, generate phishing emails, and research common ways malware could evade detection
Charcoal Typhoon (aka Aquatic Panda), a Chinese threat actor which has used LLMs to research various companies and vulnerabilities, generate scripts, create content likely for use in phishing campaigns, and identify techniques for post-compromise behavior
Salmon Typhoon (aka Maverick Panda), a Chinese threat actor which has used LLMs to translate technical papers, retrieve publicly available information on multiple intelligence agencies and regional threat actors, resolve coding errors, and find concealment tactics to evade detection
Microsoft said it's also formulating a set of principles to mitigate the risks posed by the malicious use of AI tools and APIs by nation-state advanced persistent threats (APTs), advanced persistent manipulators (APMs), and cybercriminal syndicates and conceive effective guardrails and safety mechanisms around its models.
"These principles include identification and action against malicious threat actors' use notification to other AI service providers, collaboration with other stakeholders, and transparency," Redmond said.
Italian Data Protection Watchdog Accuses ChatGPT of Privacy Violations
31.1.24 AI The Hacker News
Italy's data protection authority (DPA) has notified ChatGPT-maker OpenAI of supposedly violating privacy laws in the region.
"The available evidence pointed to the existence of breaches of the provisions contained in the E.U. GDPR [General Data Protection Regulation]," the Garante per la protezione dei dati personali (aka the Garante) said in a statement on Monday.
It also said it will "take account of the work in progress within the ad-hoc task force set up by the European Data Protection Framework (EDPB) in its final determination on the case."
The development comes nearly 10 months after the watchdog imposed a temporary ban on ChatGPT in the country, weeks after which OpenAI announced a number of privacy controls, including an opt-out form to remove one's personal data from being processed by the large language model (LLM). Access to the tool was subsequently reinstated in late April 2023.
The Italian DPA said the latest findings, which have not been publicly disclosed, are the result of a multi-month investigation that was initiated at the same time. OpenAI has been given 30 days to respond to the allegations.
BBC reported that the transgressions are related to collecting personal data and age protections. OpenAI, in its help page, says that "ChatGPT is not meant for children under 13, and we require that children ages 13 to 18 obtain parental consent before using ChatGPT."
But there are also concerns that sensitive information could be exposed as well as younger users may be exposed to inappropriate content generated by the chatbot.
Indeed, Ars Technica reported this week that ChatGPT is leaking private conversations that include login credentials and other personal details of unrelated users who are said to be employees of a pharmacy prescription drug portal.
Then in September 2023, Google's Bard chatbot was found to have a bug in the sharing feature that allowed private chats to be indexed by Google search, inadvertently exposing sensitive information that may have been shared in the conversations.
Generative artificial intelligence tools like ChatGPT, Bard, and Anthropic Claude rely on being fed large amounts of data from multiple sources on the internet.
In a statement shared with TechCrunch, OpenAI said its "practices align with GDPR and other privacy laws, and we take additional steps to protect people's data and privacy."
Apple Warns Against Proposed U.K. Law#
The development comes as Apple said it's "deeply concerned" about proposed amendments to the U.K. Investigatory Powers Act (IPA) could give the government unprecedented power to "secretly veto" privacy and security updates to its products and services.
"It's an unprecedented overreach by the government and, if enacted, the U.K. could attempt to secretly veto new user protections globally preventing us from ever offering them to customers," the tech giant told BBC.
The U.K. Home Office said adopting secure communications technologies, including end-to-end encryption, cannot come at the cost of public safety as well as protecting the nation from child sexual abusers and terrorists.
The changes are aimed at improving the intelligence services' ability to "respond with greater agility and speed to existing and emerging threats to national security."
Specifically, they require technology companies that field government data requests to notify the U.K. government of any technical changes that could affect their "existing lawful access capabilities."
"A key driver for this amendment is to give operational partners time to understand the change and adapt their investigative techniques where necessary, which may in some circumstances be all that is required to maintain lawful access," the government notes in a fact sheet, adding "it does not provide powers for the Secretary of State to approve or refuse technical changes."
Apple, in July 2023, said it would rather stop offering iMessage and FaceTime services in the U.K. than compromise on users' privacy and security.